

この記事はLan Vu、Hari Sivaraman、Uday Kurkure が共同執筆したブログの翻訳版です。
NVIDIA vGPU では、タイムスライス方式の vGPU プロファイル、あるいは MIG-with-vGPU(以下 MIG vGPU)プロファイルのいずれかを利用して、vSphere が複数の 仮想マシン(VM)で NVIDIA GPU を共有することが可能となっています。これら 2 つの vGPU モードは、GPU リソースを最大限に活用する GPU の共有方法について、柔軟な選択肢を提供するものです。選択肢が 2 つあるため、vGPU と MIG vGPU のどちらを選べばよいか迷われるかもしれません。本ブログでは、さまざまなワークロードを用いた 2 つのプロファイルのユースケースをいくつか簡単にご紹介します。また、ワークロードに最適なプロファイルを選択して、vGPU と MIG vGPU のメリットを最大限に活用する方法についてもご紹介します。さらに多くのワークロードで分析を実施したパフォーマンス調査結果の全容については、VMware のホワイトペーパーをご覧ください
機械学習ワークロードを用いて 1 GPU あたりの VM 数をスケーリングした場合の vGPU と MIG vGPU の比較
この実験では、vGPU または MIG vGPU プロファイルを用いて 1 つの A100 GPU を共有し、 VM 数を 1~7 でスケーリングしながら、バッチサイズを 2(トレーニングと推論)として同一の Mask R-CNN ワークロードを実行しました。このワークロードは軽量な機械学習(ML)ワークロードと考えられます。各シナリオで GPU とメモリを最大限に活用できるように、各テストケースに対して異なるプロファイル設定を使用しました。MIG vGPU は、特に同一 GPU を共有する VM の台数が増加した場合に、より優れたパフォーマンスを示しました(図 1)。Mask R-CNN では バッチサイズを 2 としたため、各 VM のトレーニング タスクでは、コンピュート リソースの使用率(CUDA コアの使用率)と GPU メモリの使用率(各 GPU の 容量40 GB に対して 5 GB 未満)が低くなっています。vGPU は、この実験では MIG vGPU ほどの成績を示しませんでしたが、1 GPU あたりの VM の密度が高くなる場合には、1 GPU あたり最大 10 台 の VM に対応できるため、1 GPU につき最大 7 台 の VM に対応可能な MIG vGPU と比べてメリットがあります。
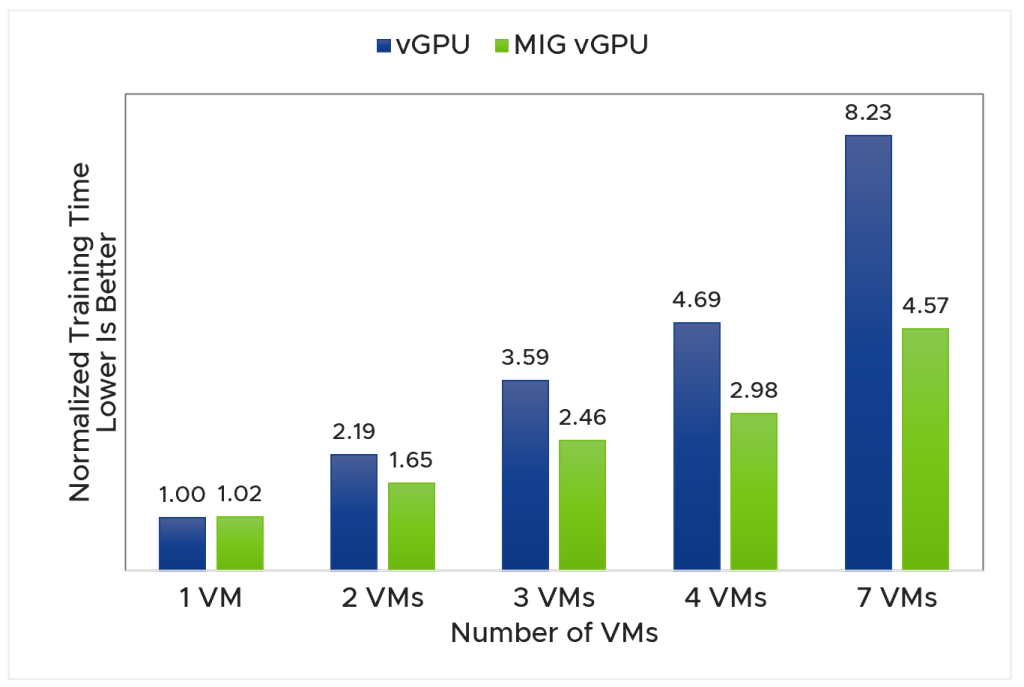
図 1:1 GPU あたりの VM 台数をスケーリングした場合の vGPU と MIG vGPUの正規化された機械学習トレーニング時間
機械学習ワークロードのサイズを変更した場合の vGPU と MIG vGPU の比較
本ケーススタディでは、機械学習ワークロードのサイズを変更した場合の機械学習のパフォーマンスを検討します。実験では、機械学習の負荷を再現する低・中・高の 3 種類のシナリオで、Mask R-CNN のトレーニングと推論を実施しました。図 2 にトレーニング時間を示します。各 VM で実行したワークロードの GPU コンピュートとメモリ リソースの使用率が低い場合、MIG vGPU の方がvGPU よりも良好なトレーニング時間とスループットを示しています。vGPU と MIG vGPU のパフォーマンスの差は、低負荷の場合に最大となっています。負荷が中程度の場合も MIG vGPU の方が良好ですが、vGPU と MIG vGPU とのパフォーマンスの差は小さくなっています。高負荷の場合は、わずかな差ではありますが、vGPU の方が MIG vGPU よりも優れたパフォーマンスを示しています。こうしたことから、ワークロードの特性が明らかであれば、アプリケーションに最適なオプションを選ぶことができます。ワークロードの特性が不明な場合は、vGPU と MIG vGPU を両方テストして、パフォーマンスの高い方を選ぶことをおすすめします。
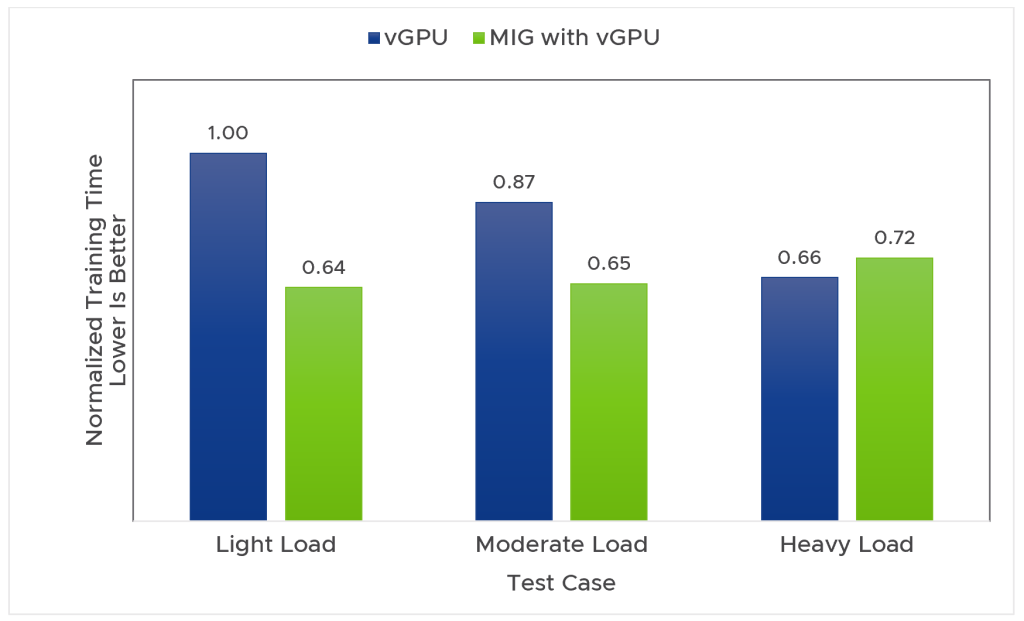
図 2:3 種類の GPU 負荷での vGPU と MIG vGPU の正規化された機械学習トレーニング時間
暗号化を使用するネットワーク機能など、高負荷の I/O 通信のワークロードでの vGPU と MIG vGPU の比較
この実験では、コンピュート負荷および I/O 負荷が高く、さまざまなワークロード特性を示す、インターネット プロトコル セキュリティ(IPSec)と呼ばれるネットワーク機能のワークロードを実行しました。CUDA を用いて CPU と GPU 間でデータをコピーし、CPU に対する計算処理をオフロードします。IPSec では、HMAC-SHA1 および CBC モードの AES-128 ビットを使用しました。今回の実験では、OpenSSL AES-128 ビット CBC 暗号化と復号のアルゴリズムを我々が CUDA を使って書き換えました [1]。図 3 の実験結果は、このシナリオでは vGPU の方が MIG vGPU よりパフォーマンスが優れていることを示しています。このワークロードはコンピュート負荷が高く、多くのCPU メモリ帯域幅を使用します。MIG vGPU の場合、このメモリ帯域幅は VM 間で分割されます。これに対し、vGPU は VM 間でメモリ帯域幅を共有します。本ユースケースにおける vGPU と MIG vGPU のパフォーマンスの差は、このことによって説明されます。したがって、ワークロード特性が不明の場合には、両プロファイルをテストして、パフォーマンスの高い方を選ぶのがよいということになります。
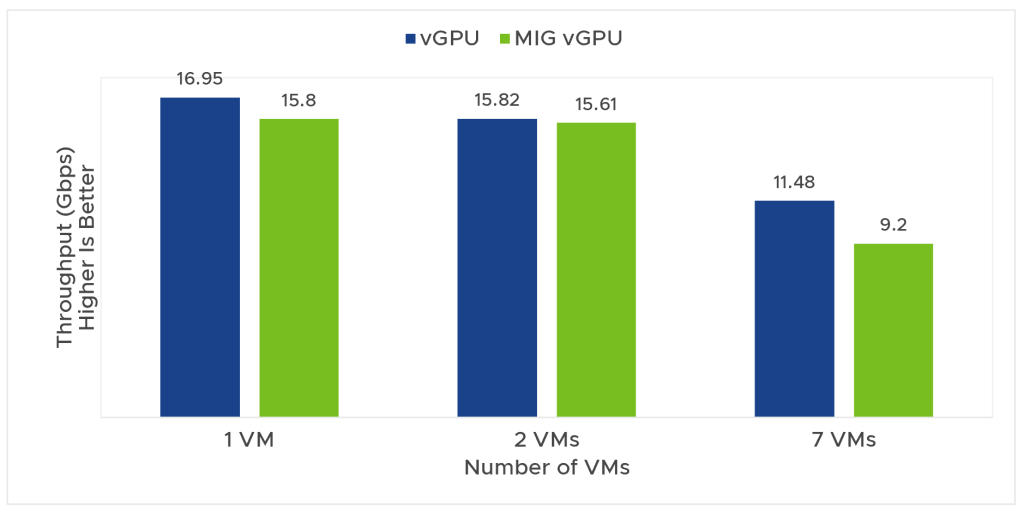
図 3:A100 で MIG vGPU プロファイルと vGPU プロファイルを使用した場合の 7 台の VM の IPSec スループット
まとめ
この実験では、複数のワークロードを実行して、vGPU と MIG vGPU のパフォーマンスを比較しました。実験結果の重要ポイントは以下のとおりです。
- ワークロードが軽量の場合(小規模モデル、バッチサイズが小さい、入力データが少ないなど)は、MIG vGPU を選択すると、1 GPU あたりの VM 数が向上し、よりよいパフォーマンスが得られます。これは機械学習/AI インフラストラクチャのコスト削減にもつながります。
- GPU を大量に使用するワークロード(大規模モデル、バッチサイズが大きい、インプットデータが多いなど)では、1 つの GPU を共有する VM 数が少なくなり、vGPU と MIG vGPU の差は比較的小さいとはいえ、vGPU がわずかに優れたパフォーマンスを示しました。
- NFV のようなコンピュート負荷および I/O 負荷の高いワークロードでは、多くのテストケースで vGPU の方が MIG vGPU よりも優れた結果を示しました。
謝辞
著者一同、NVIDIA の Charlie Huang 氏、Manvendar Rawat 氏、Andy Currid 氏へ、ホワイトペーパーのレビュー、情報提供に感謝申し上げます。また Juan Garcia-Rovetta 氏、Tony Lin 氏には、調査へのご協力に感謝申し上げます。




