

VMware が提供する NSX Advanced Load Balancer は、SDN アーキテクチャのメリットを活かした拡張性や自動化、可視化に優れたソフトウェア型ロードバランサーです。従来のハードウェアアプライアンス型ロードバランサーに比べ、サービス提供の迅速化や運用の効率化、TCO の削減が可能です。一方、ソフトウェア・仮想化という世界で動くロードバランサーでは、ハードウェアアプライアンスとは異なる視点が必要になります。本ブログでは、NSX Advanced Load Balancer の性能を最大限引き上げるためのデザインやチューニングのベストプラクティスをご紹介いたします。
NSX Advanced Load Balancer のアーキテクチャ
NSX Advanced Load Balancer はコントロールプレーンとデータプレーンが完全に分離したアーキテクチャを採用しています。コントロールプレーンの役割を担う Controller は統合管理や分析可視化、オーケストレータとしての機能を提供します。一方、データプレーンの役割を担う Service Engine はロードバランサーの実体として、サーバ負荷分散や GSLB、WAF などの機能を提供します。本ブログでは、この Service Engine の性能を最大化するための方法について考えていきたいと思います。

ロードバランサーの冗長化方式
NSX Advanced Load Balancer では3種類の冗長化方式をサポートしています。冗長化方式の違いによって、可用性のみならずパフォーマンスや耐障害性、ライセンスコストにも影響するため、導入するシステムやサービスの特性に合わせて検討する必要があります。
Active – Standby 構成
同じVIPを2台の Service Engine に、それぞれ Active/Standby として動作させる冗長化方式です。 正常時は Active の VIP がロードバランスを処理し、障害時は Standby の VIP に切り替わり、ロードバランスの処理が引き継がれます。

Active – Active 構成
同じ VIP を2台以上の Service Engine に、すべて Active として動作させる冗長化方式です。正常時は2台以上の Service Engine 上で動作する Active の VIP がロードバランスを処理し、障害時は残りの Service Engine 上で動作する Active の VIP がロードバランス処理を継続します。同じ VIP が Active として動作する Service Engine 数によっては、障害時に一時的な縮退運用になる可能性があります。以下の図は、全体で2vCPU の性能が必要なサービスにおける障害時の縮退有無についての構成例です。
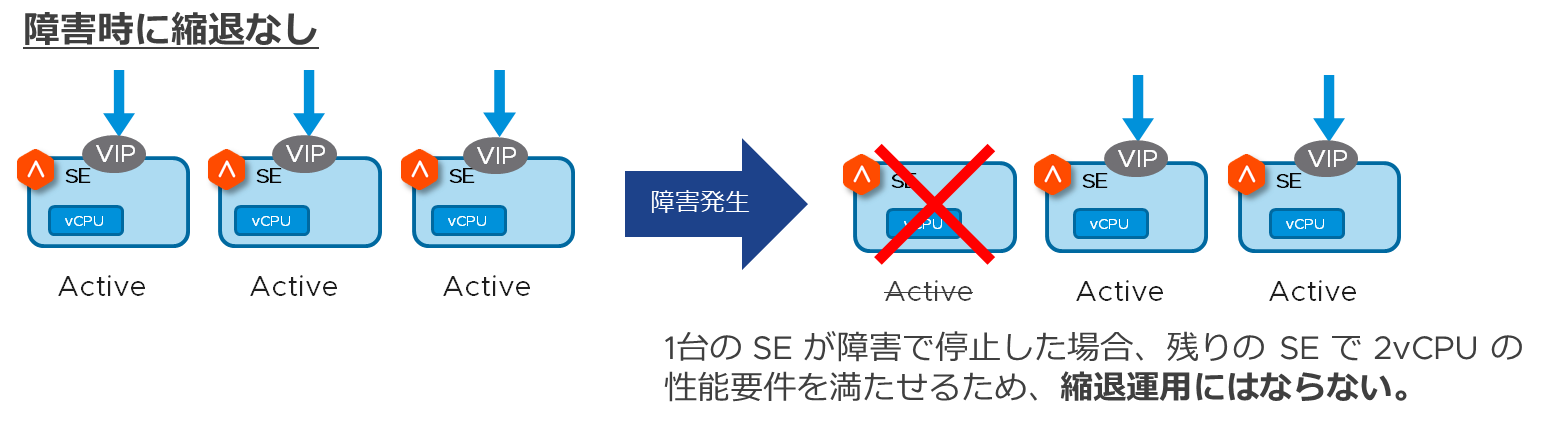

N+M 構成
同じ VIP を1台以上の Service Engine に、すべて Active として動作させる冗長化方式です。N+M の“M”は Service Engine のバッファ数を表します。別の言い方をすると、何台の Service Engine 障害まで耐えられるかを表しています。たとえば、M = 1の場合、1台の Service Engine 障害までなら、VIP は別の Service Engine にフェイルオーバーできるため、ロードバランス処理が継続できることになります。


N+M構成では、基本的に同じVIPは1台のService EngineにActiveとして展開されます。ただし、VIPをスケールアウトさせることで、同じVIPを2台以上のService EngineにすべてActiveとして拡張することができます。従って、スモールスタートで始められて、後からVIP単位で柔軟に拡張できることがN+Mの大きなメリットです。
各冗長化方式の違いを以下の表にまとめてみました。

※N+M構成は、同じ VIP を1台の Service Engine にのみ展開した場合の比較です。同じ VIP を2台以上の Service Engine にスケールアウトさせることで実質的に Active-Active 構成にすることも可能です。
なお、NSX Advanced Load Balancer の一部機能は Active-Standby 構成でしかサポートされないため注意が必要です。代表的な機能を以下に示します。冗長化方式を決定する際、ロードバランサーの機能要件を事前に確認しておくことをおすすめします。
- Preserve Client IP:リクエストをサーバに転送する際、クライアントのIPアドレスをそのまま保持する機能
- NAT Policy:サーバ発の通信に対するSNATの機能
- IP Routing:パケットのルーティング機能
- Wildcard VIP:ファイアウォール等の負荷分散機能
- Layer 4 Connection Mirroring:L4コネクションを同期する機能
- VIP as SNAT: SNATやヘルスモニタの送信元IPとしてVIPを使用する機能
スケールアップとスケールアウト
NSX Advanced Load Balancer のパフォーマンスは、Service Engine に割り当てる vCPU 数と Active として動作する Service Engine 数によって変化します。
スケールアップの考え方
Service Engine に割り当てる vCPU 数を増やすことで、性能を拡張する方法がスケールアップです。ただし、vCPU 数を2個、4個に増やしたところで、性能は単純に2倍、4倍にはならないため注意が必要です。スケールアップの方法では、いくつかボトルネックになり得る箇所が存在するため、スケールアップの性能拡張には限界があります。詳細は別セクションで説明します。

弊社では1vCPU/2vCPU/4vCPU/6vCPU ごとの性能指標を公開しております。ぜひ、サイジングの参考にしていただければと思います。
NSX Advanced Load Balancer Performance Datasheet
スケールアウトの考え方
Service Engine のデプロイ数を増やすことで性能を拡張する方法がスケールアウトです。スケールアップのボトルネックを回避できるため、スケールアウトのほうが効率的かつ効果的に性能を拡張することが可能です。ただし、スケールアウト方式によっては、ボトルネックになり得る箇所が存在するため、注意が必要です。詳細は別セクションで説明します。

性能のボトルネックになり得る箇所とは(スケールアップ編)
スケールアップで性能を拡張するアプローチでは、CPU と PPS が主なボトルネック箇所です。同時コネクション数が多いトラフィックパターンではメモリもボトルネックになり得ますが、シチュエーションが限られるため今回は CPU と PPS に焦点を当てて説明します。
CPU
Service Engine に割り当てる vCPU は、Dispatcher Core または Proxy Core もしくはその両方としての役割を担います。仮に Dispatcher Core の処理能力が限界に達している状況では、Proxy Core として動作する vCPU 数を増やしたところで性能向上は期待できません。

Service Engine の CPU 使用率は以下の方法で確認できます。コントローラへログイン後、 [インフラストラクチャ] > [クラウドリソース] > [サービスエンジン] に移動し、該当の Service Engine を選択して統計情報を表示させます。
なお、Dispatcher Core/Proxy Core ごとの CPU 使用率を確認するためには、CLI または API で確認する必要があります。コントローラへ SSH ログイン後、「shell」と入力し、 「show serviceengine <Service Engineの名前> cpu 」 コマンドを実行します。

PPS (Packets Per Second)
ハイパーバイザの種類やバージョンによって、サポートされている PPS の性能が異なります。たとえば、vSphere/ESX 6.x では、仮想マシンに対しておおよそ1.2M PPS がサポートされています。仮にパケットサイズが1,000Bytes で計算した場合、スループットは (1000 x 1,200,000)x8=9,600,000,000bps (9.6Gbps) が理論的な限界値になります。VCF9 では EDP Standard のネットワークスタックが標準採用されており、仮想マシンでおおよそ5.5M PPS の処理が可能という測定結果が出ています。

PPS は以下の GUI 画面で確認できます。コントローラへログイン後、 [インフラストラクチャ] > [クラウドリソース] > [サービスエンジン] に移動し、該当の Service Engine を選択して統計情報を表示させます。

性能のボトルネックになり得る箇所とは(スケールアウト編)
スケールアウトで性能を拡張するアプローチとして、L2 (Native) スケールアウトまたは L3 (ECMP) スケールアウトを選択できます。それぞれの動作概要についてはこちらのブログをご参照ください。L2 (Native) スケールアウトでは、Service Engine の台数に比例して性能はリニアに上昇しないので注意が必要です。一方、L3 (ECMP) スケールアウトでは、性能は比較的リニアに上昇する傾向があります。
L2 (Native) スケールアウト
Primary SE の CPU や PPS がボトルネックになる可能性のあるケールアウト方式です。同じ VIP で最大4台 までのスケールアウトがサポートされています。

L3 (ECMP) スケールアウト
基本的にはボトルネックが発生しにくいスケールアウト方式です。ECMP ルータの仕様にもよりますが、同じ VIP で最大64台 までのスケールアウトがサポートされています。

パフォーマンス チューニング
NSX Advanced Load Balancer では、CPU と PPS、メモリが性能のボトルネックになり得ることをお伝えしました。ボトルネックを回避するためのチューニング方法は様々ですが、Active-Active 構成を基本とするスケールアウトで性能を拡張する方法が最も効率的かつ効果的であると考えます。本セクションでは、性能向上が期待できるチューニングポイントを基本編と応用編に分けてまとめてみました。基本編のチューニングで性能が改善されない場合、応用編も検討していただければと思います。
基本編
Service Engine Group
- 冗長化方式を Active-Active で構成

- CPU とメモリを予約

- vCPU を Dispatcher Core 専用に設定 ※3vCPU 以上割り当てる場合のみ
![]()
vSphere/vCenter
- Service Engine VM の CPU limit を“unlimited”に設定
>SSL/TLS, TCP, HTTP, WAF…
- SSL/TLS の証明書と暗号スイートは RSA よりも ECC(楕円曲線)を設定
- SSL Session Reuse を有効化 ※デフォルト有効
- Connection Multiplexing を有効化 ※デフォルト有効
- TCPパラメータ(Window Scaling Factor, Receive Window等)をチューニング
- ポリシー制御は Data Scripts よりも L4/L7 HTTP Policy を設定
- 圧縮機能を利用する場合はキャッシュ機能も併用
- WAFでは、シグネチャ検査だけでなく、許可リストとポジティブセキュリティも併用
応用編
- RSS (Receive Side Scaling) を有効化する
NIC ごとに複数のキューと Dispatcher Core を割り当てるための機能です。同じフローに属するパケットは同じキューに入り、複数の Dispatcher Core が分散してパケットを効率よく処理することができます。特に PPS の性能向上が期待できるチューニングです。

- TSO (TCP Segmentation Offload) を有効化する
CPU で送信データをセグメント化するのではなく、TSO 対応 NIC に処理を肩代わりさせることで、CPU 負荷を軽減できます。 ※デフォルト有効

- GRO (Generic Receive Offload) を有効化する
同じフローに属する複数の受信パケットを結合し、より大きなパケットの塊を上位ネットワークスタックに渡すことで、CPU で処理すべきパケット数を減らせるため、CPU 負荷を軽減できます。 ※デフォルト無効

- Service Engine Datapath Isolationを有効化する
Service Engine に割り当てる CPU コアにおいて、コントロールプレーン処理とデータパス処理で CPU コアを完全に分離させるための機能です。1つまたは複数の CPU コアをコントロールプレーン処理専用に割り当て、残りの CPU コアはデータパス処理に専念させます。特に遅延やジッタに敏感なアプリケーションに対して遅延の低減が期待できるチューニングです。ただし、データパス処理用に割り当てられる CPU コア数が減るため、L4/L7 ロードバランスの処理能力に影響がでます。 ※デフォルト無効


- Hybrid RSS Mode を有効化する
Service Engine に割り当てる CPU コアのパケット処理を最適化するための機能です。すべてのCPU コアに対して、Dispatcher Core と Proxy Core の両方を同時に処理できるようにし、CPU コア間のパケットのディスパッチ(例:vCPU0 の Dispatcher-0 → vCPU1 の Proxy-1)による非効率な処理を回避できます。RSS が設定された DPDK モードでのみ動作します。 ※デフォルト無効

参考ドキュメント:Recommendation for better performance of Avi Service Engines
まとめ
今回のブログは主に vSphere 環境で NSX Advanced Load Balancer をデプロイしたときのパフォーマンスチューニングについて説明しました。スケールアップとスケールアウトの両方を取り入れることで、圧倒的なパフォーマンスとスケーラビリティの向上が期待できます。Google や Facebook などの Web Giant がロードバランサーをハードウェアアプライアンスではなく、ソフトウェアで実現している理由はそこにあると思います。
~ NSX ALB 関連ブログ ~
〜お知らせ〜
※VMwareでは、各種製品をクラウド上でご評価いただくHands-on Labs(HOL) という仕組みを無償でご提供しています。
今回ご紹介した各種ソリューションへの最初の一歩の入り口としてぜひご活用ください。
おすすめのHOLメニューはこちらから
- VMware NSX Advanced Load Balancer (Avi Networks) – Getting Started (HOL-2237-01-NET)
- VMware NSX Advanced Load Balancer (Avi Networks) – Global Server Load Balancing (HOL-2237-02-NET)
- VMware NSX Advanced Load Balancer (Avi Networks) Web Application Security (HOL-2237-03-NET)
- VMware NSX Advanced Load Balancer (Avi Networks) with Kubernetes (HOL-2237-04-NET)
- VMware NSX Advanced Load Balancer (Avi Networks) Lightning Lab (HOL-2237-91-ISM)



