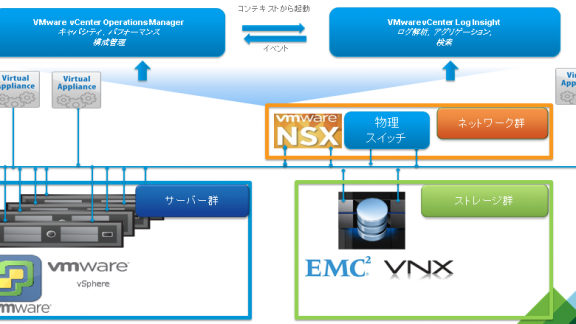

こんにちは。VMware の内野です。
本日は 6 月 11 日 ~ 13 日に幕張メッセで開催された Interop Tokyo 2014 の VMware ブース内の マネージメントコーナーの内容をご紹介します。
マネージメントコーナーでは、サーバーはもちろん、ストレージやネットワークまでも含めていかに一括で効率的に運用管理が行えるか。に関してお客様からよく頂くご質問に対する解決策を多くご紹介させていただきました。
Interop Tokyo 2014 の VMware ブースマネージメントコーナーでは、以下の様な環境を準備しました。
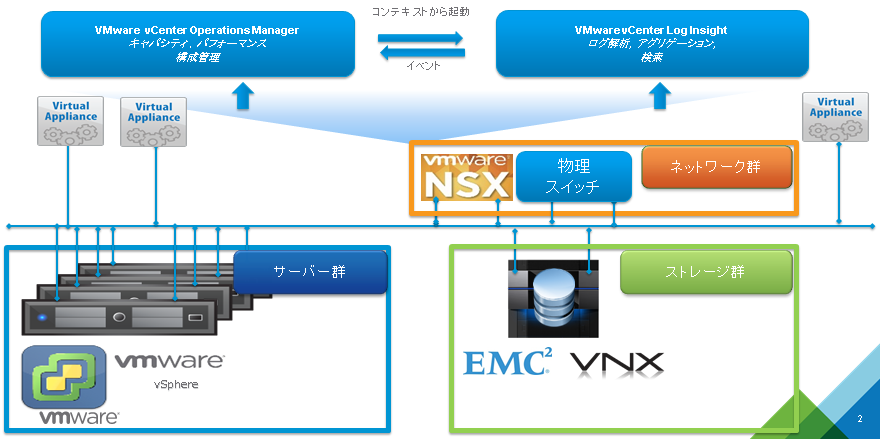
今回は上記の環境を使って、VMware vCenter Operations (以下、Operations Manager) や VMware vCenter Log Insight (以下、Log Insight) が多くのお客様で共通される課題をいかに解決できるかに関して実際の画面 (動画) も含めて、ご紹介させて頂きます。
課題 1. 現状の仮想環境にあと何台仮想マシンを追加できますか。
仮想化環境のメリットをより多く受けるためには 1 台のサーバーにより多くの仮想マシンを起動させたいと皆さんが思っております。
しかし、同時に仮想化環境に多すぎる仮想マシンを起動してしまうと、
- “性能が劣化してしまうのではないか心配”
- “ピーク時に十分な性能が出ることを保証したい”
等の理由で統合率を上げることに躊躇しているのではないでしょうか。
その様な時には Operations Manager を使って、最適な統合率を確認することが可能です。Operations Manager を利用することにより今まで今までの経験則でのキャパシティ管理から脱却して、利用状況に即したキャパシティ管理を行えるようになります。
実際の画面に関しては下記のリンクをクリックして実際の Operations Manager の画面を動画で確認してください。なお、動画を再生する為には Quick Time が必要です。
動画:あと何台VMを載せられるか確認する
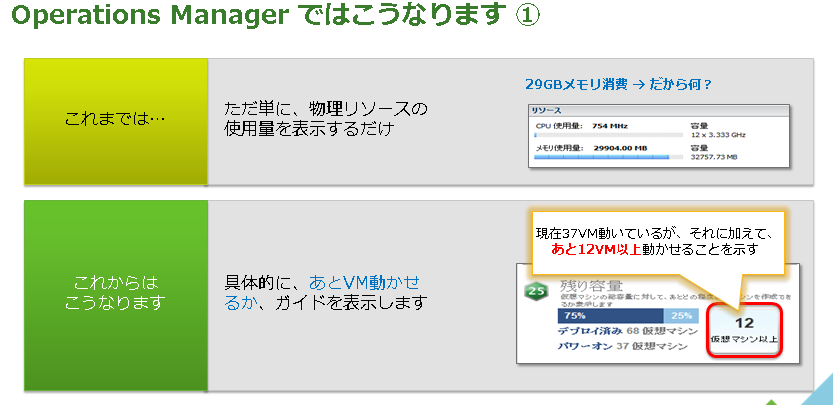
ご覧頂いた様に対象のクラスタを選択しただけで、残り何台の仮想マシンを乗せることができるかがすぐに確認することが可能です。今までは熟練の管理者が vCenter からパフォーマンスデータを取得して、Excel と格闘しながら、経験則で判断していたかと思いますが、これであれば、誰でも簡単に正確にキャパシティプランニングを行えます。
現在の利用状況のまま使い続けた場合、翌週・翌月・翌3ヵ月後の予測を行うことも可能ですので、いつの間にかリソースが足りなくなってしまったということは発生しません。また、ハードウェアを購入するためには上司や購買部門等に “なぜ、サーバー (ストレージ) が必要なのか” を説明する必要があると思いますが、この画面を使えば、上司や購買部門の方への説明もスムーズに行くのではないでしょうか。
仮想マシンを実際に追加した場合のシュミレーションも行うことができますので、実際に仮想マシンを追加する前にシュミレーションを行うことで “性能が劣化してしまうのではないか” という心配もしなくても大丈夫です。
それでは次の課題に進みます。
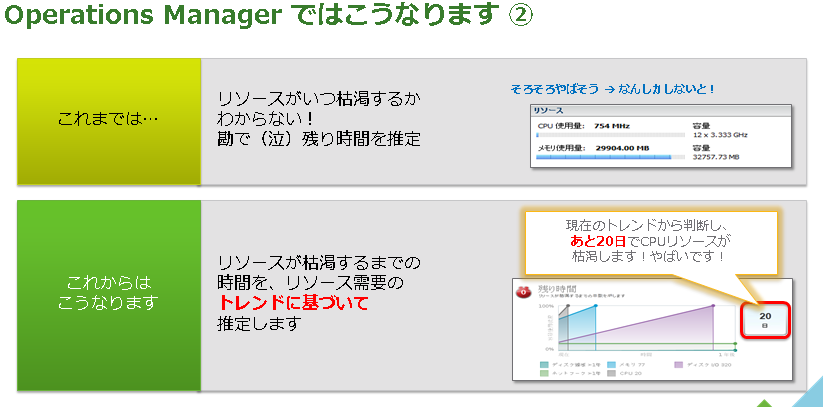
課題 2. いつ頃ハードウェアを追加すればいいですか?
仮想化環境を上手く使いこなせるようになるとハードウェアリソースの利用率がだんだん高くなってきます。統合率が高くなることによりハードウェアリソースが不足する場合も出てきます。
ハードウェアリソースの不足が発覚したタイミングでハードウェアを購入しようとしても上司や購買部門と調整した後、ハードウェアを注文して、到着まで待って、ラックマウントしてセットアップをして・・・・・と多くの作業を実施した後にハードウェアを利用することができます。
しかし、購買の手続きをしている最中もハードウェアリソースが不足している状況では、パフォーマンス低下が発生してしまう可能性がありますので、事前に “いつ頃ハードウェアが不足するのか” を事前に知らなくてはいけません。
今まではいつリソースが枯渇するかが明確ではなかったので、経験則や勘でハードウェアを追加していたのではないでしょうか。Operations Manager を利用することにより実際の運用で行われてきた実データの利用状況トレンドを基づいて、リソースの残り時間を推測することができます。
実際の画面に関しては下記のリンクをクリックして実際の Operations Manager の画面を動画で確認してください。なお、動画を再生する為には Quick Time が必要です。
動画:いつリソースが枯渇するか確認する
このように Operations Manager を利用することにより簡単に現在の利用状況のトレンドを考慮した上で現在のハードウェアリソースがあと何日 (何ヶ月/何年) 持つのかを CPU やメモリ、ディスクなどのコンポーネント単位で確認することが出来ます。
また、ハードウェアを追加した際にどの程度の利用期間が延びるのかなども簡単にシュミレーションすることができますので、仮想環境の正常性の確認以外にも、たとえば、ハードウェアを購入する際に サーバーを追加した時には 20 仮想マシンを追加できるけど、メモリだけ追加しても 20 仮想マシンの追加が可能になる。サーバーを購入するのではなく、メモリだけ増設して方が価格が安いからメモリだけ増設しよう。等の判断を明確に行えるようになります。
Operations Manager を使ってシュミレーションできる実例:
- サーバーやストレージを追加した際に何台の仮想マシンを起動できるかのシュミレーション
- CPU やメモリ等の増設をした時に何台の仮想マシンを起動できるかのシュミレーション
- 特定のサーバーやストレージを撤去した時に何台の仮想マシンを起動できるかのシュミレーション
- システムをリプレースする際のサイジングのシュミレーション
- 仮想マシンを追加・削除した際のシュミレーション
それでは次の課題に進みます。
課題 3.無駄にハイスペックな仮想マシンがたくさんいるんだけど・・・
仮想環境の管理をしているとリクエストされている仮想マシンのリソースが適切にリクエストされているか疑問に思うことはありませんか。
本当は 1CPU / 4 GB メモリあれば、十分なのに、4 CPU / 16GB メモリの申請をされるようなことは無いでしょうか。リクエストをしている人はパフォーマンスを担保する意味で、多めにリソースの申請をしてしまいやすい傾向があると思います。
そのようなリクエストが多数あると、せっかく仮想環境を構築して、リソースを効率的に使おうとしても非効率な状況が発生してしまいます。
今までは過剰に申請された仮想マシンを見つけ出す方法がありませんでした。Operations Manager を利用することにより簡単に過剰申請された仮想マシンを探し出すことができるようになります。
実際の画面に関しては下記のリンクをクリックして実際の Operations Manager の画面を動画で確認してください。なお、動画を再生する為には Quick Time が必要です。
動画:過剰割り当てVMを探す
このように簡単なオペレーションで過剰にリソースが割り当てられた仮想マシンを適正化して削減できた分で新規の仮想マシンを作成することができ、より効率的に仮想環境を利用することが可能です。
なお、私がお客様先に Operations Manager を評価してもらう為に導入したお客様の実績ベースでも 95% 以上の仮想マシンがオーバースペックなリソースが割り当てられていました。皆様の仮想環境でも少なくとも 90% 以上の仮想マシンがオーバースペックになっているのではないかと確信しています。オーバースペックの仮想マシンを最適化することにより新しい仮想マシンのリソースとして再利用することが出来るようになります。

それでは次の課題に進みます。
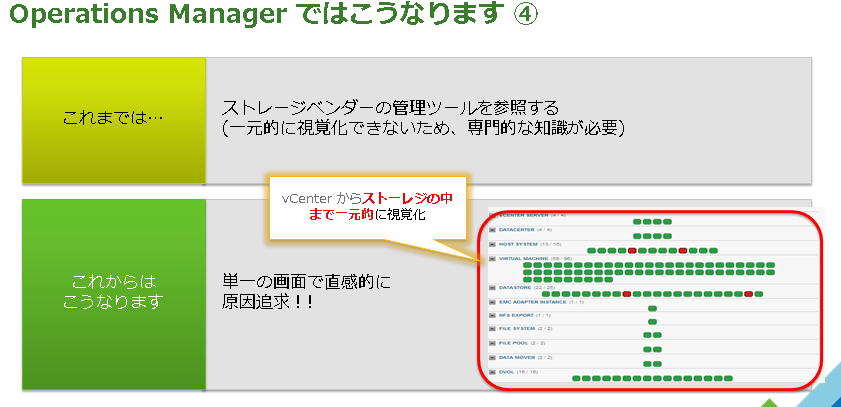
課題 4.仮想環境で使っているストレージのパフォーマンスが上がらないんだけど・・・
仮想環境でも物理環境でもパフォーマンスの問題が発生した時の調査というのは非常に難しいですよね。CPU・メモリ・ディスク・ネットワーク等、各コンポーネントの利用状況等を調べて、既存の環境を依存関係を把握した上で、原因を追究する必要があります。
そのため、どこにボトルネックがあるのか正確を特定できれば、パフォーマンス問題の半分は解決できたと考えてもいいでしょう。
中でも特にストレージのボトルネックを探し出して原因を究明することは非常に難しく、共有ストレージのボトルネックはシステム全体のパフォーマンス低下に直結します。
Operations Manager を利用すれば、vCenter から ESXi ホスト、仮想マシン、データストアーはもちろん、外部ストレージの中のコントローラーやディスク、キャッシュ等も含めて一元的に視覚化することができます。
実際の画面に関しては下記のリンクをクリックして実際の Operations Manager の画面を動画で確認してください。なお、動画を再生する為には Quick Time が必要です。
動画:VMが起動している外部ディスクの情報を確認する
仮想マシンが起動しているハードディスクがどれかを特定しようとすると色々なツールを駆使して、一つずつ確認をしていかないとどのハードディスク上で起動しているかを確認できないと思います。Operations Manager を使うと仮想マシンを選択するだけで、その仮想マシンが外部ストレージの中のコントローラやキャッシュ、ディスクのどれを使っているかを瞬時に判断することが出来るようになります。
なお、Interop Tokyo 2014 では EMC 様にご協力頂き、EMC VNX を設定させて頂きましたが、Operations Manager に対応しているストレージは下記の Solution Exchange というページから検索することができますので、現在ご利用のストレージで同じことができるか確認してみてください。
https://solutionexchange.vmware.com/store
それでは次の課題に進みます。
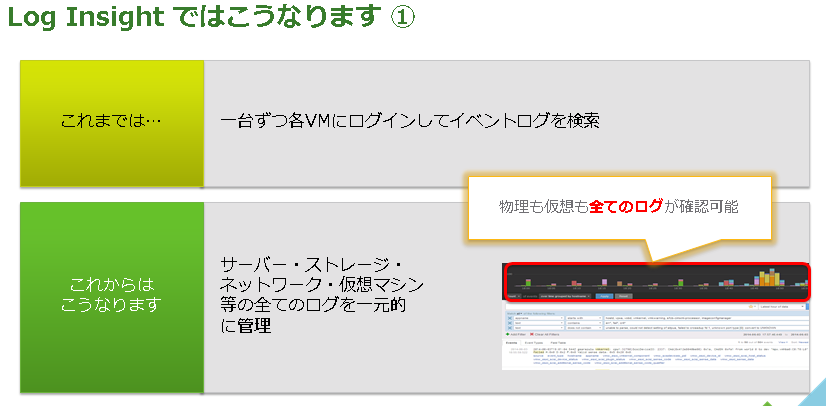
課題 5.管理する仮想マシンや物理的な機器が増えすぎてログを確認できないんだけど・・・
仮想環境でも物理環境でも同様だと思いますが、皆様は Windows や Linux / ストレージ機器やネットワーク機器のログを確認しておりますでしょうか。
多くの方のログの確認する場合はトラブルが発生したやセキュリティを担保するためにログを確認することが多いのではないでしょうか。
ですが、ログの確認は当たり前ですが、各機器によって確認方法が違います。
- Windows : イベントログから確認
- Linux : /var/log/messages のログファイルを確認
- ストレージ機器 : ストレージ管理ソフトから確認 (各スベンダーにより確認方法が異なる)
- ネットワーク機器 : show logging コマンド等でログを確認
Linux であれば、/var/log/messages の中を grep 等のコマンドを駆使して、目的のログを探すのは経験が必要な作業なのではないでしょうか。
また、例えば、100 台の Windows と 100 台の Linux を管理しているのであれば、合計 200 台に対して、リモートデスクトップや ssh でログインして、1 台ずつ確認していたら、それだけで 1 日が終わってしまいますよね。
そのような場合には Log Insight を利用すれば、一箇所で集中して管理することができるようになります。
実際の画面に関しては下記のリンクをクリックして実際の Log Insight を動画で確認してください。なお、動画を再生する為には Quick Time が必要です。
動画:LogInsightでログを検索する
このように Log Insight は多くの機器のログを一括集中で管理することができます。
“syslog サーバーと何が違うの?” という疑問もあるかと思いますが、syslog サーバー上で大量のログメッセージを grep 等のコマンドで検索すると非常に時間がかかると思います。Log Insight を使えば、大量のログメッセージを高速に検索することが出来ます。
また、Log Insight 2.0 から Windows エージェントが Log Insight に追加されておりますので、Windows サーバーや端末のログを集中管理を行うことが出来ます。
ログのフィルタリングや集計機能を使えば、トラブル時に原因のログを探したり、日々のログデータのトレンドを把握することも簡単に行えるようになると思います。また、アラーと設定を行い、例えば、”ログイン失敗のエラーメッセージが発生したら、メールを送る” 等の設定も可能ですので、セキュリティを担保するという意味でも非常に効果があると思います。
それでは次の課題に進みます。
課題 6.NSX も一緒に Operations Manager で管理したい。
Interop Tokyo は皆さんもご存知の通り、ネットワークのイベントです。VMware の中ではネットワーク仮想化ということで NSX を出展させて頂きました。その NSX も今までご紹介してきた Operations Manager を使って参照することが可能です。
管理ツールが複数存在すると、その分、運用のオペレーションが増えたり複雑になったりします。全ての管理を OPerations Manager に統一することにより運用をよりスリムに行うことが可能です。
実際の画面に関しては下記のリンクをクリックして実際の Operations Manager の画面を動画で確認してください。なお、動画を再生する為には Quick Time が必要です。
動画:NSXをOperations Managerで視覚化する
なお、NSX アダプタは 2014 年 6 月現在、テクニカルプレビューというステータスになっておりますので、正式なリリースまでもう少しお待ちください。

いかがでしたでしょうか。
Operations Manager / Log Insight が既存の運用をどの様に効率的になるかをご理解頂ければ幸いです。本ブログを興味を持って頂いたら、皆様の環境でもぜひ、Operations Manager / Log Insight をまずはお気軽にお試し頂ければと思います。
まとめ:
Operations Manager / Log Insight は導入コストを削減する製品ではなく、運用コストを削減することを目的とした製品です。現在、多くのお客様環境ではより少人数で多くのシステムをより高い品質で運用することが求められています。
導入コストは製品を購入するというはっきりした支出がありますので、導入コストばかりが注目されてしまいますが、導入コストだけでは全体的な IT コスト削減は望めません。むしろ、システム全体の費用で考えた時には導入コストよりも運用コストの方が大きく、本当に改善しなくてはいけないのは、導入コストではなくて運用コストなのです。
Operations Manager / Log Insight という運用管理ツールを使い、運用コストを圧縮して、全体的なコストを最適化していく必要があります。
執筆者:内野 賢二

Interop 2014 関連リンク
Interop Tokyo 2014 VMware SDDC におけるネットワーク&ストレージ仮想化、マネージメント 〜Best of Show Award への挑戦〜
Interop Tokyo 2014 自宅でNSX VMware Hands On LABS のご紹介
Interop Tokyo 2014 ブースの舞台裏
Interop Tokyo 2014 Software Defined Storage コーナー デモ環境構 築TIPS
Interop Tokyo 2014 Automation 01 – ネットワークサービスの展開及び設定の自動化
Interop Tokyo 2014 Automation 02 – 負荷に応じたWeb サーバの自動展開(オートスケール)
Interop Tokyo 2014 マネージメントコーナー紹介