

はじめに
皆さま、こんにちは。Broadcom の VCF-TAM 中山です。 前編の記事では、モダンアプリケーションの普及に伴い、インフラ担当者に求められる役割が「基盤 SRE (Site Reliability Engineering)」へと拡大している背景、そして VCF が提供する「VMware vSphere® Supervisor」(以降 Supervisor)というアーキテクチャの本質についてお話ししました。
「開発スピード」と「信頼性」を両立させるためには、プラットフォームの抽象化だけでなく、その中身を正確に把握する「可視性」が不可欠です。
後編となる今回は、VMware Cloud Foundation® Operations (以降 VCF Operations) を活用した Kubernetes 環境の具体的なモニタリング手法について解説します。ブラックボックス化しがちなコンテナ環境を、いかにして「クリアボックス」へと変えていくのか。実運用で注目するポイントを交えてご紹介します。
実際に VCF Operations を活用することで、Kubernetes 環境の監視はどのように変わるのでしょうか。その具体的な可視化のアプローチを見ていきましょう。
■目次
1. VCF Operations によるモニタリングの仕組み
2. KUBECONFIGファイルで簡単に設定
3. 「即戦力」のモニタリング
4. VCF Operations によるキャパシティ管理
5. 運用時のモニタリング基準
6. インフラとコンテナの境界線をなくす:「オブジェクト同士の関係性(トポロジー)の自動可視化」
7. まとめ:Kubernetes 運用のあるべき姿へ
1. VCF Operations によるモニタリングの仕組み
本記事では、Supervisor からプロビジョニングされた Kubernetes クラスターに焦点を当てます。
VCF Operations は、各 Node の kubelet(cAdvisor)と連携することで、Kubernetes 環境のメトリック情報をダイレクトに取得します。これにより、単なるインフラリソース(物理/仮想マシン)の監視にとどまらず、Node 、Pod、そして個々のコンテナにいたる各レイヤーのパフォーマンス情報を、複雑な設定なしに一元的に収集・可視化することが可能です。
概念図
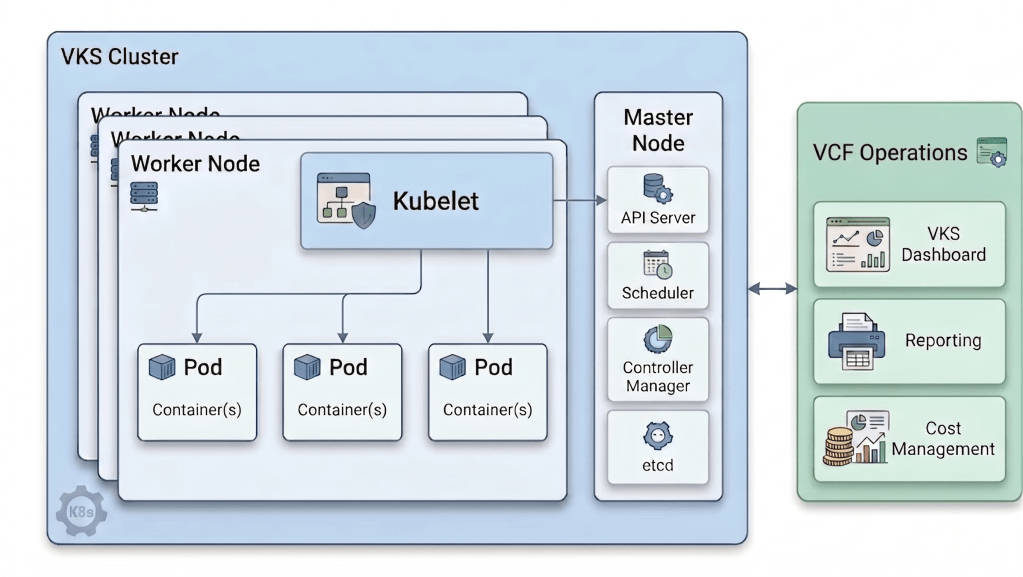
2. KUBECONFIG ファイルで簡単に設定
導入のハードルは驚くほど低いです。
具体的には、対象環境の kubeconfig から取得したコントロールプレーンの URL と証明書情報を、VCF Operations に入力するだけで連携が完了します。
この「手軽さ」こそが、スピードと効率性を求められる SRE 運用において、非常に重要な要素となります。
KUBECONFIGファイルを取得
kubeconfig で確認できた証明書情報をCredentialに指定
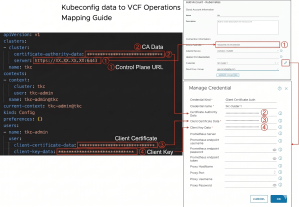
※ 詳細な資格情報の入力はこちらを参照してください。
3. 「即戦力」のモニタリング
VCF Operations には、Kubernetes 環境をモニタリングするために必要な「ダッシュボード」や「アラート定義」などが、「Management Pack for Kubernetes」と呼ばれる管理パックとしてあらかじめ一通り用意されています。
そのため、収集したメトリックを「どのようにダッシュボードで表現するか」といった画面設計や、監視項目の選定をゼロベースで検討する必要はありません。対象の Kubernetes クラスターを登録するだけで、すぐにベストプラクティスに基づいた高度なモニタリングを開始できることこそが、VCF Operations を活用する大きなメリットです。
ダッシュボード
アラートの一覧
4. VCF Operations によるキャパシティ管理
VCF Operations を利用して、Kubernetes クラスターのキャパシティを管理の観点から確認してみましょう。
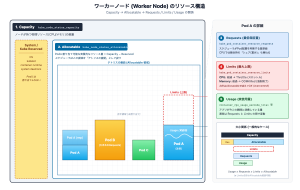
まずは前提知識として、Kubernetes クラスターを構成する「Worker Node」のリソースが、Pod によってどのように消費されるかを簡単に図解します。CPU とメモリでは細かな制御(スロットルや強制終了など)が異なりますが、ここではリソース管理の共通概念として、分かりやすく「テトリス」に例えて解説します。
土台となる「ハコ(Node)」の概念
Capacity(総容量)
概要: Node が物理的に持っている CPU やメモリの総量です。
ポイント: リソース全体の「一番外側の枠」として描かれる領域です。
System / Kube Reserved(システム予約領域)
概要: OSや kubelet、コンテナランタイムなど、Kubernetes システムが安定稼働するために確保される領域です。
ポイント: ここにはアプリケーション(Pod)は配置されません。
Allocatable(テトリスの盤面)
概要: Capacity からシステム予約領域を差し引いた、「Pod が実際に使える実質的な領域」です。
ポイント: Kubernetes のスケジューラは、この領域を「テトリスの盤面」に見立ててブロック(Pod)をどう配置するか計算します。
配置される「ブロック(Pod)」の3つの指標
各Pod(コンテナ)のリソースは、図の右側のように3つの指標で管理・監視されます。
Requests(最低保証量 / ブロックの大きさ)
コンテナが起動するために「最低限これだけは確保してほしい」と宣言するサイズです。テトリスの「落ちてくるブロックそのものの大きさ」にあたります。スケジューラは、この合計値が「盤面(Allocatable)」を超えないように配置します。
Limits(最大上限量 / 拡張できる壁)
コンテナが「これ以上リソースを消費してはいけない」という絶対的な上限です。テトリスの「ブロックが膨張できる最大の壁」です。全 Pod の Limits の合計は盤面の枠を超えて設定(オーバーコミット)できますが、実際の消費量がこのLimitsの壁にぶつかると、CPU ではスロットル(制限)、メモリでは OOMKilled(強制終了)が発生します。
Usage(実際の消費量 / ブロックの中の実負荷)
アプリケーションが「今この瞬間に、リアルタイムで消費している」リソースの実測値です。テトリスのブロックの中で「実際に色がついている領域」にあたります。常に上下に変動しており、通常は Requests と Limits の間で推移します。
大小関係のまとめ(一般ケース)
図の右下にあるバー図は、これらの指標の関係性を整理したものです。
Usage ≤ Requests ≤ Limits ≤ Allocatable
通常はこの関係性が保たれます。ただし、Requests を設定しない場合や、オーバーコミットにより Limits の合計が Allocatable を超過できるため、Requests ≤ Allocatable という基本的な関係性を意識することがキャパシティ管理の第一歩となります。
次に、Kubernetes Capacity ダッシュボードを見てみましょう
VCF Operations には、Kubernetes 環境のキャパシティを管理するための専用ダッシュボードが標準で用意されています。これを利用することで、クラスタ全体のリアルタイムな状況を一目で把握することが可能です。(※ ダッシュボード上の個々のウィジェットの詳細な定義については割愛いたします)
それでは、実際に Kubernetes Capacity ダッシュボードの画面を見ながら、インフラ担当者がまず着目すべき「Node CPU Capacity」の項目から解説していきましょう。
Kubernetes Capacity ダッシュボード

上記のグラフには、前述した Limit(青線)/ Requests(紫線)/ Usage(緑線) の値が時系列できれいにプロットされています。ここでは、該当の Node 内で起動している「すべてのPodの合計値」をまとめて確認することができます。
キャパシティ管理での注目ポイント ここで運用者が注意して確認すべきは、「Usage(実際の消費量)の緑線が、右肩上がりに急上昇していないか」、そして「Node のキャパシティ(許容量)に対してどれくらい余裕があるか」です。
グラフの後半(10:00 PM以降)で負荷がグッと上がっていますが、この緑線(Usage)が青線(Limit)や Node の限界に近づきすぎると、CPUのスロットリング(使用制限)が発生し、アプリケーションの処理が著しく遅くなるなどパフォーマンス低下のリスクが高まります。VCF Operationsを使えば、このように「計画値(Request/Limit)」と「実測値(Usage)」の乖離をひと目で監視できるのが大きなメリットです。
例えばこのグラフの時点では、実消費(Usage: 3.2)は、最低保証(Requests: 3.75)の中にまだ収まっているので、Node としては安全な状態だな、という判断ができます
(補足) CPU の枯渇はパフォーマンス低下を招きますが、メモリの枯渇は Pod の強制終了(OOM Kill)に直結します。そのため、VCF Operations では CPU だけでなく、同様の構成の「Memory Capacity」ダッシュボードもセットで監視することが鉄則です。
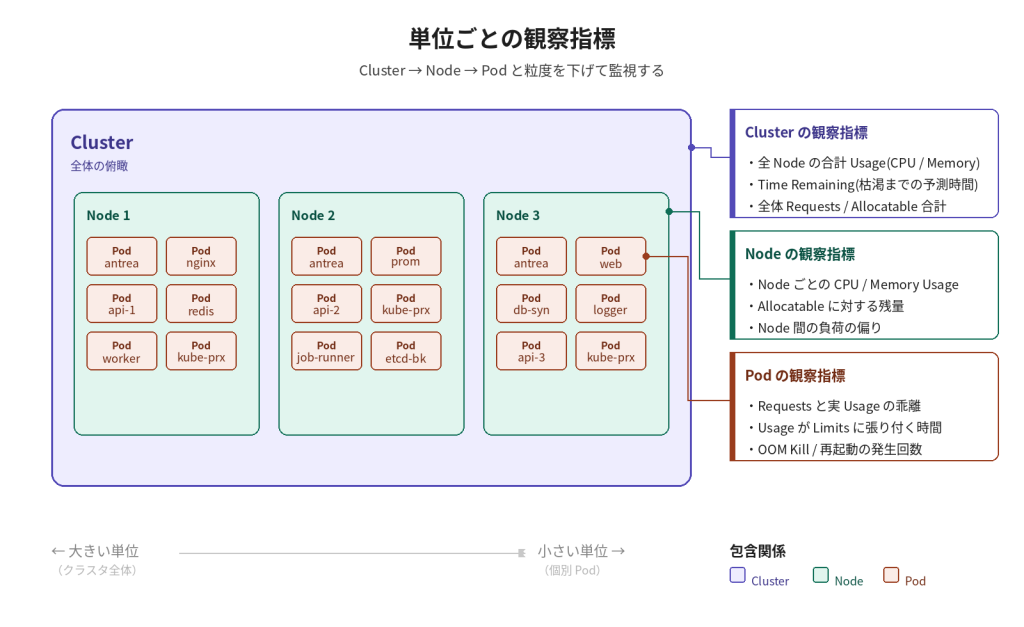
5. 運用時のモニタリング基準
実運用中には、これらを以下のようにレイヤごとに使い分け、「トラブルの事前回避」と「コストの最適化(無駄遣いの削減)」に役立てられます。
・Cluster 単位:全体の投資対効果と拡張計画
クラスタ全体の合計リソース(全 Node の総和)を俯瞰して見ます。
リソースの最適化(ライトサイジング): クラスタ全体の Usage が常に30%以下であれば、「Node の台数を減らせる(コスト削減できる)」と判断できます。
キャパシティ予測(将来計画): 「現在のペースでPodが増え続けると、あと何ヶ月でクラスタのリソースが限界(枯渇)を迎えるか」をVCF Operationsの予測機能(Time Remaining / Capacity Remaining)を使って可視化し、プロアクティブに Node の追加を計画できます。
・Node 単位:リソース競合の監視
特定の Node に Pod 同士のリソース競合が発生していないか、テトリスの盤面(Allocatable)にどれくらい余裕があるかを確認します。
アンバランスの解消: 特定の Node だけUsageが突出し、他の Node がガラガラという状態(スケジューリングの偏り)を検知し、Pod の再配置(Eviction / リバランス)などの判断材料にします。
・Pod 単位:設定値の答え合わせ
開発者が設定した「Requests / Limits」が適切かどうかを答え合わせします。
無駄の発見: Requests(最低保証)を大きく設定しすぎているのに、Usage(実消費)がずっと低いままの「もったいないPod」を見つけます。
リスクの検知: Usage が常に Limits(上限)に張り付いており、CPUであればスロットリング(使用制限)によるパフォーマンス低下、メモリであればOOM Kill(強制終了)がいつ発生してもおかしくない「危険な Pod」を早期に発見します。
Kubernetes の運用でありがちな、「原因不明の Pod 停止」や「インフラ費用の高騰」は、大半がこのリソース設定の不一致から生まれます。VCF Operations を使って、Pod から Cluster まで各レイヤでのキャパシティ分析することで、ブラックボックスになりがちなコンテナ環境のリソース状況を「クリアボックス」化し、「攻め(コスト削減)」と「守り(安定運用)」を両立した一歩進んだ Kubernetes 運用が実現できるようになります。
6. インフラとコンテナの境界線をなくす:「オブジェクト同士の関係性(トポロジー)の自動可視化」
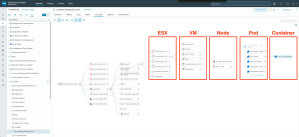
VCF Operations の最も強力なメリットの一つが、この「オブジェクト同士の関係性(トポロジー)の自動可視化」です。インフラ層からアプリケーション層にいたるまでの繋がりを、システムが自動的にマッピングしてくれます。
特に、仮想マシン(VM)上で Kubernetes を動かす環境において、インフラ担当者の「痒い所に手が届く」のがこの機能です。
これまでは、「この Kubernetes Node(VM)の上で、いまどの Pod が動いているか?」を調べるために、わざわざ kubectl コマンドを叩いて調査する必要がありました。しかし VCF Operations を使えば、外部から見えにくいオブジェクト同士の関係が一目で分かります。さらに、特定のオブジェクトにアラートが出ていれば、その可視化画面からシームレスにドリルダウンして原因を深掘りすることが可能です。
例えば、アプリ開発者から「Pod の挙動が重い」という問い合わせがあった場合、従来はコンテナ内部のログやプロセスばかりを調査しがちでした。しかし VCF Operations があれば、インフラ側の指標(CPU Ready Time など)と Pod の状況を即座に突き合わせることができます。「アプリのバグではなく、実は物理Host 側での CPU 競合が原因だった」といった、インフラとコンテナのレイヤーを跨いだトラブルシューティングが瞬時に完了します。
文字通り、インフラとコンテナの境界線を無くす VCF Operations のトポロジー画面が、どのようなものか見てみましょう。
オブジェクト同士の関係性(トポロジー)の自動可視化
この関係性(トポロジー)の可視化によって、実運用におけるトラブルシューティングがどのように変わるのか、2つの具体的なケースを見てみましょう。
・ケース1(CPU競合):インフラ視点での原因特定
事象: アプリ開発者から「特定の Pod の動きが急に遅くなった」と連絡が入る。
原因特定: トポロジー画面を確認すると、該当の Pod が動いている Kubernetes Node(VM)の背後で、インフラ側の CPU Ready Time(CPUレディ時間)が高騰しているのを発見。原因は Pod 自体ではなく、同じ物理Hostに同居する「別の重い仮想マシン」と物理 CPU を奪い合っていたことだと、インフラ視点から即座に突き止められました。
・ケース2(ストレージ遅延):深いレイヤーまでのインフラ追跡
事象: データベースを動かしている Pod でレスポンスの遅延が発生。
原因特定: 関係性の「線」を上位から下位へと辿っていくと、Pod ➔ Kubernetes Node(VM)➔ 物理Host ➔ そしてその先にある物理データストア(ストレージ)の遅延が根本原因であることを特定。コンテナ層のメトリックだけでは絶対に辿り着けない、最下層のインフラのボトルネックを瞬時に可視化できました。
コンテナ環境でありがちな「インフラ層のブラックボックス化」を完全に解消し、物理ストレージから最上部の Pod までをひと繋ぎの「クリアボックス(透明)」にする。これこそが、VCF Operations がもたらす最大の運用価値であり、基盤 SRE を目指すインフラ担当者にとっての最大の武器になります。
7. まとめ:Kubernetes 運用のあるべき姿へ
前後編にわたり、「基盤 SRE」への変革と、それを支える VCF Operationsの機能について解説してきました。私たちが目指すべきKubernetes 環境の運用は、以下の 3 点に集約されます。
・「ブラックボックス」から「クリアボックス」へ
Pod から物理インフラ層までを透過的に追跡し、運用の透明性を確保する。
・運用チームの「共通言語」を持つ
インフラチームと開発チームが VCF Operations という共通のダッシュボードを見て、事実に基づいた建設的な会話を行う。
・「プロアクティブ(事前対応)」な運用へ
AI/ML ベースの予兆検知により、障害が起きる前にキャパシティやリスクを把握する。
TAM からのメッセージ
ツールは導入して終わりではありません。収集した膨大なデータをどう分析し、日々の運用改善(アラートの最適化、プロセス改善)に活かしていくかが、成熟度を左右します。私たち VMware TAM は、お客様の戦略的パートナーとして、この強力なプラットフォームの活用を長期的に伴走支援いたします。もし、「Kubernetes 運用がブラックボックス化している」「開発との溝が埋まらない」といったお悩みがありましたら、ぜひ担当 TAM までお気軽にお声がけください。
前後編、最後までお読みいただきありがとうございました。この記事が、皆さまの Kubernetes 運用改善の一助となれば幸いです。


