

はじめに
皆さま、こんにちは。Broadcom の VCF-TAM 中山です。平素は弊社製品に格別のご愛顧を賜り、誠にありがとうございます。
私は日頃、多くのお客様のシステム運用を最前線でサポートさせていただいています。その中で、この数年、インフラ現場の抱える「悩み」が大きく変化していることを痛感しております。かつては、システムの「安定稼働」や「障害対応」といった、インフラの信頼性維持が主要な課題でした。しかし、近年のデジタルトランスフォーメーション (DX) の加速に伴い、状況は一変しました。ビジネス部門からの「新機能の迅速なリリース」という要求が高まり、インフラ担当者にも、開発スピードの向上とサービスの信頼性担保という、実質的に Site Reliability Engineering (SRE) の役割が求められるようになりました。
特に、Kubernetes をはじめとするコンテナ技術の普及は、この難易度を飛躍的に上げています。私自身、お客様から「Kubernetes の複雑さに従来の運用体制では追いつかない」「アプリケーションとインフラの責任範囲の境界線が曖昧になった」といった、切実なお声を多数伺っています。
本記事は、こうした現場のインフラ担当者の皆様の課題に対し、Broadcom として、また私個人の経験に基づき、どのような解決のヒントやソリューションを提供できるかをまとめたものです。
■目次
1. インフラ担当者の方々の「悩み」とは
インフラ担当者の方々の「悩み」は一体何に起因するものでしょうか。VMware Cloud Foundation® (以降 VCF) や VMware vSphere® (以降 vSphere) といったプライベートクラウド基盤を運用するインフラ担当者の皆様は、開発部門から「Kubernetes を使いたい」という要求を受け、その基盤を提供・運用する機会が急激に増えているのではないでしょうか。従来の「VM を払い出して終わり」というタスクベースの責任範囲を超え、「払い出した VM 上で動作する Kubernetes クラスタ」、さらには「その上で動くアプリケーション(サービス)」全体の信頼性(Reliability)にまで責任が及びます。
これは、単なる技術スタックの変化ではなく、マインドセットと役割の転換を意味します。つまり、従来のインフラ担当者は、実質的に「基盤の SRE」の役割を担う必要に迫られています。インフラの安定性だけでなく、その上で動くサービスのビジネス的な継続性にも目を向ける必要が出てきたのです。
図1. インフラ担当者の役割が拡張
インフラ担当者が「基盤の SRE」としての役割を全うしようとするとき、大きな壁にぶつかります。それは、vSphere の世界(仮想マシン、ハイパーバイザー、データストア)と、開発者が使う Kubernetes の世界 (Pod, Namespace, Deployment) の間にある「監視の深い溝」です。私たち TAM がお客様から最も多く伺う悩みが、この点に集中しています。なぜ、これほどまでに運用が難しくなったのでしょうか。
システム構造の進化が生んだ「監視の深い溝」
モノリシックからマイクロサービスへの移行により、管理リソース(Pod, Service, Ingress など)は爆発的に増加しました。これにより、大きく 2 つの「運用の死角」が生まれています。
- 「VM の稼働 ≠ サービスの健全性」 : かつては「VM が動いている=サービス正常」でした。しかし、無数の Pod が連携する現在、VM が正常でもサービスダウンは起こり得ます。監視の定義そのものが変わってしまったのです。
- 「切り分け」の超高難易度化 : 障害要因が、アプリ(コード)、コンテナ(リソース制限)、インフラ(VM 競合)、外部連携 (NW 遅延) と多層にまたがるため、根本原因の特定が極めて困難になっています。
こうした構造変化により、現場では具体的にどのような混乱が起きているのでしょうか。私たちのもとには、以下のような切実なご相談が寄せられています。
-
「特定のノードだけ重いが、何の Pod が動いているかわからない…」 インフラ側で VM のリソース異常 (CPU / Memory / I/O) を検知しても、それが「どのビジネスアプリ(Pod)によるものか」が特定できません。結果、開発チームへ具体的な指摘ができず、調査が停滞します。
-
「開発から Pod が遅いと言われたが、VM のリソースは空いている…」 インフラ層では正常に見えても、コンテナ固有のリソース競合 (Cgroup) やネットワーク輻輳がボトルネックになっているケースです。従来の VM 監視だけでは、この「見えない壁」の向こう側を覗けません。
-
「夜間にストレージ I/O が高騰したが、犯人を追跡できない…」 Datastore で I/O スパイクを検知しても、「どの Pod が、どの頻度で」叩いているかが見えません。これでは根本原因の特定も、将来のリソース設計も不可能です。
-
「ツールがバラバラで、監視がサイロ化している」 仮想マシンは VMware vCenter® (以降 vCenter) 等のツール、Kubernetes は Prometheus / Grafana ……。障害時、2 つの異なる画面を見比べ、手作業でログを突き合わせる作業が発生していませんか?この「ツールの分断」こそが、MTTR(平均復旧時間)を長期化させる要因となっています。
2. VCF Operationsによる「可視化」
インフラと Kubernetes が「別モノ」として管理されてきたことによる「監視の深い溝」。VMware Cloud Foundation® Operations (以降 VCF Operations )が「物理層」から「コンテナ」までを可視化します。これら2 つの連携が分断を解消し、インフラとアプリを繋ぐ解決策だと考えます。以降は、VCF Operations が SRE の責務をどのように支援するかについて、具体的な機能の観点から解説します。
VCF Operations により「監視の深い溝」を解消する
VCF Operations は、Management Pack for Kubernetes という強力な拡張アダプタを提供することで、「監視の深い溝」を取り払います。VMware vSphere® Supervisor ※ (以降 Supervisor) 上で提供される VMware vSphere® Kubernetes Service(以降 VKS)から払い出された Kubernetes 環境はもちろん、オンプレミスやクラウド上の他の Kubernetes クラスタも、すべて単一のダッシュボードで統合的に監視・管理することが可能です。 SRE の業務を以下のように変革します。
※ Supervisor は、vSphere のクラスタ環境そのものを Kubernetes として機能させる統合レイヤーです。vCenter 上で仮想マシンとコンテナを一元的に管理・監視できるようになります。Supervisor 上で提供される VKS により、開発者は必要な時に、自分専用の Kubernetes クラスタを払い出すことができます。詳細 : Link
- Kubernetes オブジェクトの健全性を「深層まで可視化する」
従来のインフラ監視ではブラックボックスになりがちだったコンテナ内部の健康状態を、詳細かつリアルタイムに把握できます。Kubernetes は動的であるため、どのコンテナがどの物理ホスト上で動いているかを把握するのは困難です。VCF Operations はこれを可視化します。
・階層的なドリルダウン : Kubernetes クラスタ全体の健全性から、Node、Pod、個々の Container レベルまで、問題の発生源を瞬時に掘り下げることが可能です。
・リソース消費の最適化 : 「どの Pod がメモリを過剰に消費しているか」「CPU リミットに達しているコンテナはどれか」といった情報を即座に特定し、アプリケーションのパフォーマンス低下を防ぎます。
・イベントとログの統合 : Kubernetes のイベントログとリソースメトリクスを並べて確認できるため、Pod の再起動 (CrashLoopBackOff) やスケジューリングエラーの原因究明が迅速化します。
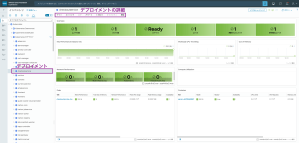
・トポロジーマップ : 物理インフラ(ESXi, Datastore)から仮想マシン、そして上位の Kubernetes オブジェクト(Namespace, Service, Pod)までの 依存関係(Dependency) を自動的にマッピングします。「例えば、物理ディスクの遅延が、特定のマイクロサービスにどう影響しているか」を一目で理解できます。
図2. Kubernetes オブジェクトの健全性を可視化 1/2
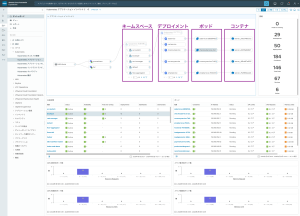
図3. Kubernetes オブジェクトの健全性を可視化 2/2
- 「見えない依存関係」を描き出し、未来を予測する(相関関係とキャパシティ)
(Supervisor 上 VKS から払い出された Kubernetes 環境における機能)
・AI ベースのキャパシティプランニング : 過去のトレンドに基づき、「現在のペースだと、いつクラスタのリソースが枯渇するか (Time Remaining)」を予測します。これにより、SRE は「障害が起きてからの対応」ではなく、「リソースが尽きる前のプロアクティブな増強」が可能になります。
・「What-If」 シナリオ分析 : 「Kubernetes クラスタをあとどのぐらいデプロイをしたらどうなるか?」といったシミュレーションを行い、安全な拡張計画を立案できます。
3. 後編に向けて
後編では、この「VCF Operations」の可視化機能、Management Pack for Kubernetesによる統合監視を実際の画面キャプチャとともにご紹介します。


