
今回は、VMware Office of the CTO (OCTO)がオープンソースで開発を進めているKey Value Store (KVS)の一つであるSplinterDBと、この技術のvSAN 8への適用について紹介をしようと思います。
Key Value Storeというと、すでにredis、etcd、RocksDBなど、たくさんの実装が存在しており広く使われています。そのような状況の中で、なぜ、新たなKey Value Store技術を開発しているのか疑問に思われる方もおられると思います。これには近年のコンピュータシステムの進化の流れに深く関係しています。
一般的にコンピュータシステムはCPU、メモリ、ストレージ、ネットワークなど、複数のハードウェアコンポーネントから構成されています。これらの中でKey Value Storeの性能と関連が深いCPUとストレージに注目してみましょう。ストレージ技術の進化は着実に進んでいます。HDD->SSD->NVMe/SSDと高速化が進んでいます。一方、CPU単体の性能は、かつてほどの急激な進化は見られなくなっていて、ムーアの法則はもはや成り立たなくなったとも言われています(この記事を書いている最中に、ムーアの法則を提唱したゴードン・ムーア氏が亡くなられました。ご冥福をお祈りいたします)。しかし、CPUのコア数やスレッド数は順調に増えており、並列性で性能を稼ぐことができるようになってきています。
これらのハードウェアの進化のペースを考えると、ストレージの性能を十分に引き出すことができ、CPUに対する負荷が高くなく分散処理ができるようなKey Value Storeがあれば、モダンなコンピュータの性能を最大限に引き出せることができると考えられます。SplinterDBはまさにこのようなところを狙って作られた新しいKey Value Storeです。
SplinterDBはBε-Treeをより進化させたMapped Bε-Treeというデータ構造を基礎にしています。Bε-Treeは従来のB-Treeの各ノードにバッファを設けて、バッファに書き込めるうちはバッファに書き込み、バッファが一杯になった際に子ノードにバッチでフラッシュするようにして、書き込み(insert)の性能向上を実現しています。

Mapped Bε-Treeでは、これらのバッファを複数設け、バッファフラッシュ時のオーバーヘッドを減らしています。各バッファに目的の要素があるかどうを調べる際によく用いられるのがAMQ (Approximate Membership Querry: 素Eが集合Sの中に含まれるかを問い合わせた際に、「含まれる」という答えが間違っている可能性があるが、「含まれない」という答えは決して誤りがないデータ構造。Bloom Filter、Cockoo Filter、Quotient Filterなどが代表的)ですが、Mapped Bε-Treeのように複数バッファがあると、それらを一つずつAMQで確認をしていかなければなりません。そこで、Mapped Bε-Treeでは、AMQフィルタの代わりに “Maplet” という仕組みを使っています(下図のピンク色のトンボのようなアイコンがMaplet)。

MapletはAMQのように単にYES/NOを返すのではなく、複数の値を返すことができます。キーが与えられた時にその要素が含まれている可能性のあるバッファのインデックスを返すようにMapletを作ることで、可能性のあるバッファだけ調べればよくなります。また、Mapletを使うと、一つのキーがどれくらい多くのバッファに含まれている可能性があるのかも分かるので、効率よくCompaction(古いデータを捨ててスペースを確保する)を行うこともできるようになります。
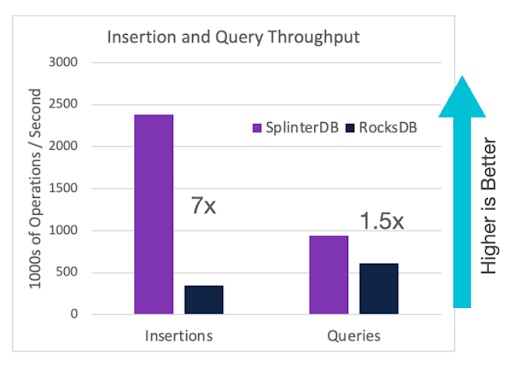
このようなデータ構造とアルゴリズムのおかげで、SplinterDBはCPU負荷が軽く、小さななメモリフットプリントでも動作するI/O性能の高いKey Value Storeとなっています。YCSB (Yahoo! Cloud Serving Benchmark)を使って性能を測った結果を下図に示します。性能が良いことで知られるRocksDBと比較すると、SplinterDBはデータの追加(Insertions)で約7倍、データの検索(Queries)でも1.5倍のほどRocksDBよりも高いI/O性能が得られています。
SplinterDBは、実際にvSAN 8の内部で利用されています。vSANは仮想ディスクなので、論的なディスクブロックを物理的なディスクブロックに変換をする必要があります。この変換ためにvSAN 8から使われるようになったKey Value StoreがSplinter DBです。vSANでの使用を考えると、仮想<->物理ディスクブロックの変換テーブルを全てをメモリ上に持つのは現実的ではなく、ディスクにストアすることになります。その際はNVMe/SSDのような高速なストレージに格納される可能性が高いので、SplinterDBのようにメモリフットプリントが軽く、ストレージの性能を使い切ることができるKey Value StoreはvSANにとても適しているわけです。vSAN 8の性能が大きく向上したのは、このSplinterDBの採用による部分が大きく寄与しています。
SplinterDBはオープンソースで開発が進められています。SplinterDBはこれからさらに発展していく可能性を秘めています。皆さんのSplinterDBへの貢献が、vSANのさらなる性能の向上に繋がるかもしれません。興味がある方はぜひGitHub上のSplinterDBのレポジトリを覗いてみてください。
References:
- https://splinterdb.org/
- https://www.usenix.org/system/files/login/articles/login_oct15_05_bender.pdf
- https://www.usenix.org/conference/atc20/presentation/conway
- https://blogs.vmware.com/opensource/2022/06/15/introducing-splinterdb-high-performing-key-value-store/
- https://github.com/vmware/splinterdb


