
SplinterDB is a general-purpose embedded persistent key-value store offering performance up to an order-of-magnitude greater than other state-of-the-art key-value stores.
SplinterDB derives its performance from new data structures developed by the VMware Research Group in collaboration with the vSAN product team. These data structural improvements remove the need to choose between fast insertions and fast queries by providing the best of both worlds. SplinterDB also scales across multiple cores, enabling it to fully exploit the performance of modern NVMe storage devices.
As a result, SplinterDB has the potential to accelerate all kinds of applications built on top of key-value stores, including relational databases, NoSQL databases, microservices, stream processing, edge/IoT, metadata stores and graph databases. SplinterDB’s performance can be used to do more with the same resources or to save money by meeting existing workload demands using fewer resources.
SplinterDB
SplinterDB is an embedded, external-memory key-value store. By embedded, we mean that applications use SplinterDB by linking the SplinterDB library into their executable. By external-memory, we mean that SplinterDB stores data durably on disk and can scale to huge datasets larger than the available system RAM. SplinterDB fills the same niche as RocksDB, the leading open-source key-value store.
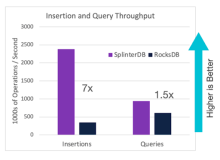
What makes SplinterDB special is its speed and efficiency. For example, Figure 1 shows the throughput of SplinterDB and RocksDB on the industry-standard Yahoo Cloud Services Benchmark (YCSB). SplinterDB is about seven times faster than RocksDB for insertions, and about 1.5 times faster than RocksDB for queries.
Performance
SplinterDB is exceptionally efficient in utilizing resources. For example, in the benchmark in Figure 1, SplinterDB and RocksDB were storing an 80 GiB dataset on a system with 4 GiB of RAM. Because only a small amount of the database could fit in cache, I/O efficiency was essential to good performance. SplinterDB does half the I/O of RocksDB in this benchmark. This benchmark also used systems with Intel Optane-based SSDs, which support over 2 GiB/sec of read and write bandwidth. Yet, RocksDB was actually CPU bound — using only about 30% of the available storage bandwidth — despite the fact that it uses bandwidth less efficiently. SplinterDB, on the other hand, used over 90% of device bandwidth during this benchmark run. For queries, RocksDB gets reasonably close to maxing out the drive IOPS, so there isn’t as much room for improvement. Nonetheless, SplinterDB improves performance by about 50%, primarily through lower CPU costs and better caching.
A common reaction to our performance results is incredulity. How can we possibly outperform the leading open-source key-value store by a factor of 7x? RocksDB is developed by Facebook, an industry leader! Who do we think we are?
SplinterDB makes these performance gains by thinking differently about the fundamental data structures, enabling it to overcome a long-standing trade-off between update and query performance in external-memory key-value stores.
The key idea is actually quite simple to explain. Modern key-value stores (including SplinterDB, RocksDB, LevelDB, Apache Cassandra and many others) store their data in large, sorted tables. Queries then search each table from newest to oldest. Thus, queries slow down as the system accumulates more and more tables of data. To keep queries from being too slow, these systems occasionally take several sorted tables and merge them together into a single sorted table, a process called compaction. This creates a tension between insertion performance and query performance. By compacting aggressively, these systems can keep queries fast, but insertions become slower. By compacting lazily, insertions can be fast, but queries will suffer.
SplinterDB compacts about 8x more lazily than RocksDB, which is why insertions in SplinterDB are about 7x faster than in RocksDB.
But what about queries? What price does SplinterDB pay for compacting lazily? In order to keep the queries fast, SplinterDB departs significantly from existing key-value stores. Most key-value stores use Bloom filters (or cuckoo filters) to accelerate queries. A filter is a small data structure that represents a set. RocksDB and other key-value stores one filter for each table, and queries first check the filter before searching the table itself, so most queries will search only a single table. The assumption behind this design is that the small filters will fit in RAM, and so queries will incur I/O for only a single table search.
Having a separate filter for each table doesn’t work so well on fast storage or when the data set is much larger than RAM. On fast storage, the CPU costs of filter lookups can become significant due to the large number of filters. For data sets larger than RAM, filters may exceed RAM capacity, which means that they will be stored on disk. Performing a lookup in the filter will then incur I/O, rendering the filters useless.
SplinterDB uses a new kind of filter called a routing filter. A single routing filter can replace several Bloom, cuckoo or ribbon filters and can cover several tables. Traditional filters can tell you only whether a key is present or not. Routing filters, on the other hand, can tell you not only whether a key exists, but which sorted tables contain the given key. Thus, queries need to perform far fewer filter lookups, reducing CPU costs. Furthermore, since a single filter lookup can save multiple table queries, routing filters remain effective even when they are too large to fit in RAM. Routing filters are the key to how SplinterDB simultaneously has excellent insertion and query performance, and routing filters were invented here at VMware.
Although we often talk about how much “faster” SplinterDB is compared to other key-value stores, we would like to emphasize how much more “efficient” SplinterDB is. After all, many people are happy with the speed of their key-value stores. And, if not, then they can scale out to dozens or even thousands of servers to get the performance they need. What SplinterDB delivers is the ability to do more with less — saving money on infrastructure and management. For example, a setup that needs 1,000 RocksDB servers could be replaced with a fraction as many SplinterDB servers, reducing a data center-sized installation to a handful of racks. Furthermore, in a mixed insert/query workload, SplinterDB may offer more than a 50% speedup on queries. Because insertions are so much cheaper, more CPU and bandwidth is available for queries. Finally, by making insertions so cheap, SplinterDB may make it possible to maintain indexes that would otherwise be too expensive to maintain, which can make queries much, much cheaper and faster.
Our Open Source Journey
In March 2022, the SplinterDB library became open source. This milestone is the culmination of our pursuit of making SplinterDB an open storage engine that is welcoming to innovation. Similarly, this is the beginning of our developer community and communicates our dream of seeing SplinterDB support an ecosystem of applications without vendor lock-in.

SplinterDB is the culmination of the work and contributions of many people, with special thanks to the team who maintains this open source version (left to right, top to bottom): Alex Conway, Carlos Garcia-Alvarado, Abhishek Gupta, Aditya Gurajada, Rob Johnson, Gabriel Rosenhouse and Rick Spillane.
Join Us!
We are looking for more opportunities to enhance SplinterDB. We invite you to be part of our user and development community by joining us through splinterdb.org. In there you can meet the team, learn more about SplinterDB and perhaps suggest to us a use case for SplinterDB to accelerate your application. If you prefer sending an email, you can also reach us at splinterdb@vmware.com.
Stay tuned to the Open Source Blog and follow us on Twitter for more deep dives into the world of open source contributing.



