

はじめまして。VMware の伊藤です。Tanzu 製品のプラットフォームアーキテクトとして働いており、開発と運用双方の経験があります。この記事ではオンプレミスでもパブリッククラウド上でも利用できるマネージドデータベースである Tanzu SQL の Postgres Kubernetes 版の概要と利用方法を紹介します。
この記事の内容は以下の記事の内容を読んでいることを前提に書いています。また、利用しているバージョンは 1.2.0 となります。
Tanzu SQL for K8s Postgres の概要とインストール作業
Tanzu SQL for K8s はマネージドな運用手法を提供することで、データベースの管理負荷を減らします。ただし、単なる既存データベースの置換えとしての利用だけでなく、モダンなアプリケーションの開発にも適した使い方ができます。
以下にレガシーなアプリからモダンなアプリへ、データベースの利用法がどのように変化しているかを示す図を記載します。
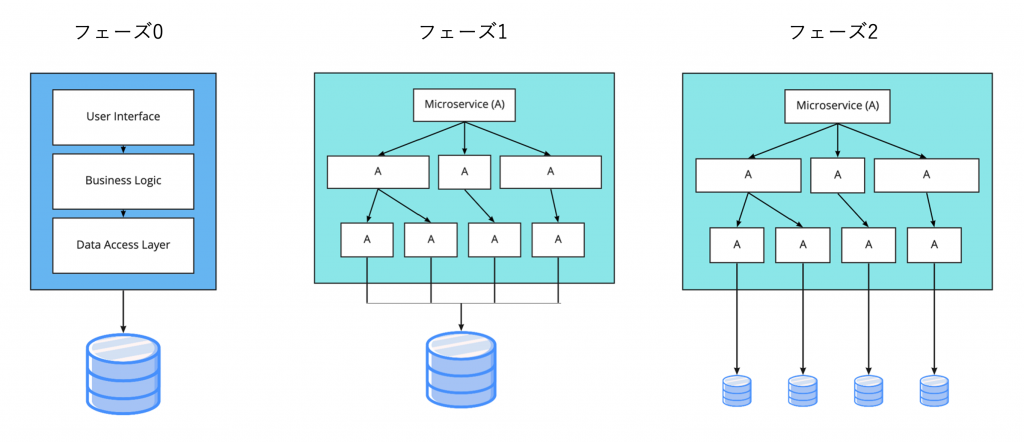
従来ながら開発では、アプリケーションサーバーの機能がたくさん詰め込まれていることが多く、複雑なビジネスロジックが広範囲に渡るデータベース操作のコードを介して、データベースを利用します。機能が多いということは、それだけデータベースに書き込まれる情報も多岐にわたるということです。
マイクロサービスに代表されるモダンな開発手法では、このロジックの実装を役割ごとに「サービス(ミニアプリ)」として分離して連携させるという手法を使います。こうすることで個別機能の変更にたいする負担が減少するというメリットがあります。ただし、ロジックの分離に比べてデータの分離は難易度が高いです。そのため、図の中央のようにコードは分離したものの、データは集約されるという形態となることが多いです。
マイクロサービスをつきつめると、サービスごとのデータの依存性も減らしたほうがサービスの独立性が増すため、右の構成に持っていけるのであれば、そうすることが望ましいです。
この図のデータベースの運用を考えると、左と中央のデータベースは役割を多数持つため複雑です。一方、右のデータベースは数こそ多いものの1つ1つのデータベースの役割はシンプルとなります。右の構成をマネージドデータベースで実現すると、基礎的な操作しか求められず、その操作もマネージドな使い方でカバーできるため、運用が非常にシンプルとなります。
Tanzu SQL というよりマネージドデータベース論に話が脱線してしまったので、話を元に戻しましょう。Tanzu SQL はマネージドなデータベースの利用を以下の図のような形式で実現しています。
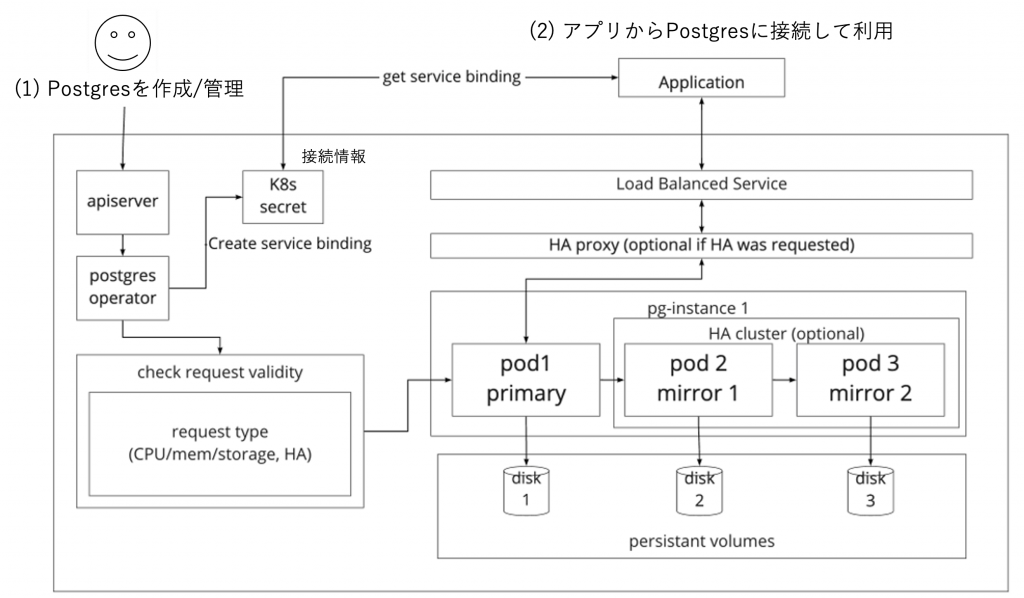
K8s のオペレーターや、Postgres の知識自体がないと難しい構成に見えるかもしれませんが、Tanzu SQL の利用者としてやることは2つだけです。
- K8s 的にデータベースを管理運用する
- 作成したデータベースを K8s 内で利用したり、K8s の外部に公開する
オペレーターレベルであれば K8s の知識なしに機械的に利用可能ですが、状態チェックなどをするには K8s の知識があることが望ましいです。たとえばこの記事の作成時に「極小のクラスターで展開したため、リソース不足で Pod の展開が Pending 状態になっていた。問題解決のためにスケールアップ操作(ノード数の増加)でリソース追加した」ということが発生しましたが、そういった状況の確認は K8s 的な操作が必要になります。
図の左側にある K8s Operator を使った複雑なシステムの管理方法は K8s では一般的です。サポートがないことなどを気にしなければ、Tanzu SQL に類似する OSS のデータベースオペレーターなども使えます。
Tanzu SQL for K8s をインストールすることで、この Tanzu SQL のオペレーターが使えるようになりますので、オペレーターにたいして Pod の宣言などと同じ要領で「データベースの構成の宣言」をすることで、宣言に沿ったデータベースを作成/変更/削除できます。
図の右側上部にあるアプリケーションからのデータベースの利用も、K8s では一般的な形式で実施します。サービスとして公開したデータベースのインスタンスにたいして内外からアクセスできるようになっています。具体的な方法はのちほどサンプルでお見せしますが、アクセスに必要なクレデンシャルと言った情報は Tanzu SQL が K8s の Secret リソースとして管理しており、これは K8s でパスワードなどを管理する際の一般的な仕組みを使っています。
この記事ではこれらの前提知識をもとに、以下の手順で Tanzu SQL を利用します。
- データベースの YAML を定義
- YAML からデータベースを作成
- 作成したデータベースを「kubectl exec」で直接操作してみる
- データベースのクレデンシャルを使って、K8s 内の別の Pod(アプリサーバー相当)からデータベースを操作してみる
なお、これらの操作を実施するまえに、そもそも Tanzu SQL が正しくインストールできているか確認しておいてください。

上記のように、Helm でリリースに成功していたら問題ありません。Status の項目に着目してください。
この記事の情報は以下の公式ドキュメントから作成しています。詳細はドキュメントをご確認ください。
データベースのYAMLの定義
Tanzu SQL のオペレーターをインストールしたことで「Postgres」というリソースが K8s に追加されています。このリソースの詳細を Pod や Deployment などと同様に YAML ファイルに記述して、kubectl apply/delete をすることでマネージドなデータベースを作成/変更/削除することができます。
以下にサンプルのYAMLを記載します。
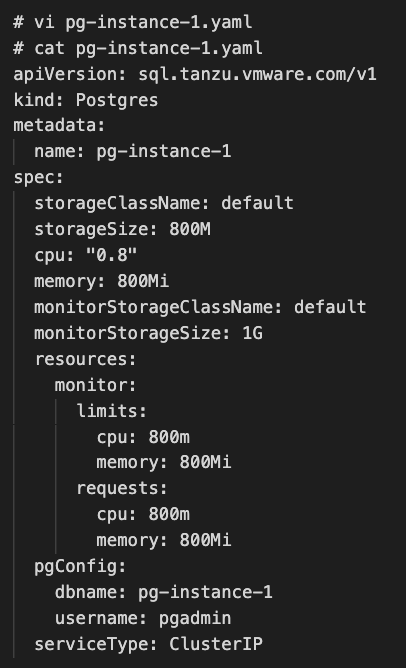
YAML に書かれている内容を読むと、ほとんどは名前やリソース定義といった内容であることがわかります。「pgConfig」では Postgres に作成するデータベース名とユーザー名を定義しています。パスワードは自動生成されます。この pgConfig 配下の項目は kubectl apply で更新できないので注意してください。その他多くのリソースは変更可能です。
そして「serviceType」は作成したデータベースのインスタンスをどの K8s サービスで公開するかを指定します。内部利用であれば ClusterIP を指定し、外部公開だと LoadBalancer を指定します。この項目は変更可能です。
これら項目や、省いてしまった項目(たとえば HA 周り)の詳細は先に提示した公式ドキュメントがありますので、そちらをご確認下さい。基本的にはドキュメントからコピペしてきて、必要な項目を修正する流れで YAML を作成します。
YAML からのデータベース作成
YAML からデータベースを作成することは非常に簡単で、他のリソースと同様に「kubectl apply -f <ファイル名>」とするのが一般的です。
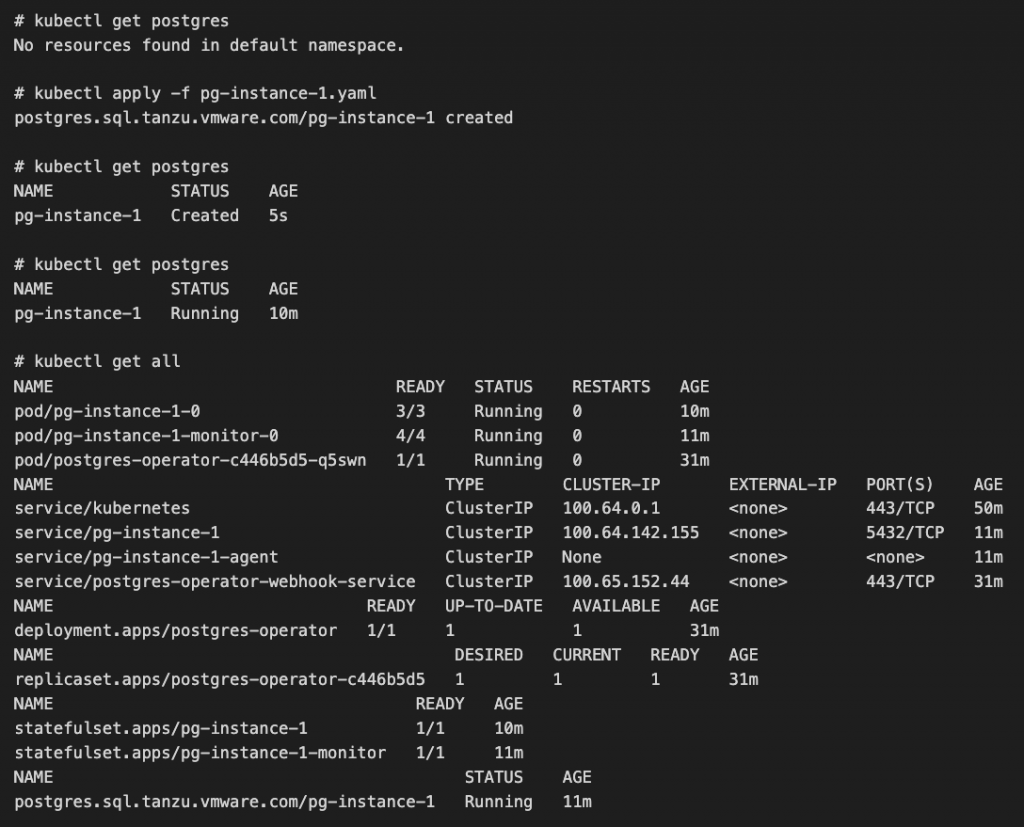
Postgres データベースの1グループ(Pod などではなく、一式として動作している deployment のような上位リソース)は「postgres」というリソースで管理されています。「kubectl get postgres」で一覧が得られて、「kubectl describe postgres」で詳細が得られます。「kubectl get pods/all」などで、名前からどの Pod がどの Postgres リソースに属するか簡単に特定可能です。
Postgres リソースを作成してから利用できるようになるまでは、内部的には Pod の展開と設定作業だけなので時間はかかりません。kubectl apply をしてから、すぐにステータスが Running となり、実際には「10m」はかかりません。今回は私の不手際で K8s ノードの追加作業が間に挟まったため長くなっています。
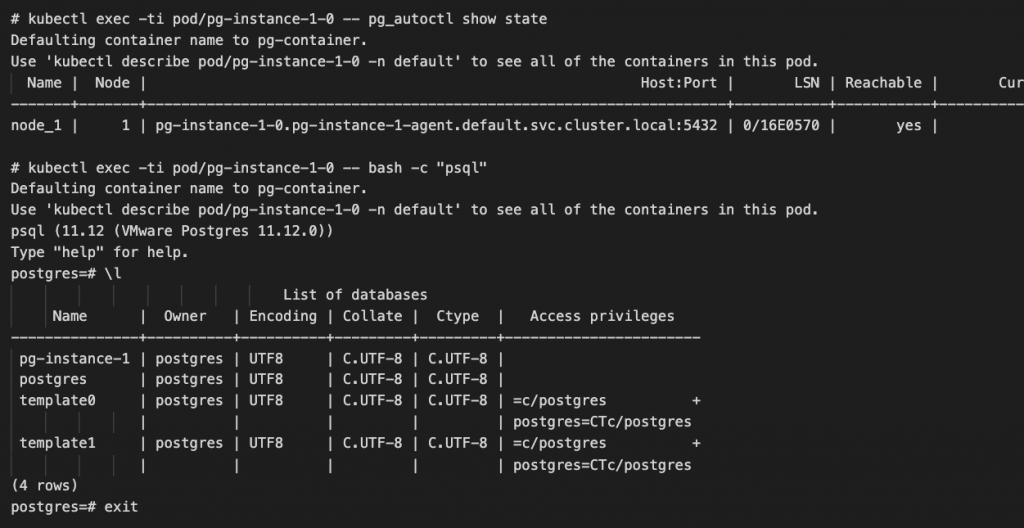
作成した Postgres を直接操作するには、Primary(冗長化時のリーダー)として動作している Pod に kubectl exec で psql コマンドを発行します。どの Pod が Primary として動作しているかを確認するには、Postgres を構成するどれか1つの Pod にはいって「pg_autoctl show state」コマンドを発行する Postgres 的な操作を実施します。Postgres を構成する Pod 群は名前から特定できますが、詳細に調べたければ Postgres リソースを describe してください。
今回は冗長化をYAML設定に含めていないため、「pg_autoctl show state」で1行しか表示されていません。冗長化時には複数行になり、表の右側(見切れている)で、Primary の Pod がどれかを特定可能です。
Postgers の Primary として動作している Pod を確認したら、その Pod にたいして kubectl exec で psql コマンドを発行して操作可能です。
Postgresを外部から利用する
作成した Postgres をデータベースとして利用する方法は、データベースクライアント側としては従来の手法と変わりありません。以下の項目を指定して接続するだけです。
- ホスト(ドメイン or IP)
- ポート(デフォルトでなければ)
- ユーザー名
- パスワード
- データベース名
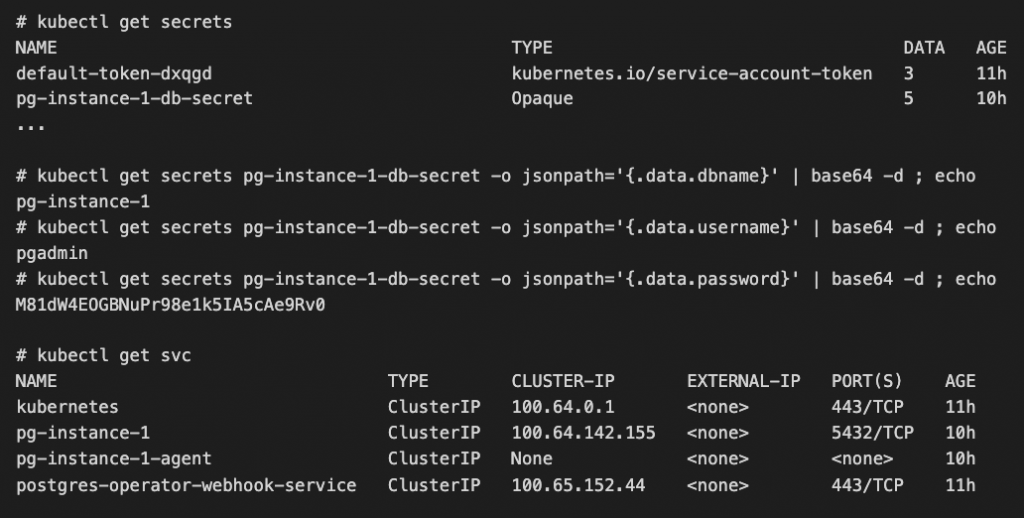
このうち、ユーザー名とデータベース名のみは YAML の設定ファイルに書きましたが、その他の項目は Postgres リソースが利用している Secret リソースから特定します。ホストについては K8s 的にサービスを確認するだけです。
以下では Secrets を名前から特定(必要なら describe を使ってください)し、そこからユーザー名、パスワード、データベースを base64 デコードして得ています。そして、Postgres のホスト名に相当する K8s のサービス名を得ています。接続する際のホスト指定としては IP(100.64.142.155)を使っても動作しますが、どの環境でも一貫して利用できるように名前(pg-instance-1)を指定するほうが K8s の利用法的には望ましいです。
このようにして得た接続情報を使って、実際に Postgres を外部利用してみます。ここではPostgres クライアント(Docker Hub の公式Postgresコンテナイメージを利用)から、Tanzu SQL の Postgres インスタンスにたいして接続させるという例を使いますが、一般的なアプリケーションサーバーのデータベース接続方法と大差ありません。
上記作業で取得したパラメーターを変数に代入し、確認のために psql のリモート接続用の URL を作成して表示しています。そして、その URL を使って、 実際に kubectl run で作成した一時的な Postgres クライアント Pod から、Tanzu SQL の Postgres に接続させています。
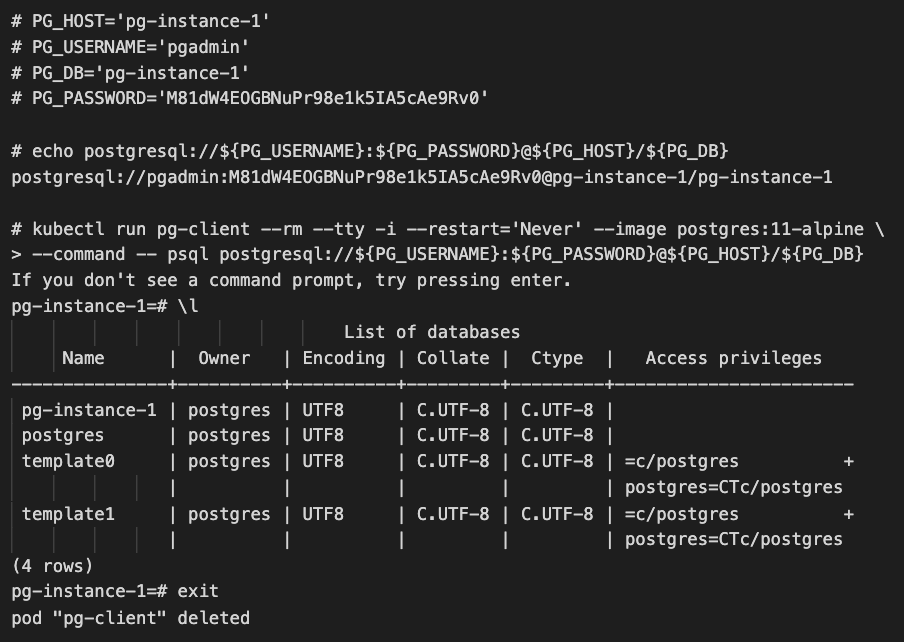
特に問題なく K8s 内で Postgres に接続できていることが確認できました。
K8s 外からアクセスしたい場合は、一般的な K8s アプリと同様に以下の手順で進めてください。
- Postgres を Service Type LoadBalancer などで外部公開
- 作成されたサービスの external IP を確認
- 上記手順に沿って、クレデンシャルやデータベース名を取得
- Postgres クライアントで、external IP やクレデンシャル、データベース名を指定して接続
この最初のステップの外部公開は、Postgres の YAML 定義で利用するサービスの種類を指定することで実施できます。
Postgres の更新と削除
この記事の最後に作成した Postgres を K8s 流に構成変更し、削除を実施します。
構成変更はわりと大きめの変更として「HA(High Availability : 冗長性)なし -> HA あり」という変更を加えます。作業としては簡単で、Postgres の YAML を HA なし(デフォルトなので記述なし)から、HA ありに変更するだけです。以下にサンプルを記載します。
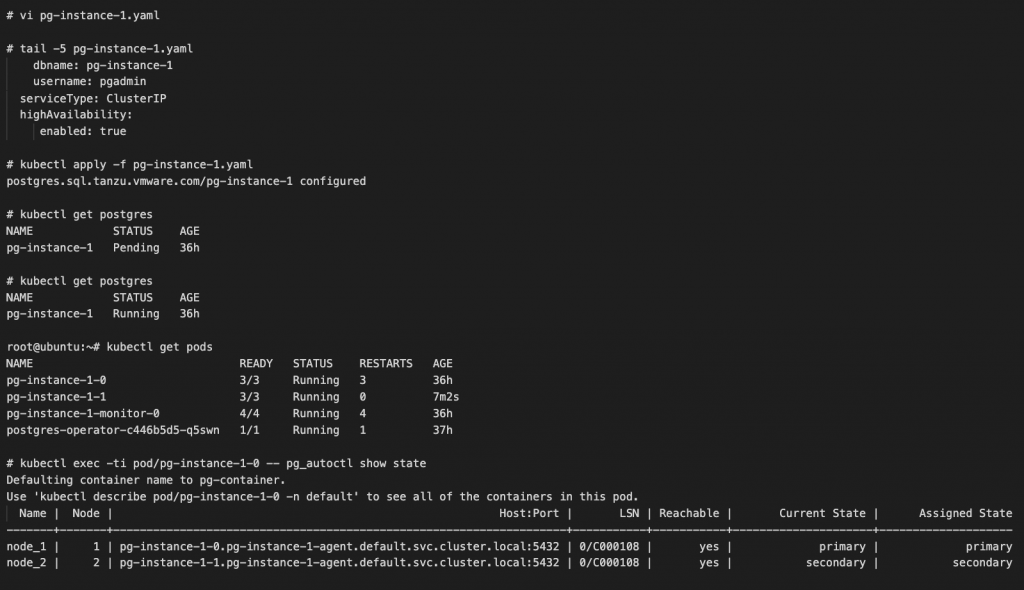
vi で YAML の最後に HA を enabled : true という記述を追加しています。そして、kubectl apply で更新をすると、Postgres の Secondary (スレイブ)が Pod として追加され、Postgres のクラスタとしても Primary/Secondary の認識をしっかりとしています。なお、kubectl get pods の結果の Restarts の数が多いですが、障害耐性の確認のためにノードの電源ぶち切り検証などをした際のものなので無視してください。
Postgres の Pod の台数は増えていますが、前面にいるサービスにたいしてクライアントは通信していますので、HA の有無などはクライアント側には透過な変更となります。実際、先程のホスト名などのパラメーターを全く変更せずに、HA 構成にしても外部の psql から Postgres を使えています。
最後に Postgres を破棄します。これも K8s 流に kubectl delete するだけです。
リソースがなくなったので、Postgres のリソース一覧からなくなっています。
以上で基本的な Tanzu SQL の利用方法の紹介を終わります。ご拝読ありがとうございました。


