

はじめに
GemFireは一言で言うと「分散key/valueインメモリストレージ」であり、インメモリストレージとしてアプリケーションの高速キャッシュとして利用が一般的です。例えばデータベース等の永続ストレージへの依存の為充分なレスポンスタイムが得れない場合、頻繁にDBへのアクセスが発生する場合での利用です。アプリとデータストアの間にGemFireを置くことにより、ピンポイントにレスポンスタイム/スループットを向上する事が可能です。この様なユースケースでは開発観点でも利用は簡単で、一般的なREST APIやRDBMSにアクセスするのと同じ要領で、水平スケール可能な巨大インメモリストレージを利用できます。

一方、GemFireの特徴を捉えることにより、単純なメモリキャッシュとしてだけではなくより戦略的にGemFire利用する事が可能です。アプリのメモリ領域を数百GBレベルの巨大メモリグリッドと接続したり、他のソリューションでは困難な超低レイテンシ/高スループットのデータプラットフォームとしても利用できます。今回はGemFireのデータ整合性に対する思想、ランタイム構成、そして活用パターンと事例についてご説明します。
まずはGemFireの設計思想と特徴からご説明します。
分散ストレージとデータ整合性
GemFireは分散ストレージでありながら、データの可用性より整合性を重んじます。
多くの分散ストレージでは分散したデータコピーの同期は非同期処理によって行いますが、これは整合性より可用性を重んじる為です。とはいっても「データが複数ノード上で同じ状態である」事は保証しており、一般的な「データが壊れない/一貫している」という認識に近いものです。(具体的には同じレコードを分散配置したとしてもこれら全てが同じ値に帰結するという事を保証。)
多くのユースケースでは、このレベルの整合性を確保出来ればデータは安全に分散配置でき、またこの処理を非同期で行う事によりWriteのスループットを落とさずにデータを分散配置できます。確かに登録したばかりのエントリーがリストに表示されなかったり、更新したはずの情報がまだ古い状態で表示されたりする事が稀に発生します。ただ一般的にはキャッシュ技術を用いたシステムでは昔から良くある事象である為、ユーザーは無意識にページをリロードすることにより解消してしまうのが常です。UXには影響はありますが業務的な影響はあまりありません。
しかしながら、この整合性では高い並列処理を求められるケースでは充分でないケースが多々あります。
例えば証券の売買取引や飛行機の座席確保といったユースケースでは「全てのユーザーがどのタイミングでどのレコードを参照しても同じ値を見る」ことが業務上の必須非機能要件となり、これが達成できない場合にはビジネスとして成立しません。この要件はシステムのスループットに関わらず要求され、多くのシステムではこの要件の為キャッシュではなくデータベースへの直接参照という選択肢が取られます。
この要件を満たすためにはKleppmann氏の説明する線形化可能性 (Linealizability) を達成する必要があります。GemFireは分散インメモリストレージながらこの要件を満たしています。
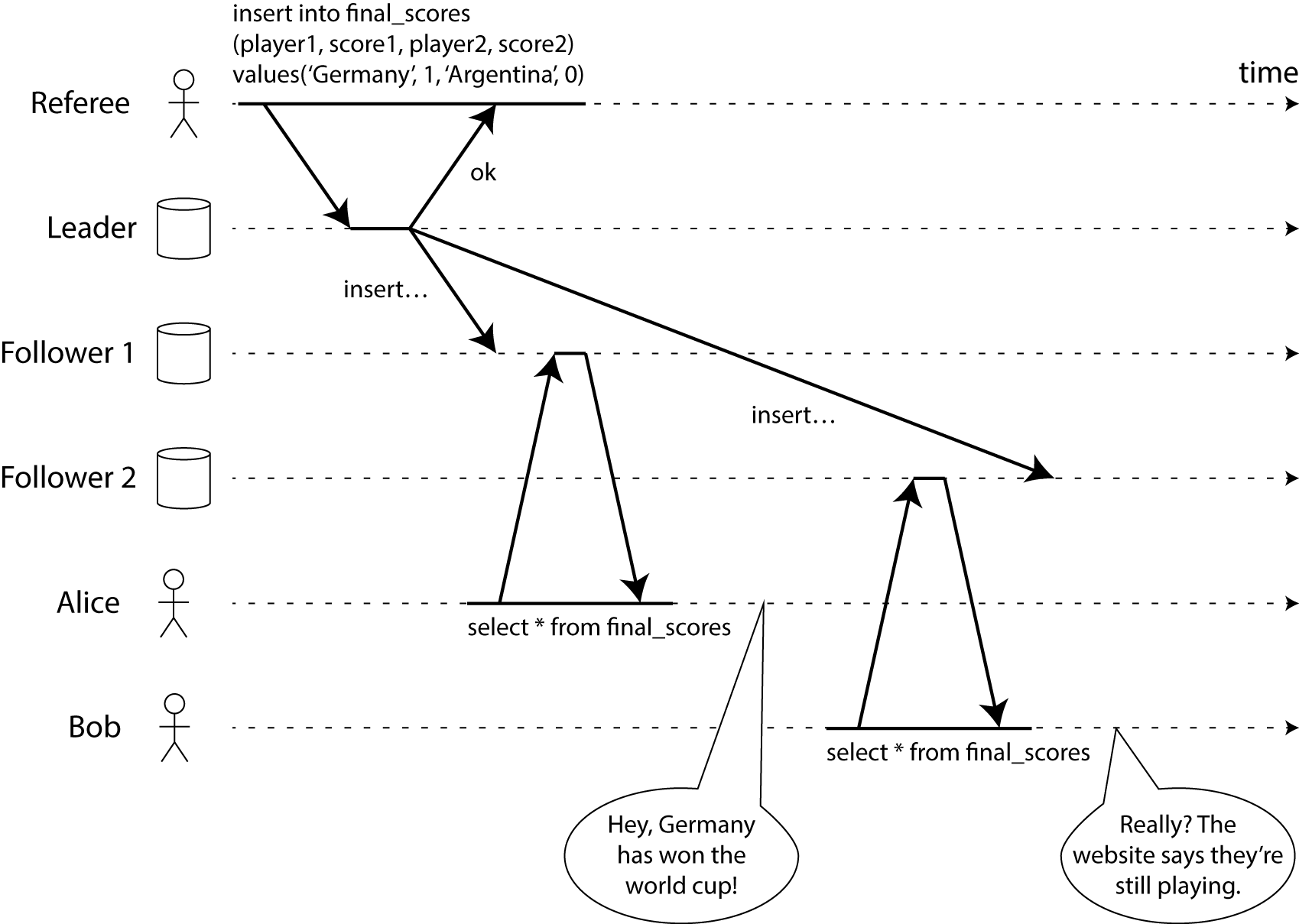
上記はMartin Kleppmann氏の線形化可能性に関する考察で表現されている線形化可能性が達成できていないケースの図です。ここではLeaderからFollower1及びFollower2に非同期に更新情報が渡されています。この同期処理が完了する前にこれらFollowerにアクセスしたユーザーが複数いる場合、参照しているノードにその更新が反映されたか否かによって異なった結果が返ってくる可能性があることを示唆しています。
座席が空いている認識で決済を完了したが、実は既に座席は他のユーザーに確保されていた、という事が起こりえます。
GemFireとデータ整合性
GemFireは『Consistency over Availability』を設計思想として謳っており、この線形化可能性を担保する為に以下の制約を設けています。
- Writeは常に1ノードのみ許容。
- ネットワーク分断時、ノード数が過半数に満たないクラスタ断片を即座にサービス停止する。
- Writeは直列化したのちに完了とする。(全てのコピーの値が等しくなる)
GemFireではデータ整合性と可用性を、何かしら特殊な仕組みや複雑な機能性を駆使して高いレベルで達成する事を目的とはしていません。ある意味潔くデータ整合性に影響のある要件はばっさり落としています。特にネットワーク分断に対しては、分断された際にはより小さいクラスタ断片を捨てる、つまり一番大きな断片のみで稼働を継続する事により線形化可能性を確保しています。最悪の場合スループットを1/2近く犠牲にする可能性があっとしても、GemFireはデータの整合性をより重んじる為この犠牲を許容します。
また、#3は非同期ではなく同期によるデータレプリケーションを指しており、一般的にはスケーラビリティの観点から敬遠されがちなアプローチではあります。しかしこの制約は、通常の永続化ストレージにおける同期処理と比べるとその遅延影響は軽微であり、インメモリストレージの場合には許容範囲と考えています。
ただGemFireはこれを機能面における絶対的な制限とはしておらず、非同期処理よりもさらに低いレイテンシー要件がある場合にも対応していますが、これについては後述します。
どの様に対応しているか?ですが、より柔軟なランタイム構成を可能とするという別のオプションを提供する事により達成しています。
処理をデータの近くで行う
GemFireの1つの特徴はその柔軟なランタイム構成です。GemFireも一般的なストレージ同様API経由でアクセスする事ができますが、アプリ内からGemFireライブラリ経由でアクセスすることにより、合わせて以下の2つのランタイム構成を提供しています。
- アプリ内で格納するローカルキャッシュを明示的に指定して利用する。
- GemFireクラスタ内で処理を実行する。
いずれの方法も処理をデータに近い場所で実行する事により、ネットワーク経由でのやりとり自体を不要とし飛躍的に低いレイテンシーで処理を行う方法です。
#1はクライアントで確保するローカルキャッシュへのアクセスとなり、データがアプリのヒープ領域に存在する為最も高速にアクセスが可能です。アプリ内に存在するキャッシュと数百GBのメモリグリッドはライブラリを通して透過的に接続される為、アプリからはあたかも無限のメモリ領域に対して処理を行える様にデータセットを利用する事ができます。これはAPI経由でインメモリストレージとアクセスするより高速で、かつ開発観点ではデータの扱いが飛躍的に簡略化されます。
サーバーではなくローカルキャッシュに対象を特定して処理を行うことも可能です。GemFireのローカルキャッシュはクライアント側のヒープ領域を使用する為、扱うレコードサイズには物理的な制約はあるものの、多くのユースケースで安全かつ極めて高速にキャッシュデータにアクセスする事ができます。
アプリのインスタンス数が複数になる場合は、別のインスタンスが同じデータを更新する可能性があり、この場合ローカルキャッシュがサーバーと非同期になります。GemFireはではアプリからサーバーに対して更新通知を依頼する事ができ、サーバー側でデータ更新が発生した場合にはプッシュ形式で更新データをキャッシュに反映させる事ができます。厳密にはこのアプローチでもキャッシュの更新反映までにタイムラグは発生しますが、上記の証券の売買取引や飛行機の座席確保といった特殊なユースケース以外では充分早く同期されます。
もう一つは、処理自体をGemFireに取り込みGemFireクラスタ上で実行する方法です。

文字通り処理自体をGemFireクラスタ上で実行する方法で、org.apache.geode.cache.execute.Functionインターフェースを実装したアプリをGemFire上にデプロイし、対象データと同じノード上で実行します。
処理プログラムをjar化した後gfshコマンドを使用してクラスタにデプロイすると、プログラムはクラスタ内全てのノードのクラスローダーに読み込まれます。その後クライアント側からorg.apache.geode.cache.execute.Execution.execute(String functionId) で実行、もしくはAPI経由での実行指示をトリガーとして対象データのあるノード上で実行されます。プログラムはクラスタ上全てのノードで利用可能である為、処理対象データのあるノード上で、つまりデータと最も近い場所で処理が実行されます。
処理はネットワークアクセスを介さず実行されるため極めて高速に、かつ実行リクエストと結果のリターン以外の通信が発生しない為ネットワーク負荷もかけません。他のランタイム構成では困難な、膨大なインメモリデータに対して複雑なデータ処理を行う上で最も高速な処理実行が可能です。
またSpring Integrationとの統合により、複数の処理をプロセスフローとして定義することが可能です。このフロー自体をGemFireクラスタ内で実行する事により、極めて低レイテンシのプロセスフローを定義する事が可能です。例えば5つの処理を跨ったプロセスフローを実行する場合、一般的には対象ストレージがどれだけ高速であっても、処理から処理の連携にはネットワークホップが発生します。このアプローチではプロセスフロー自体をGemFireのクラスタ上で実行する為、フローの最初と最後以外にはネットワークホップを発生させずにレイテンシを最小限に止める事ができます。
事例:600,000TPSをサポートする超低レイテンシ データプラットフォーム
Mastercard様では決済業務の複雑な処理を必要とするトランザクションを、高スループット/低レイテンシで達成する基盤としてGemFireを採用されています。ここで言う高スループット/低レイテンシとは:
- 600,000 TPS
- 平均データ処理時間50ms
という極めて高い要件でした。かつ年間20%のスピードで増加するトランザクションデータと様々な集約データを合わせると倍近い速度でデータボリュームが膨らむ為、高いスケーラビリティと汎用的なハードウェアで増強可能なプラットフォームというプラットフォーム要件も達成する必要がありました。
GemFireは一般的な分散データストア同様シャーディング(GemFire用語ではPartitioning)をもってスケーラビリティを確保するモデルですが、パーティション間のリバランシングを自動で行います。一般的なキーハッシュの定義プラクティスを守れば、クラスタ間のロードはかなりの精度で平準化されます。
合わせてアプリからは、Regionと呼ばれるグルーピングと、ローカル/リージョン/クラスタという異なるスコープに対して処理指定する事が可能です。簡単なコード変更でダイナミックにデータの処理構成を変えることもできます。
Mastercard様ではノードのサイジング、綿密なヒープサイズ調整とGC調整の後にGemFireのデータストアとしてのスループットを充分高める事ができました。しかし次にアーキテクチャ的な課題として、データ処理のためにあまりに多くのデータセットをアプリで処理する課題に直面しました。ここで、ランタイム構成を変更し、アプリの処理部分をGemFire FunctionとしてGemfireクラスタ上で実行する選択をしました。この為大きなデータセットをネットワーク経由で取得、シリアライズ/デシリアライズ、アプリのヒープ領域への読み込み等、大量データを処理する上でのオーバーヘッドを大幅に削減した高速なレスポンスを実現しています。
おわりに
GemFireは一般的なインメモリストレージとして簡単に利用する事が出来ますが、GemFireライブラリを使う事により、より戦略的に活用する事ができます。今回は事例として極めて難易度の高い要件にGemFireがどう活用されているかをご紹介しましたが、課題に応じて柔軟に対応できる、またアプリから大規模な分散クラスタを自在に扱える様々な機能を有しており、多くのユースケースに活用する事が可能です。「キャッシュ」という括りではなく、より革新的なデータ活用の手法としてGemFireをぜひご検討ください。





