


こんにちは。VMware グローバルサポート Newsletter NSX 担当の 柴原 です。
今回は、NSX Advanced Load balancer (以下 NSX ALB) の「バーチャルサービスアナリティクス」の機能を用いた、アプリケーションの応答遅延(レイテンシ)などの障害に対するトラブルシューティングのユースケースについて紹介します。現在、NSX ALB を導入されている方、今後導入を検討されている方のお役に立てれば幸いです。
はじめに
現在、Web サイトや Web アプリケーションで提供されているサービスは、我々の日々の活動を支えるのに不可欠な存在となっています。画像データの読み込みに数分かかっていたインターネット黎明期とは異なり、サービス利用者は必要なタイミングで、必要なコンテンツを遅延なく入手する事を求めており、数秒程度の応答遅延も許容されない状況になりつつあります。実際に皆様が Web サイトにアクセスをした際に、読み込みに数十秒かかるサイトがあった場合、多くの方がコンテンツの読み込みを断念して他のサイトに切り替えてしまうのではないでしょうか。
このような背景から、システム管理者は自身の管理している Web サイトやアプリケーションに対する応答遅延などが報告された場合、迅速な対処を求められるのですが、応答遅延の障害に対しては、調査対象が漠然としておりトラブルシュートが難しいという印象があります。
本 ブログでは、NSX ALB を障害解析のツールとして活用する事で「応答遅延」などの障害が発生した際のトラブルシュートにどのように役立てる事ができるのかについて、具体的な事例をまじえて紹介していきたいと思います。
1. 障害解析ツールとしての NSX ALB の活用について
-1.1 NSX Advanced Load balancer とは
NSX ALB は旧 Avi Networks により開発された 100 % ソフトウェアベースのロードバランサとなります。2017 年に VMware が Avi Networks を買収し、「NSX Advanced Load balancer」として NSX のプロダクトのラインナップに追加しました。クラウドネイティブの設計思想に基づき開発されており、様々なプラットフォーム、マルチクラウド上で動作させることができる汎用性の高い製品です。ロードバランス機能だけではなく、アプリケーション(バーチャルサービス)の健全性監視(ヘルスモニター/スコアによる評価機能)やトラフィックの解析(バーチャルサービスアナライザ)機能も充実しており、障害発生時のトラブルシュートのツールとしても非常に役に立ちます。
-1.2「応答遅延」に対するトラブルシュートの難しさ
ではあらためて、なぜ「応答遅延」などの障害のトラブルシュートが難しいのかについて考えていきたいと思います。システム管理者にとって最も避けるべき障害は、サービスが完全に停止してしまう事ですが、この場合、異常が発生している事は明確であり、本来役割をはたすべき機能が動作していないポイントを見つけるべく、トラブルシュートを進める事ができます。それに対して「応答遅延」などの障害の場合、まず発生している事象自体が漠然としています。どの程度の遅延が発生していたのか、障害であるのか、設計上想定される範囲内なのか、発生頻度や影響範囲はどの程度なのか.. etc. まずは発生している問題の把握に時間がかかります。私もサポートエンジニアとして日々お客様の障害解析の支援をさせていただいているのですが、「応答遅延」などの症状については単純なサービスダウンと比較し(あくまでも比較してですが)トラブルシュートが難しいという印象があります。
-1.3「応答遅延」に対して管理者はどのような調査、分析をもとめられるのか
それでは次に、「応答遅延」などの問題が発生した場合にシステム管理者はどのような調査、分析が求められるのかについて考えていきたいと思います。このような障害が発生した場合、システム管理者はまず、遅延が発生しているボトルネックを早急に特定する事を求められます。しかしながら、現代の企業インフラは複雑に入り組んでおり、物理基盤のみではなく仮想化基盤上でも動作しています。さらにはインターネットを経由して外部のデータセンタや複数のパブリッククラウドと連携している場合にはより複雑な構成となります。調査の対象となるポイントも複数考えられます。物理サーバ、物理ルータ、物理スイッチ、物理ファイアウォール、さらに仮想化基盤上でも多数の仮想マシンや仮想のネットワークコンポーネントが動作しています。また、インターネットを経由して連携しているクラウドサービスとの連携の正常性も確認する必要があります。
そのような環境下においてシステム管理者は迅速にアプリケーションのリソースの全体状況を把握したうえで、ボトルネックとなっているポイントを見極める事を求められるわけです。
-1.4. NSX ALB によるアプリケーション管理や、障害解析の有用性
ここまでの説明で、現在の複雑化する企業インフラにおいて、「応答遅延」などの障害が発生した際のトラブルシュートの難しさについてはイメージを掴んでいただけたのではないかと思います。今回紹介する NSX ALB には、ロードバランサとしてリソースの効率的な分配を行う機能だけではなく、このような複雑な企業インフラの環境を抽象化し俯瞰的に把握する事を支援する機能が多く実装されています。
NSX ALB の管理ダッシュボードでは、各アプリケーションの状態を表すバーチャルサービスが一覧で表示されており、健全性、パフォーマンスなどの各メトリックの値をもとにスコア化されております。バーチャルサービスはスコアに応じて色分けされており、直感的に各アプリケーションの健全性を把握する事ができます。
<アプリケーションダッシュボード画面>
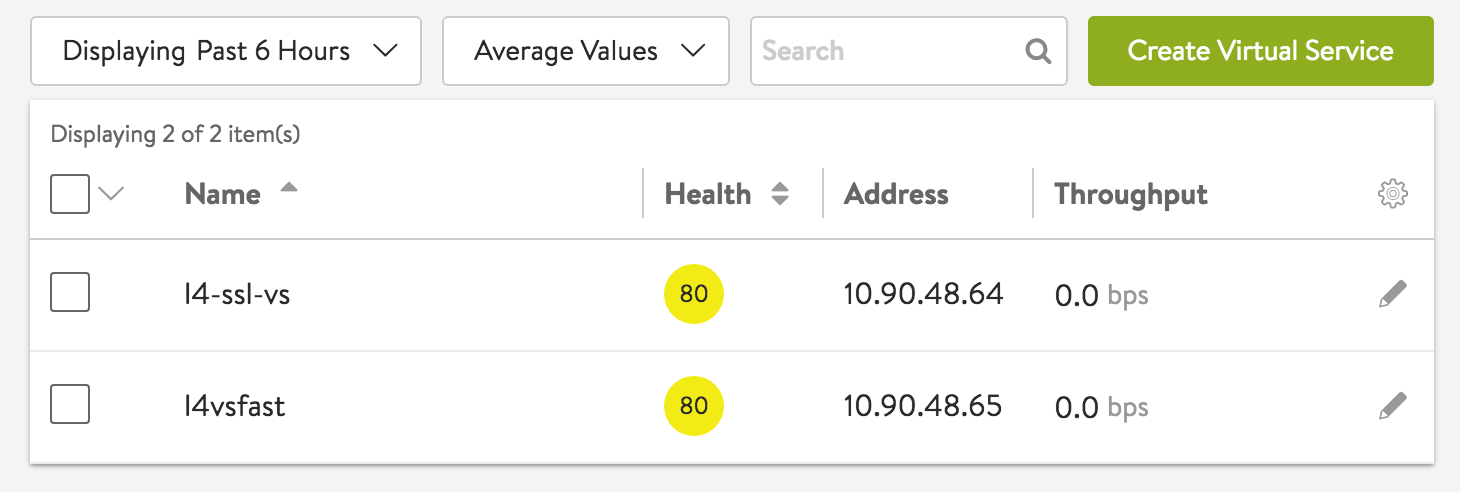
<スコアによるパフォーマンス評価画面>
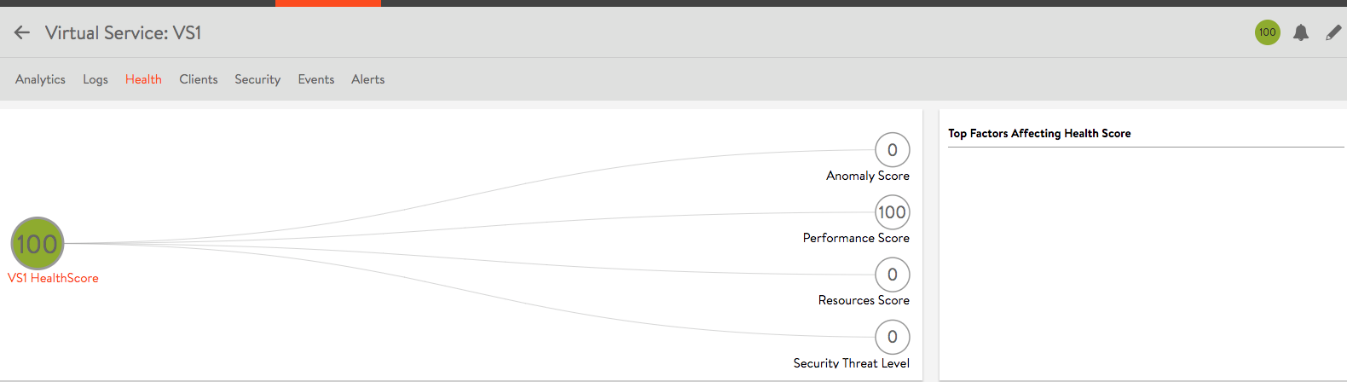
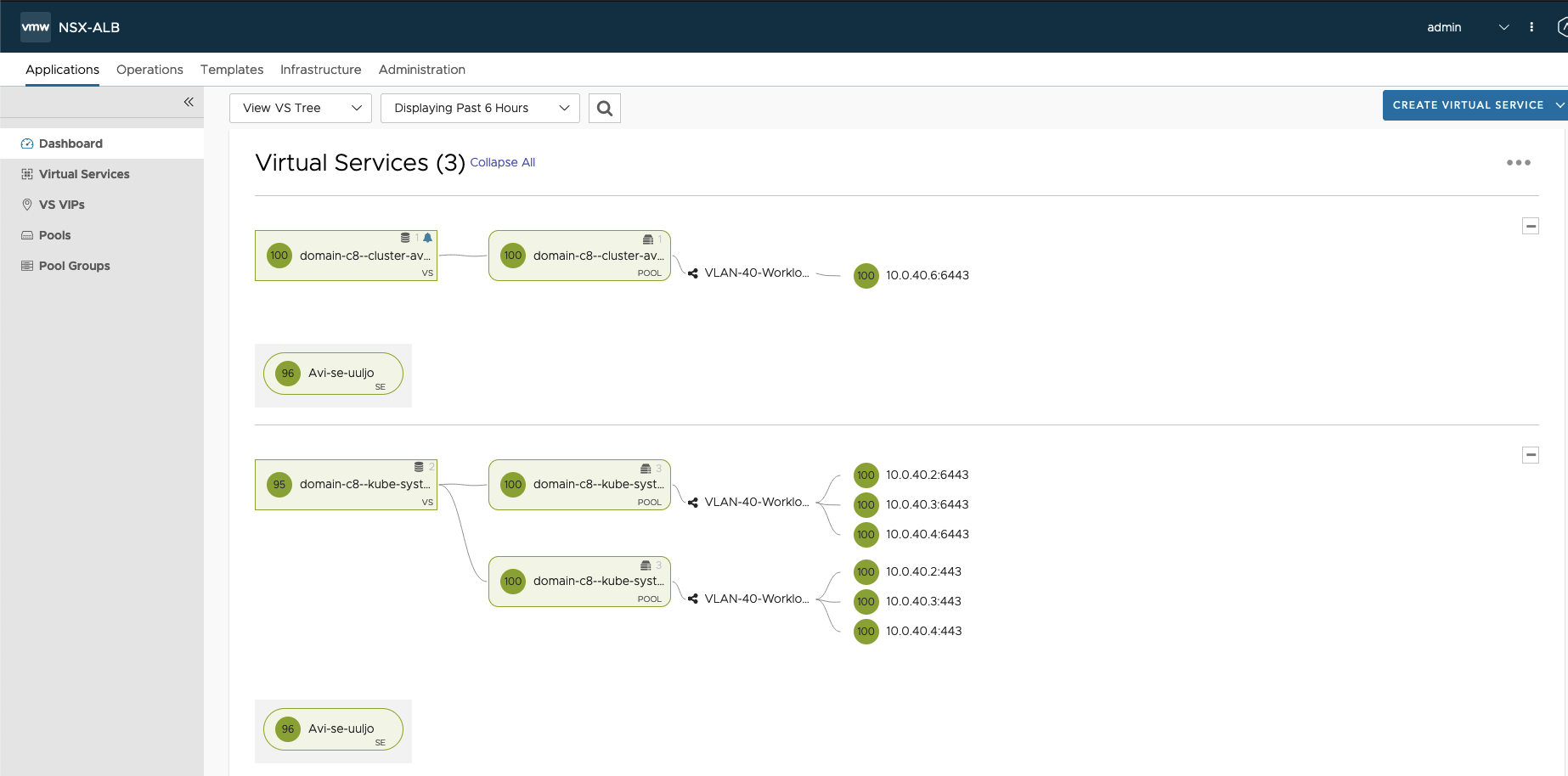
バーチャルサービスは関連するオブジェクト(サービスエンジン、プール、サーバ)と結合されており、各オブジェクトの関係のトポロジーを把握できるようになっております。これにより、トポロジーのどのポイントで問題が発生しているのかについても俯瞰的に把握することができるようインターフェイスが設計されております。
<バーチャルサービスのトポロジー画面>
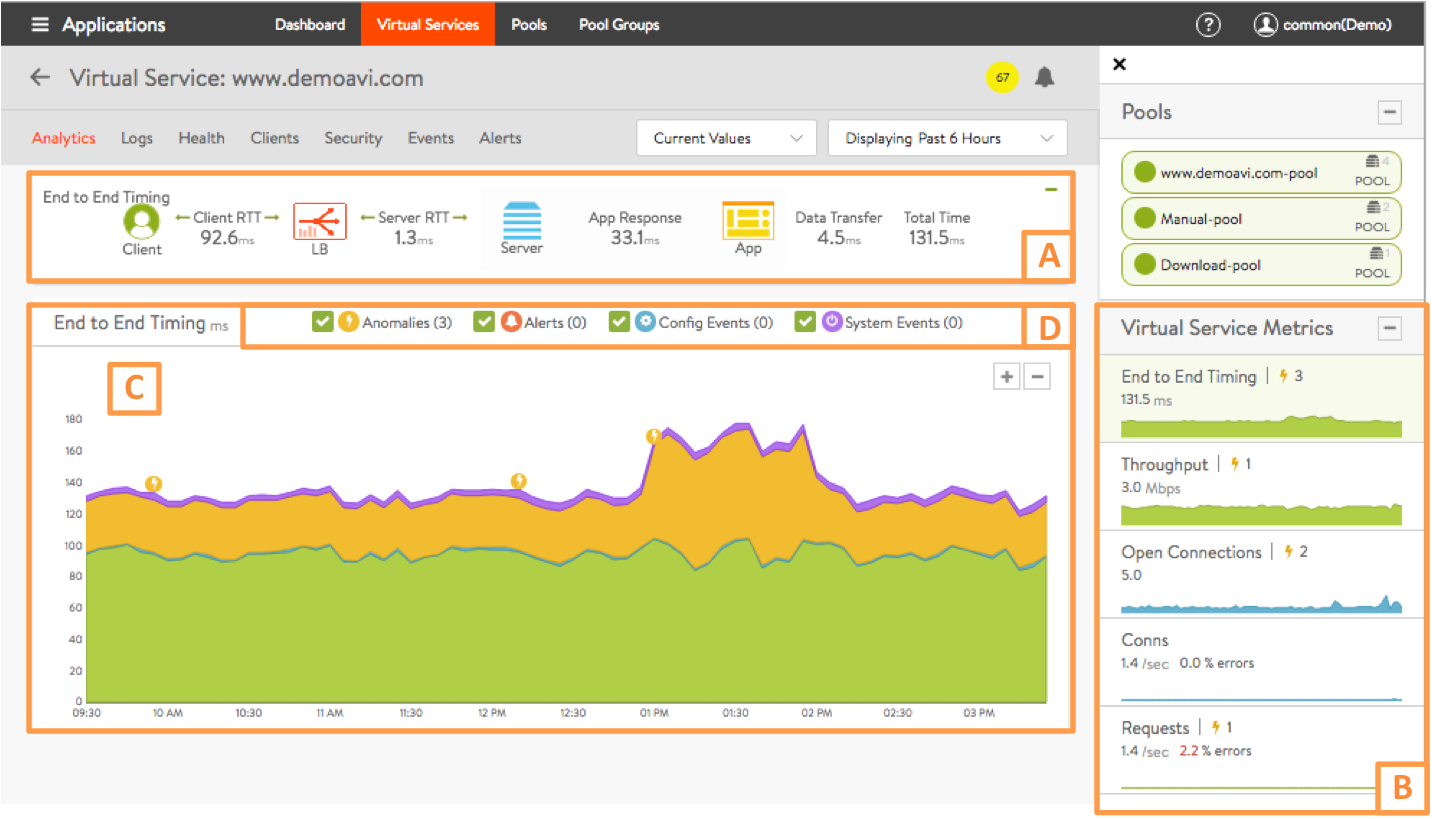
また、トラフィックの解析機能も充実しており、バーチャルサービスを経由したトラフィックがどのポイントでどの程度の時間を要したのかを正確に把握する事が可能です。
<バーチャルサービスアナリティクス画面>
実際の NSX ALB のインターフェイスの操作感については、以下の YouTube 動画を見ていただくとイメージが掴みやすいと思いますのでご興味のある方はぜひご覧いただければと思います。
Demo – VMware NSX Advanced Load Balancer (Avi Networks)
-1.5. 「バーチャルサービスアナリティクス」で取得できるメトリックについて
このように NSX ALB には障害発生時のトラブルシュートを支援するための優れた機能が多数用意されているのですが、ここでは「応答遅延」が発生した際にボトルネックとなっているポイントを特定するために特に役に立つ 「バーチャルサービスアナリティクス」 の機能に焦点をあて、どのようなメトリックの収集が可能であるかについて見ていきたいと思います。
<バーチャルサービスアナリティクスの画面構成>
具体的には以下のような情報を収集する事ができます。
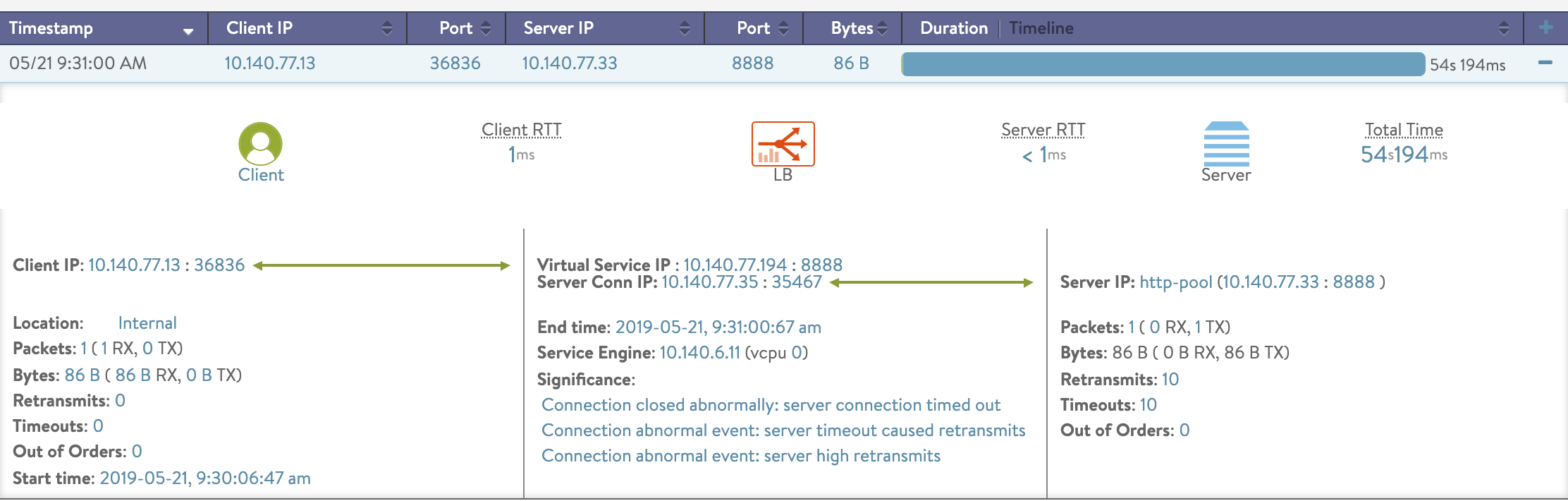
<End to End Timing パネル>
このパネルは、クライアントからサーバー間でのトラフィックの各ポイントでトラフィックの処理に要した時間を表示しています。
- Client RTT:
クライアントからサービスエンジン間で TCP セッションの確立に要した時間
クライアントとサービスエンジン間でやり取りされるラウンドトリップの通信( Syn-Ack に対する Ack のレスポンスタイムなど)をベースに計算されます。 - Server RTT:
サービスエンジンからサーバー間で TCP セッションの確立に要した時間
サービスエンジンからサーバー間のラウンドトリップの通信 ( Syn に対する Syn-Ack のレスポンスタイムなど)をベースに計算しています。 - App Response:
サーバーからサービスエンジンに対してアプリケーションコンテンツの最初のバイト転送が開始されるまでにかかった時間
この値はサーバーからサービスエンジンに対して「コンテンツデータの最初のバイトが転送された時間」から「 Server RTT 」を引く事で LB とサーバー間で TCP のセッションを確立した後に、コンテンツの転送が開始されるまでにどの程度の時間を要したのかを計算しています。 - Data Transfer:
サーバーからサービスエンジン間でコンテンツのデータ転送にかかった時間
サービスエンジンが、サーバーからコンテンツデータの「最後のバイトを受け取った時間」から「最初のバイトを受け取った時間」を引く事で全体のコンテンツデータの転送にかかった時間を計算しています。 - Total Time:
クライアントとサーバー間でセッションの開始からコンテンツの転送の完了までに全体として要した時間。Client RTT、Server RTT、App Response、Data Transfer の全ての値を合計したものが Total Time と計算されます。
<バーチャルサービスメトリック パネル>
このパネルでは各メトリックの統計的な情報を表示します。
- End to End Timing:
この項目は、クライアントから、サーバー間でコンテンツデータの受け渡しが完了するまでのトータルの時間が統計情報として表示されます。指定した期間内のどのタイミングで、コンテンツデータの受け渡しに遅延が発生たのかをチャート形式で把握する事が可能です。 - Throughput:
バーチャルサービスを経由するトラフィックのスループットを mbps 単位で表示します。 - Open Connections:
オープンしている TCP/UDP コネクションの数を表示しています。UDP はステートレスのプロトコルですが、疑似的にセッションを管理する事でコネクションとしてカウントされます。特定の期間のコネクションの増減を時系列で把握する事が可能です。 - Conns:
1 秒間に確立された TCP/UDP のコネクション数 (Connection per Second) の平均値数をカウントしています。
この値はさらに、正常なコネクション (Conns)、確立に失敗したコネクション (Lossy Connection) 、異常終了したコネクション(Bad Connection)にブレークダウンする事が可能です。
※ Lossy Connection は LB からサーバーへ複数回コネクションの確立を試みたがセッションが確立できなかったコネクションを意味します。
※ Bad Connection は強制終了されるなど異常な形で終了されたコネクションを意味します。 - Requests:
確立されたコネクション内でクライアントからのコンテンツのリクエストに対して応答が得られた数(The number of responses to requests per second)をカウントしています。この値は、HTTP レスポンスコード(200、400、500 など)にブレークダウンする事が可能です
2. 「バーチャルサービスアナリティクス」を活用した「応答遅延」に対する障害解析のユースケース
-2.1 障害事例の紹介
さて、これまでの説明で、NSX ALB を障害解析のツールとして使用する事で、どのような情報を収集できるかについてご理解いただけたと思います。この章では、実際の障害発生事例をベースに、「バーチャルサービスアナリティクス」によって得られるメトリックが、どのように問題の分析に役に立つのかを紹介していきたいと思います。
<ケーススタディ>
発生事象:特定の Web アプリケーションに対して、特定の時間帯に大幅なレスポンスの遅延が発生する事象がユーザーから報告された。
調査状況:一次調査として、物理基盤を含む各コンポーネントを調査したがダウン(故障)しているデバイスは確認できなかった。
この事例では、いわゆる「応答遅延」に関する障害が発生しておりましたが、物理基盤上では問題は確認されず、仮想化基盤上に何らかのボトルネックが発生している可能性が疑われておりました。このような事象が発生した場合、やはりロードバランサが疑われる事が多いのですが、ロードバランサがボトルネックとなっているかを特定するためには、クライアントから LB 間の通信、LB からサーバー間 の通信 – サーバーから連携しているアプリケーションサーバー、DB サーバーへの通信など各ポイントの通信状態を把握し、どのポイントにて最も遅延が発生しているかを特定する必要があります。
このような問題を分析するにあたり、NSX ALB に実装されている「バーチャルサービスアナリティクス」の機能がとても有効です。この機能ではバーチャルサービスを経由するトラフィックを記録、分析し、End to End(クライアントからサーバー間)でコンテンツデータの受け渡しが完了するまでに、各ポイントでどの程度の時間を必要としたのかを把握する事ができます。
今回紹介させていただく事例では、「バーチャルサービスアナリティクス」から得られた各メトリックの値は以下の通りとなっておりました。
< End to End Timing >



-2.2 メトリックの値を用いたボトルネックの分析
まずは最初のメトリックを見ていきましょう。
このメトリックの値からどのようなシナリオが想定されるでしょうか。Total Time は 15289 ms となっており、クライアントがコンテンツを受け取るまでに全体で 15 秒ほど時間がかかった事が分かります。提供しているサービスが Web サイトであれば、ページをロードするまでに 15 秒程度かかった事になり、ユーザーは大きなストレスを感じている事が想像されます。Client RTT は 15 ms、Server RTT の値は 3 ms となっており、Client RTT の値が、Server RTT よりも大きいですがどちらも数ミリ秒の範囲内なので影響はないと考えられます。この 2 つの値で遅延が見られない事からクライアントから LB、LB からサーバーまでの TCP コネクションの確立においてはそれほど時間がかかっていない事が分かります。際立った値として App Response の値が 15261 ms となっており、このポイントにおける遅延が Total Time が伸びている最大の要因である事が分かります。
App Response は、サーバーからサービスエンジンに対してコンテンツデータの最初のバイトが送信された時刻から、Server RTT を引く事で計算されますので、LB とサーバー間で TCP のコネクションが確立された後、サーバー側でコンテンツが生成され転送が開始されるまでにかなりの時間を要しているという状態が推測されます。Data Transfer は 10 ms となっておりますので、コンテンツデータの転送が開始されてから完了するまでには時間はかかっていない事が分かります。
それではもう一方のメトリックを見ていきましょう。
この情報からは、事象が発生した時点でのスループットや確立しているコネクションの統計情報を確認する事ができます。End to End Timing は 15000 msを超えており、やはりクライアントがコンテンツを読み込むまでに時間がかかっている事が分かります。スループットの値に関しては特に問題は見られません。また、Open Connections の値が 19226 と大きいですが、アプリケーションによっては複数のコネクションを要求するものあり、設計上想定される規模となるため許容できる範囲です。Conns の値で errors もカウントされていない事から、TCP コネクションにおいては問題は発生していないようです。
もし、Open Connections の値が増加するに比例して、Conns の errors の割合が増える場合には、LB とサーバー間での TCP コネクション上でエラーが多発している状況と考えられますので注意が必要ですが、この事例では Conns でカウントされているエラーカウントは 0.0 % であるため TCP コネクションの確立においては問題発生していません。Request 上では 0.8 % のエラーがカウントされていますが、極めて低いレート(1 %に満たない)なので、このエラーがレスポンス低下の直接的な原因ではなさそうです。
-2.3 メトリックの分析から導き出された結論
これらのメトリックの値を総合的に考えると、クライアントからサーバーまでのネットワークのデータ転送においては問題がなく、サーバー上でコンテンツデータを生成するための処理に時間がかかっている可能性が最も高いと判断できるかと思います。
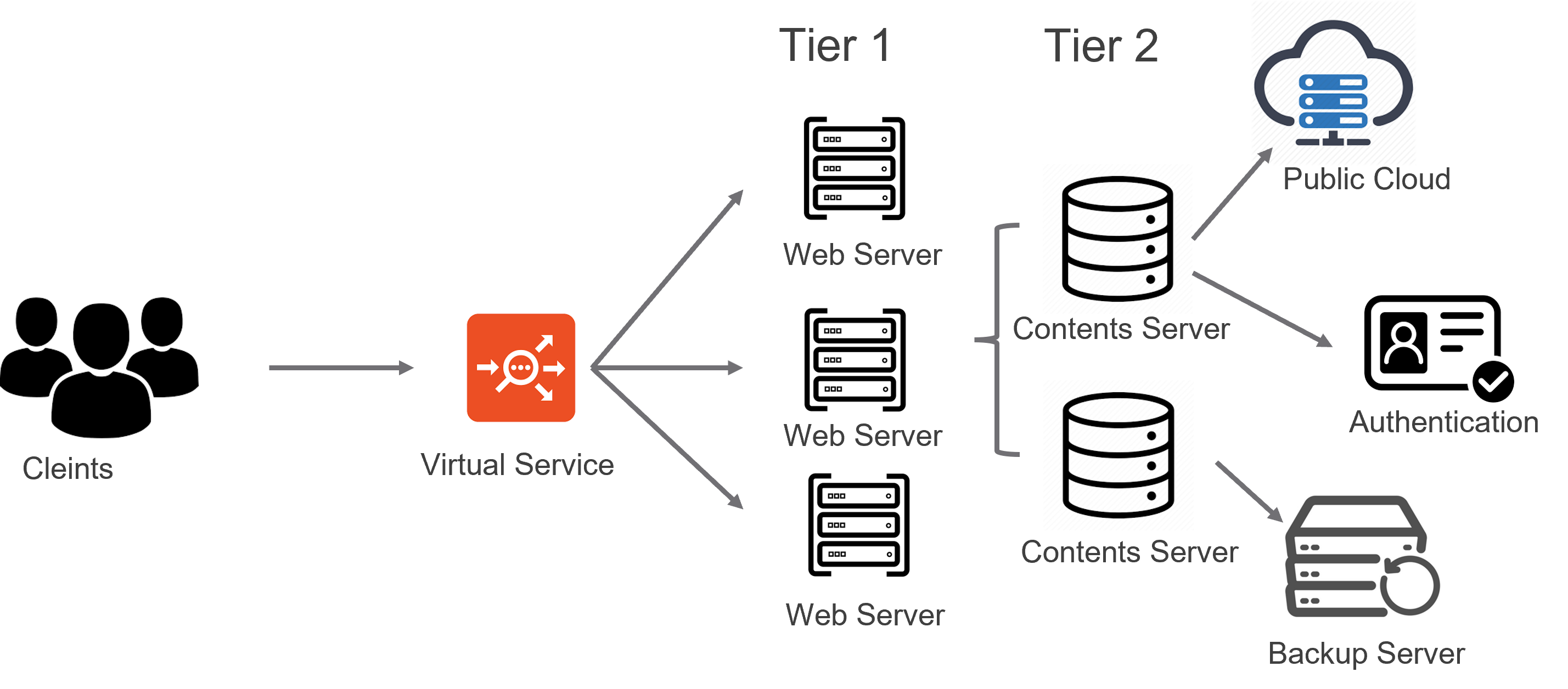
このようなケースの場合、一般的に考えらえるシナリオとしては、アプリケーションサーバーが Tier 構成となっている場合です。このような構成をとる場合、LB と TCP コネクションを確立しているフロントのサーバー単体ではコンテンツを生成する事が出来ず、バックエンドにあるコンテンツサーバーやストレージと連携する必要があります。この内部的な連携において何らかの問題が発生している場合、コンテンツの生成に想定外の時間がかかる場合があります。
この事例においては、「バーチャルサービスアナリティクス」から得られた各種メトリックの情報をもとに、クライアント – ロードバランサ - サーバー間の通信には遅延が発生していない事が明確に把握できたため、その後の調査対象をフロントサーバーの背後にあるバックエンドのシステムへと絞り込む事ができました。
<Tier 構成のイメージ>
おわりに
今回のケーススタディでは「バーチャルサービスアナリティクス」を用いた障害解析の事例について紹介させていただきました。NSX ALB の「バーチャルサービスアナリティクス」から得られる各メトリックを分析することにより大幅に調査範囲を絞り込むことができるという点をご理解いただけたのではないかと思います。
「バーチャルサービスアナリティクス」については、以下の YouTube 動画にてデモンストレーションを実施しておりますので興味のある方は是非ご覧いただければと思います。
How to Leverage Advanced Application Analytics for Virtual Services
また、NSX ALB のインターフェイスを実際に触ってみたいという方は、以下のハンズオンラボもご用意しておりますのでぜひご活用ください。
VMware Hands-on Lab
https://www.vmwarelearningplatform.com/HOL/catalogs/catalog/
VMware NSX Advanced Load Balancer (Avi Networks) – Getting Started (HOL-2237-01-NET)
VMware NSX Advanced Load Balancer (Avi Networks) – Global Server Load Balancing (HOL-2237-02-NET)
VMware NSX Advanced Load Balancer (Avi Networks) – Web Application Security (HOL-2237-03-NET)
VMware NSX Advanced Load Balancer (Avi Networks) – with Kubernetes (HOL-2237-04-NET)



