

VMware Aria Operations for Application(旧製品名 Tanzu Observability。以下、AoA または Aira OA) は、包括的なオブザーバビリティを実現するマルチクラウド管理ソリューションです。監視対象からメトリック、ログ、トレースの各情報を取得し、迅速な問題の特定、解決を目的とする SaaS 型プラットフォームです。オブザーバビリティにはメトリック、トレース、そしてログといった分類がありますが、AoA もこの3つの要素を提供します(現在、ログ機能は Beta リリースでの提供)。なお、AoA の30 日間フリートライアルはこちらより提供されておりますのでご活用いただければと思います。
図1Aria Operations for Application の3つの要素
TKO Blog シリーズ「クラウドからオンプレまでフルスタックのオブザーバビリティを提供する VMware Aria Operations for Applications とは?」では、AoA の概要を紹介しました。
AoA 概要に続くこの記事では、AoA のベースとなるメトリック監視を中心に AoA の使い方とオブザーバビリティの主な対象となる Kubernetes の監視について以下の通りご紹介したいと思います。トレースとログについては別の機会でご紹介したいと思いますが、双方とも共通で使用する機能もありますので、ここで基本を押さえておけば理解はしやすいと思います。
- 主な機能とデータフロー
- Proxy とエージェント
- クエリとダッシュボード
- アラート
- Kubernetes との統合
- Kubernetes 統合の応用例( Prometheus 連携と HPA )
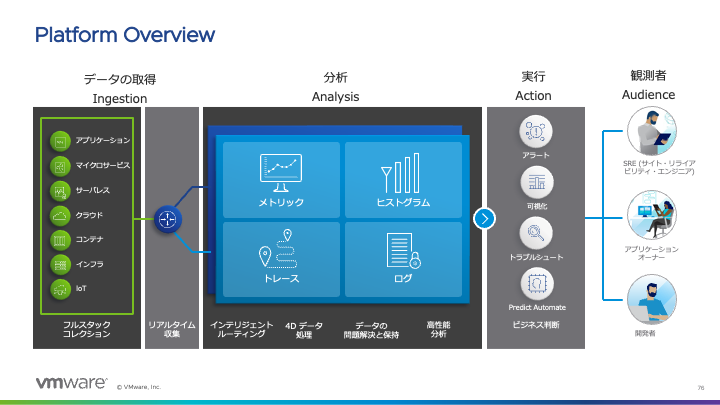
図2 プラットフォーム概要図
1. 主な機能とデータフロー
AoA の主な機能は、①エージェントならびに Proxy を介したデータ取得(メトリック、トレース、ログ)、②取得した各データを分析する際に使用するクエリによるダッシュボード、③分析後に実行されるアラートなどのアクションです。
AoAのデータフローですが、ここでは主となる5つのデータフローを示しています。
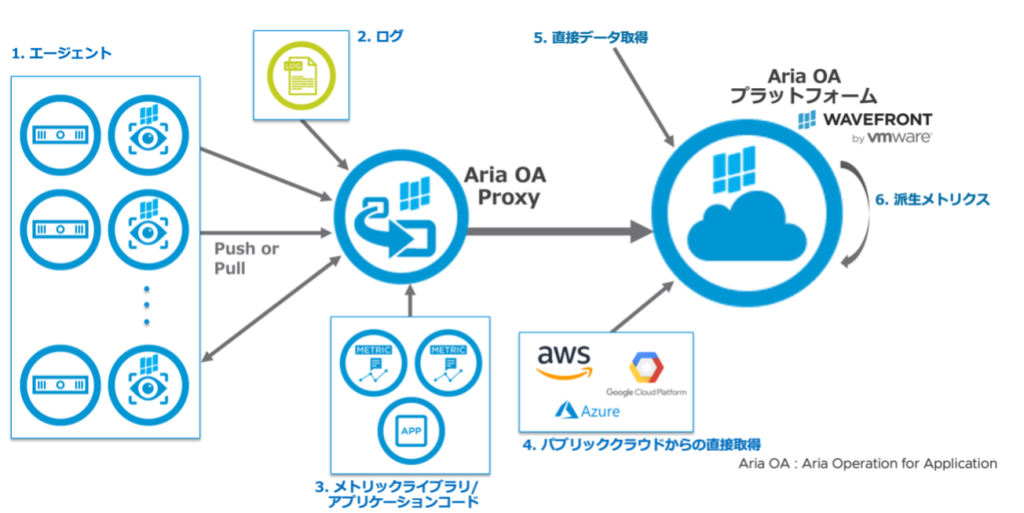
図3:Aria Operations for Applications のデータフロー
様々な監視対象からデータを取得することが可能ですが、通常のメトリックデータ取得にはデータ取得用の 1. のエージェントを使用します。ただし、AoAでは独自仕様のエージェントは使用せず、主に Telegraph Agent を使用します。また、StatsD や CollectD などのオープンソースのエージェント、Prometheus からのデータを取得や、さらに取得したメトリックデータを加工して派生データとして利用することが可能です。
また、Logs (Beta) によりログデータを fluentd を介して取得することが可能です。これは単なるログの取り込みではなく、ログをリアルタイムで解析し、重要なメッセージを検知し、ログから指標となるデータを引き出すことが可能となります。ログそのものをすべて管理することによる大容量のストレージの管理コストを削減し、実際に知りたい情報、例えば「1秒間あたりのトランザクションが減少している」ことを特定することを可能にします。
Spring Boot Integration ではアプリケーションに追加できるライブラリにより、AoA のメトリック用にコードを追加しなくてもメトリックを取得することが可能となります。また、分散トレースにより、アプリケーションがリクエストを処理する際に実行される作業の流れを追跡し、コード内のエラーやパフォーマンスの問題を発見することができます。トレースのために OpenTracing とOpenTelemetry をサポートしています。
以上は、AoA Proxy を介してデータを取得しますが、AoA Proxy を使用しない場合もあります。AWS や Google など主要なクラウドとの統合で、この場合は AoA Proxy を経由せず直接パブリッククラウドに接続しデータの取得を行います。
AoA Proxy を使用しない場合のもう一つは、直接データ取得としてコマンドラインなどを使用して直接データを送信する方法です。この場合、Wavefront service へデータ送信し、受信確認のテストを行いたいときなどにも使用できます。
|
直接データ送信例
また、Wavefront REST API を使用し、レポートやアラートの作成、クエリの作成、データへのクエリ、レスポンスの取得など、さまざまな作業を行うことが可能です。
2. Proxy とエージェント
AoA Proxy はエージェントからのデータを集約し、AoA サービス(プラットフォーム)にデータを送信します。パブリッククラウドでは AoA Proxy を介さなくてもエンドポイントからのデータ取得は可能ですが、特にオンプレミス環境を監視する場合はほぼ必須と考えてよいかと思います。
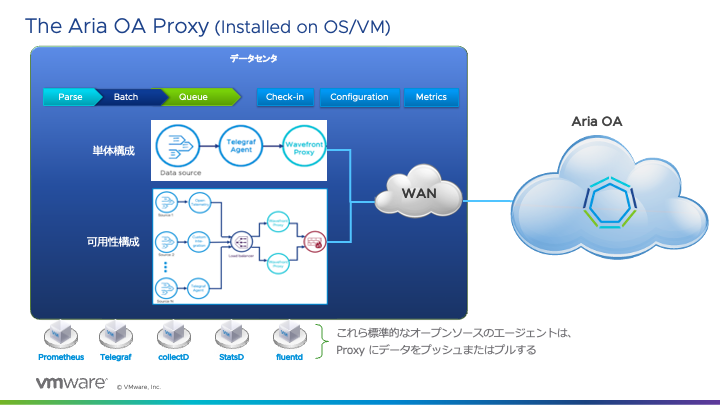
図4 Aria Operations for Applications Proxy
データ送信経路を AoA Proxy に集約することによって単にファイアウォール上の構成をシンプルにする効果だけでなく、AoA Proxy は取得したデータを一時的にキャッシュし、例えば処理データが一時的に急増した場合でも、スパイクを軽減しより安定したデータ送信を可能にしています。また、Telegraf Agent と複数の AoA Proxy の間にロードバランサを追加し、AoA Proxy の可用性・スケーラビリティを確保する構成を取ることもできます。
Proxy の設定
さて、実際に Proxy を設定してみたいと思います。AoA Proxy サーバの要件はこちらを参照してください。ここではスタンドアロンでの AoA Proxy サーバを設定しますが、Kubernetes 環境では Kubernetes Cluster 毎に AoA Proxy Pod を展開する構成を取ります。こちらについては後ほど説明します。
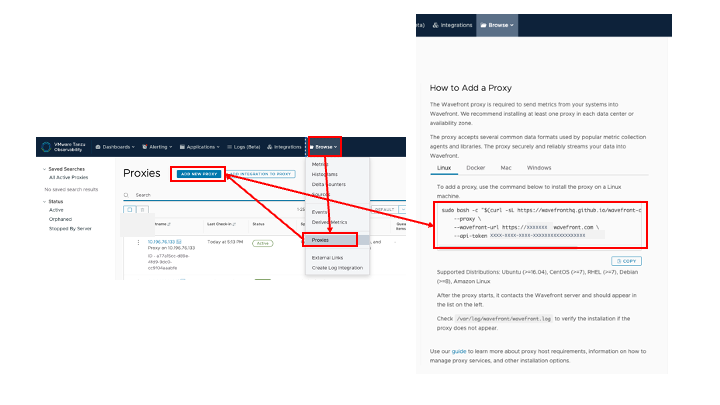
図5 Proxy 設定用コマンドラインの表示
AoA に管理者のアカウントでログインすると、一番右のプルダウンメニューの「Browse」から「Proxy」を選択します。Proxy の画面上で 「Add Proxy」をクリックすると、AoA Proxy の設定方法と共にインストール用のコマンドラインが表示されます。AoA Proxy を立てる環境に合わせて使用しますが、これはアカウントに紐付いた一意の API Token も含まれているのでこのままコピーして使用します。ここでは Ubuntu OS の仮想マシンを作成し、そこで先程コピーしたコマンドラインで AoA Proxy をインストールします。
|
Proxy のインストール
インストールが完了した後、wavefront.conf で AoA Proxy の設定を行いますが、AoA Proxy からの送信先 AoA サーバの指定はすでに上記コマンドラインでのインストール時に指定しているため、基本的には AoA Proxy の設定もデフォルトのままで使用できます。詳細設定を追加する場合は、この wavefront.conf で設定を追加しプロセスを再起動します。
prefix 設定は、この AoA Proxy で集約したすべてのメトリックデータに、文字通り prefix 情報を付加する設定ですが、これもこの wavefront.conf で設定できます。メトリックを他の Proxy から取得した同様のメトリックと明示的に区別したい場合など、この prefix で一意に特定することができます。
|
wavefront.conf の設定
その他、AoA Proxy のオプション設定はこちらで確認できます。
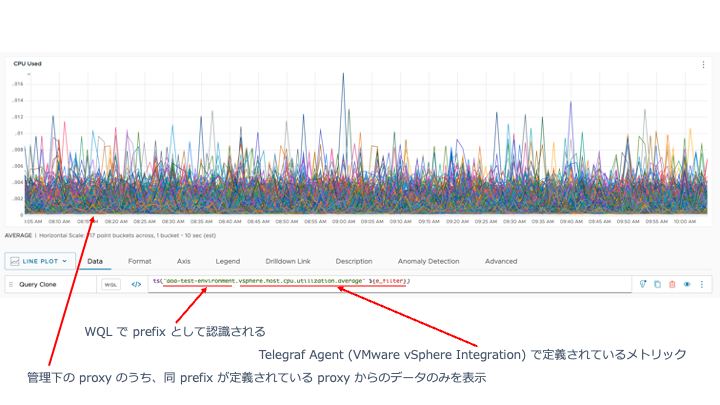
図6 Proxy 経由でメトリックを取得
エージェントの設定
次に、データを取得するエージェントです。vSphere 環境を使用する上では最も基本的な Telegraf エージェントである、VMware vSphere Integration を用いたエージェントによる設定を見てみましょう。もちろん、各Telegraf エージェントはそれぞれ独立して使用できますので、 vSphere 環境上であっても、監視対象をアプリケーションなどに限り、vSphere 自体のメトリック監視を AoA で行わない場合は VMware vSphere Integration の使用は必須ではありません。
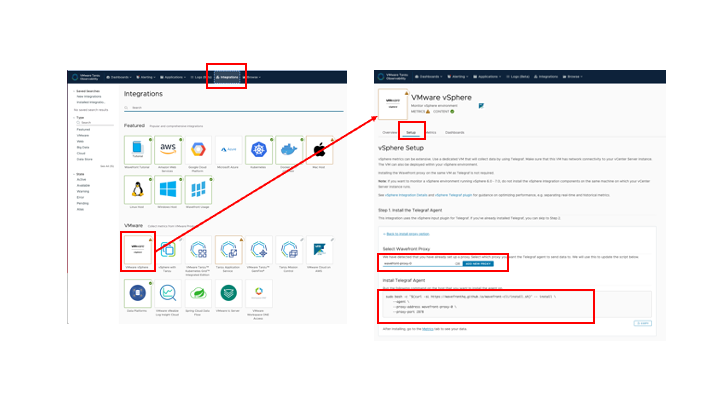
図7 vSphere integration
新たなエージェントを追加する際は、AoA にログイン後 「Integration」 タブを選択し、必要な Integration(ここでは VMware vSphere)→ 「Setup」 タブと進むと、実際のセットアップ手順が表示されます。ここで、まだ AoA Proxy (Wavefront Proxy) を設定していない場合は、「Add New Proxy」から進んで先程の Proxy インストール手順を実施します。
すでに Proxy 設定を完了している場合は、自身の Proxy をプルダウンのリストから選択すると、「Install Telegraf Agent」にその設定を含むインストールコマンドラインが生成されます。これを実際に Telegraf Agent をインストールするサーバ上にコピーペーストしてTelegraf Agentのインストールを行います。Teregrafのサーバは先程の AoA Proxy サーバと併用することも可能です。以下は実際の実行結果です。最後に Telegraf のインストールが完了し、Telegraf Agent プロセスのリスタートのメッセージが出力されれば完了です。
|
Telegraf Agent のインストール
インストール後、Telegraf Agent 用の設定ファイル /etc/telegraf/telegraf.conf で設定を行うことが可能です。デフォルトのままでも問題ありませんが、ここでポイントタグを設定しておくと後々ダッシュボード上でクエリ操作をする際に便利です。 [global_tags] の項目に key=”value” 形式で任意のタグを設定します。これにより、この telegraf エージェントで取得するすべてのデータにはここで設定したタグが付加されますので、複数の telegraf エージェントで管理を行っている場合、このタグを使ってその監視対象を指定するなどの操作が可能になります。以下はその設定例となります。ここでは [global_tags] でenvironement = “aria-lab” としてポイントタグを設定しています。
|
telegraf.conf の設定例
また、監視対象となる vSphere 環境用の設定を /etc/telegraf/telegraf.d/vsphere.conf として作成します。設定内容は 「Setup」 タブ→「Step2. Configure vSphere Input Plugin」の設定をコピー&ペーストして使用します。この中で、監視対象の vCenter Server の URL ならびにその管理者用の username/password は、実際に使用する設定値に変更します。
さらに、実際に取得するメトリックを設定しますが、設定を特にしなければすべての取得可能なメトリックを取得しますので、基本的にはデフォルトのままで問題ありません。Telegrf エージェント、AoA Proxy の設定が完了し、Telegraf エージェントのプロセスを再起動すると、メトリックの取得が開始されます。しばらくすると事前に定義されたクエリに従って、vSphere 用のダッシュボードは以下のように表示されます。
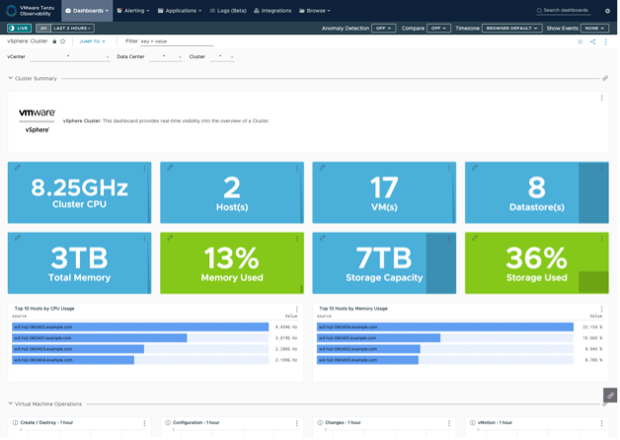
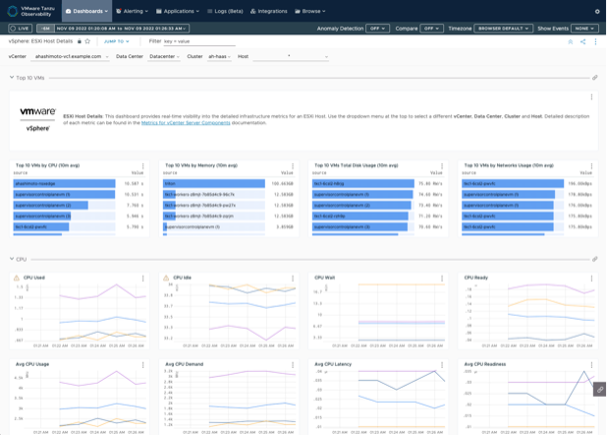
図8 vSphere Integration ダッシュボード
3. クエリとダッシュボード
AoAの大きな特徴の一つが高機能クエリ言語である Wavefront Query Language (以下、WQL)です。AoA Proxy と監視対象へのエージェントの設定を行い、データを AoA プラットフォームに送信できるようになった後は、WQL を使用してデータから必要な情報を抽出できます。グラフ表示に使用されるクエリとアラートには、このクエリ言語を使用します。Prometheus のクエリ言語である PromQL に近い言語であり、PromQL に慣れた管理者でも使い易く非常に強力です。
また、AoA ダッシュボードでは WQL に加えて PromQL をそのまま使用することも可能で、さらにその PromQL で記述したクエリを WQL に変換することも可能です。これにより、すでに Prometheus で PromQL での操作に慣れている管理者の AoA へのスムーズな移行を可能にします。

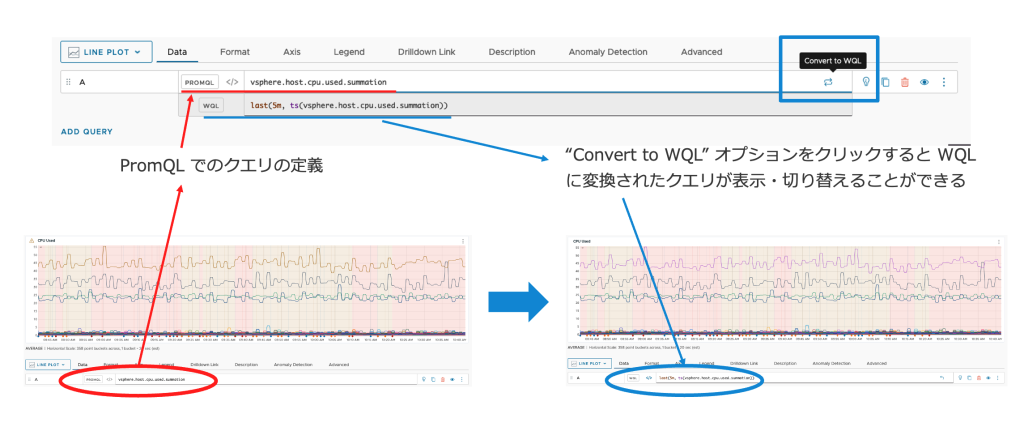
図9 WQL と PromQL
なお、WQL が選択されているときにユーザーが PromQL クエリを入力した場合、またはその逆の場合、クエリエディターはクエリを解析せず、構文エラーを表示します。
WQL によるクエリは主に基本クエリと付加機能の2つ機能で構成されています。基本クエリでは、時系列、ヒストグラム系列、イベント、さらに分散トレーシングで使用されるトレースおよびスパンがあり、それぞれ特定のタイプのデータを記述します。最も使用されるのは時系列表現で “ts” (time series) で表記します。この基本クエリによるデータ抽出に加え、付加機能によりそのデータを加工することで、管理者が望むデータ表示を行うことができます。
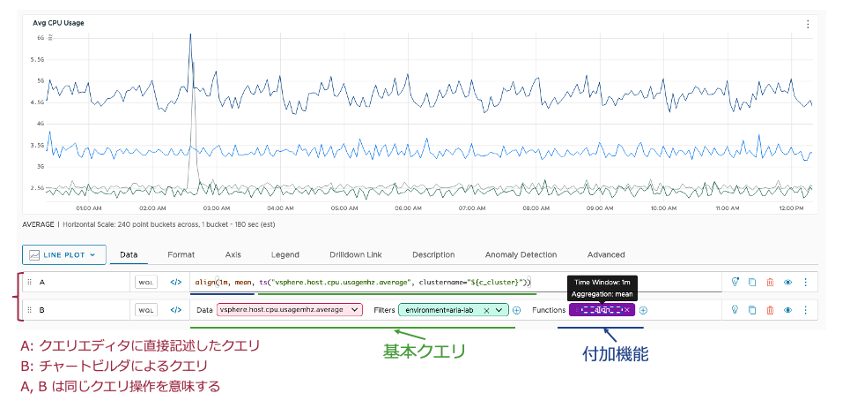
図10 チャートビルダ
ここでは、基本クエリとして ts() を使用して env=”prod” でタグ付けされた環境の “clusters*” に該当する各クラスタにおける CPU 利用率の1分間平均のメトリックをクエリし、付加機能を使用してそのメトリックをさらに 10 分間での平均値でメディアンに加工する、というクエリを示しています。
また、クエリはクエリエディタで一から記述する方法の他に、クエリビルダに切り替えてプルダウンメニューで構成していくことも可能です。
次に、必要なデータを適切に表示させるために必要なのがタグです。1つ目が先程 Telegraf エージェントのところで説明したした ポイントタグです。AoA Proxy のプリプロセッサルールとして、またはTelegraf エージェント設定の [global_tag] で設定することで、Proxy ないしは Teregraf エージェントで処理されるデータに対して、key = value 形式でのタグの追加が可能です。Telegraf エージェント設定の [global_tag] で environment = “aria-lab” と設定しましたが、このように、WQL でメトリックをクエリする際に指定することで、このタグを持つ Telegraf エージェントのメトリックに範囲を絞りをクエリをかけることができます。
2つ目がオブジェクトタグで、各オブジェクト毎に、ソースタグ、アラートタグ、ダッシュボードタグ、イベントタグが含まれます。AoA のメトリックには、ソース名が含まれ、このソース名を使用してをフィルタリングする場合は、ソースタグが有用です。
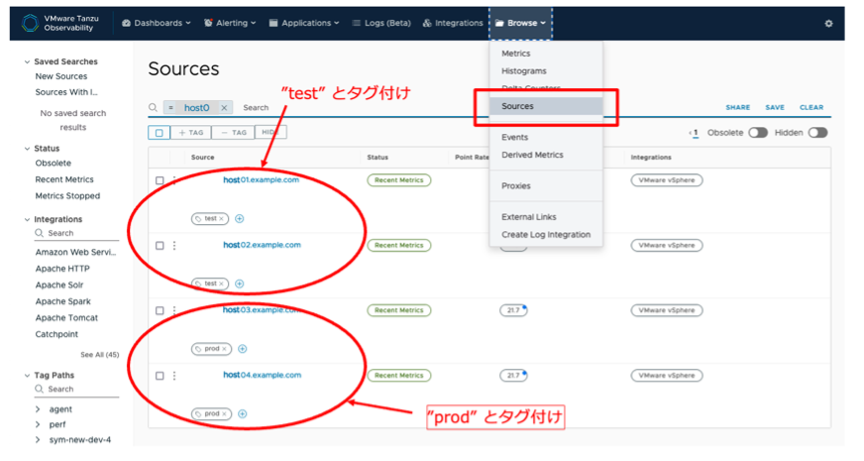
図11 オブジェクトタグ
これはホストや VM といったデータソースを指定し、そのデータソースのみのメトリックを表示させるために使用するタグです。これは、ポイントタグとは異なり、データソースに対して直接タグ値を割り当てます。個別のグルーピングが必要な場合に使用し、例えば全て同じ構成の application サーバが複数 VMとして展開されている際に、一部は test 用、一部は production 用、なとどの区分をタグ付けし、そのタグによりグループ分けされた VM ごとのメトリックを表示させるといった操作を行う際に使用します。
それぞれのタグは、ダッシュボード上で必要なデータを適切に取得・表示させるためには必須の機能と言ってよいと思います。
4. アラート
アラートとは、指定された期間内に予め設定した条件が真または偽と判定された場合に通知される、条件と対象のセットです。条件はクエリのところで見た、ts()によるクエリと演算子を使用して記述します。
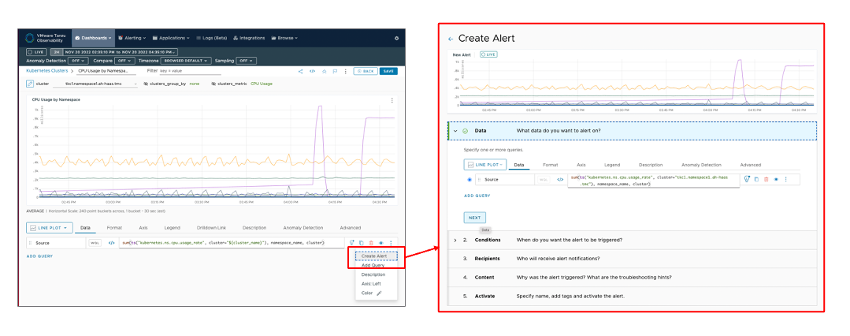
図12 クエリのメニューからアラートの作成
アラートは [Alerting] プルダウンメニューの「Create Alert」などから一から定義することも可能ですが、ダッシュボードの監視しているメトリックのクエリのメニューから、そのクエリ定義を対象とするアラート作成を直接行うことが可能です。
この例は、Kubernetes の Namespace 毎の CPU usage を表示しているダッシュボード上から、「Create Alert」を選択し、「Create Alert」画面にて、直接この CPU usage に Alert 条件を定義してアラートを作成しています。
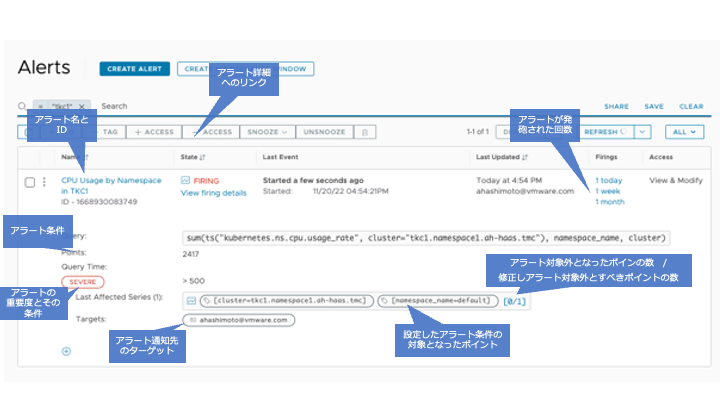
図13 作成されたアラート
ここでは Namespace 毎の CPU usage が 500mllicore 以上が 1 分以上続いている場合に SEVERE のアラートを上げる設定をしています。アラート通知先のターゲットとしてメールアドレスが指定されていますが、他に PagerDuty や VictorOps などのページャーサービス、Slack などのコミュニケーションチャネルなど、さまざまなタイプのターゲットに送信できます。また、自動修復スクリプトの実行など、任意のアクションを設定することができます。さらにアラート詳細へのリンクをたどると、AoA により判断されたより関連の強いソースやポイントタグのリストも確認できます。
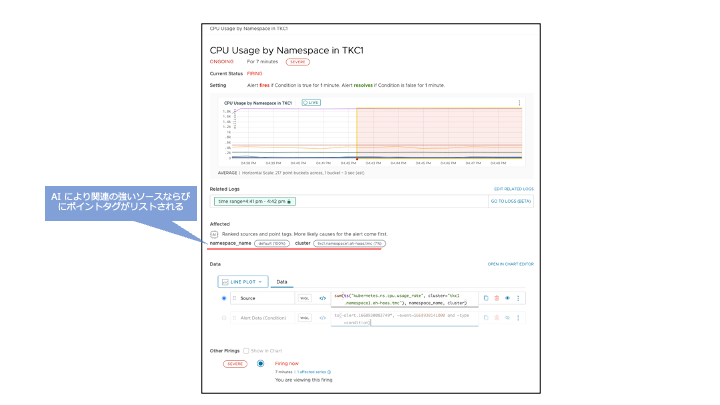
図14 アラート詳細画面
アラート作成時にアラート条件の設定を行う際、実際にその条件でアラートが発行された場合をテストすることができます。チャート内の薄い赤地になっている部分は、対象のメトリックがアラート条件(ここでは、「Namespace 毎の CPU usage が 500mllicore 以上が 1 分以上続いている」)を満たし、アラート発報後もその状態であることを示しています。一旦、アラート解除条件になった場合、この状態も解除されます。
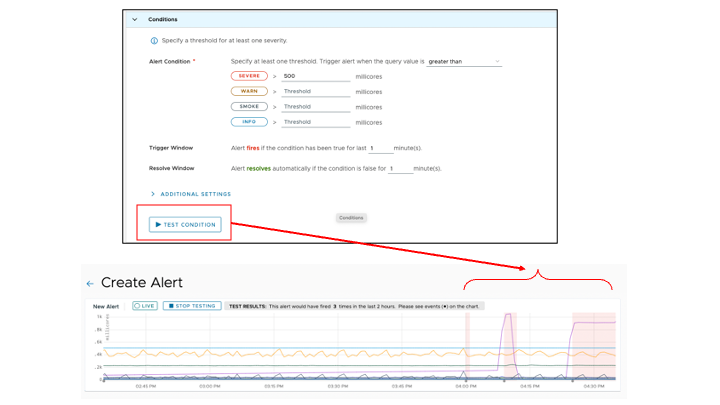
図15 アラートのテスト
5. Kubernetes との統合
Kubernetes はその上で動作するアプリケーション Pod が動的に作成、削除される場合もあり、従来の監視対象をある程度固定した静的なモニタリングだけでは不十分で、オブザーバビリティが必要であると考えられてきております。AoA も Kubernetes 環境のオブザーバビリティを提供する機能を拡充しております。ここではまずその導入である、Kubernetes 環境そのものの統合方法 (Monitor and Scale Kubernetes with Wavefront) について触れたいと思います。
Kubernetes 環境用のデータフローとしては主に2つの方法があります。
一つは Prometheus との連携 (Prometheus Integration) を行い各 Kubernetes Clusterに展開されている Prometheus からデータを取り込む方法です。
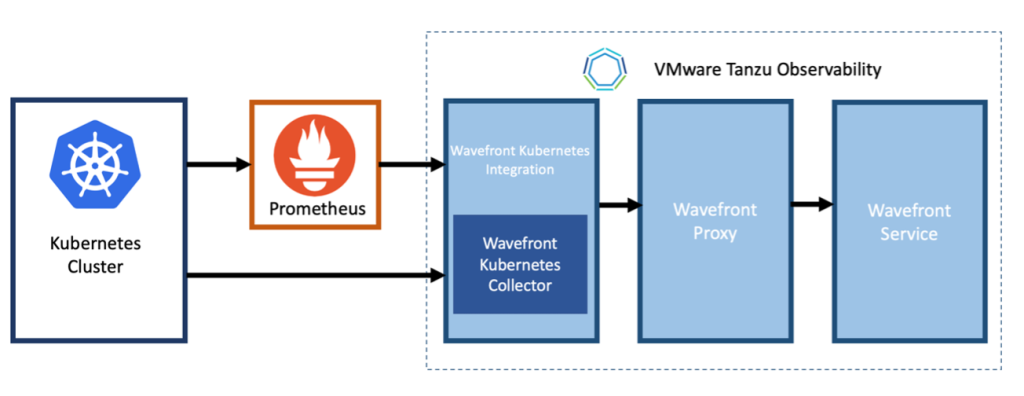
図16 Kubernetes との統合
Prometheus は Kubernetes 環境の監視のデファクトとなっているため、すでに既存の環境で使用されている場合も多いかと思いますが、そういった場合にすぐに適用できます。これはさらに2つの方法があり、一つは Telegraf Agent がPrometheus HTTP エンドポイントからスクレイピングを行ってメトリックを取り込み、Wavefront Format に変換する方法と、2つ目は、Prometheus Storage Adapter for Wavefront を使用し、Prometheus から AoA Proxy にデータを送る方法です。
また、Prometheus を経由せず Kubernetes 環境を監視する方法は、Wavefront Collector for Kubernetes を使用する方法です。これは、Kubernetes 環境に Helm でインストールする、または Tanzu Mission Control (TMC) を使用している場合は TMC の管理コンソールの Kubernetes Cluster 管理画面から AoA を有効化し使用可能となります。TMC 上で管理している場合は、Kubernetes Cluster の管理画面から直接 AoA の API トークンを登録することで、管理対象の Kubernetes Cluster に Wavefront Collector for Kubernetes を展開し、データの取得を開始します。
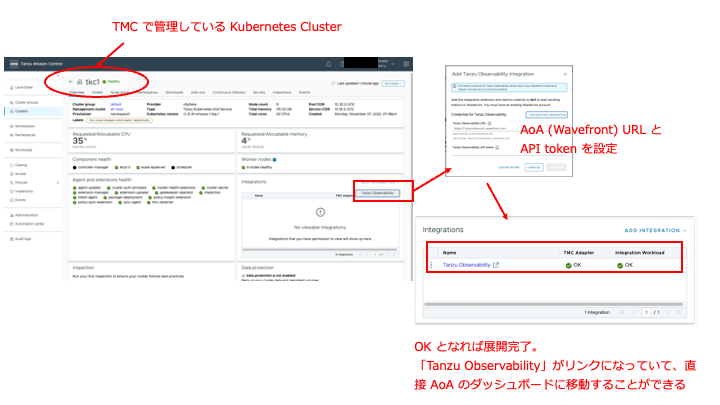
図17 Tanzu Mission Control から Kubernetes 連携
Wavefront Collector for Kubernetes を展開後に Kubernetes Cluster を見てみると、Collector 用に加えて Proxy Pod などが展開されていることがわかります。Wavefront Collector for Kubernetes は、Kubernetes Cluster 毎に Proxy を展開し AoA サーバにデータの送信を行っています。
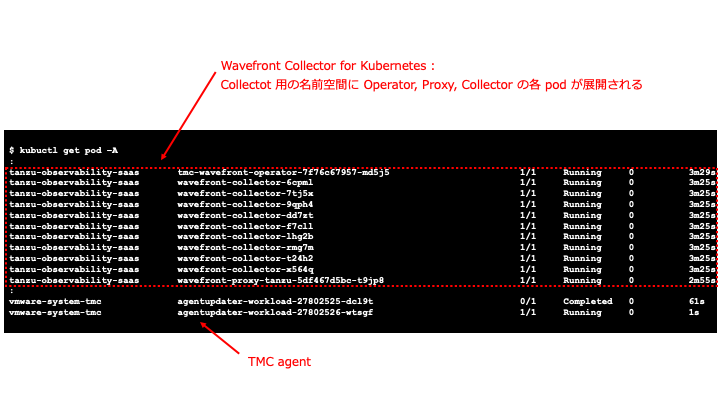
図18 Wavefront Collector for Kubernetes の展開
Wavefront Collector for Kubernetes による各メトリックの取得だけでなく、階層化されたダッシュボードならびに Troubleshooting ダッシュボードが使用可能となりますので、ドリルダウンなどで根本原因の特定作業が可能です。
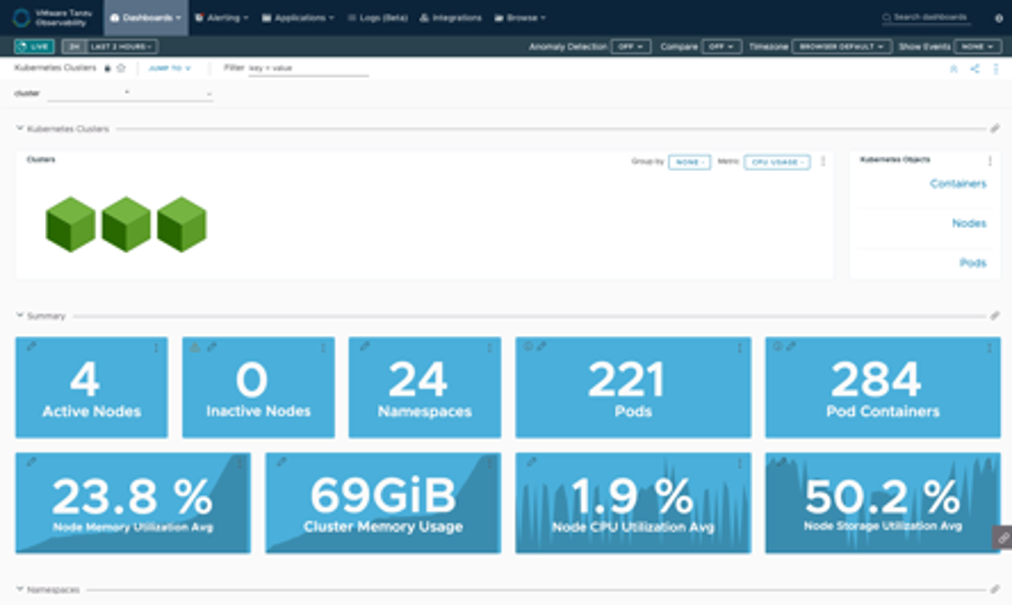
図19 Kubernetes 用ダッシュボード
これらの取得方法を組み合わせて通常の Kubernetes メトリックは Wavefront Collector for Kubernetesを介して、それ以外の外部メトリックは Prometheus を介してデータ取得する構成も可能です。
6. Kubernetes 統合の応用例( Prometheus 連携と HPA )
ここでは、Prometheus でメトリック取得を行っている Kubernetes 機械学習基盤の推論サーバ環境を、AoA で統合監視する応用例をみてみたいと思います。
機械学習基盤はその計算用アクセラレータとして NVIDIA GPU が使用される場合が多く、その GPU リソースの使用状況を含めた監視が必要です。先程も申し上げたとおり Prometheus は Kubernetes 環境の監視のデファクトとなっているため、様々なベンダーが Prometheus にデータを取り込むための Exporter を提供しています。NVIDIA 社も GPU 監視用の Exporter を NVIDIA DCGM Exporter として提供・サポートしており、Kubernetes 環境用の GPU Operator をインストールするとデフォルトでインストールされるため、容易に監視ツールとして使用することが可能です。一方で、Prometheus はその拡張性やマルチテナント含めた統合監視機能では劣っている面があり、この環境を AoA と連携させ統合監視を行うことで、そのデメリットを補うことができます。
ここでは、機械学習基盤の推論サーバ(NVIDIA Triton Inference Server)をApplication Pod として展開・動作させている Kubernetes Cluster 環境において、Prometheus Exporter で GPU メトリックを取得・監視を行っているものとします。これを Prometheus Storage Adapter を介して AoA に取り込み、監視を行ってみたいと思います。
さらに、この推論サーバ Pod は負荷に応じてスケールアウトさせる構成を取ることができますが、AoA で取得した GPU の負荷のメトリックを Horizontal Pod Autoscaler Adapter を介してHorizontal Pod Autoscaler (HPA)で使用することで、負荷に応じた Pod のスケールアウトさせてみます。
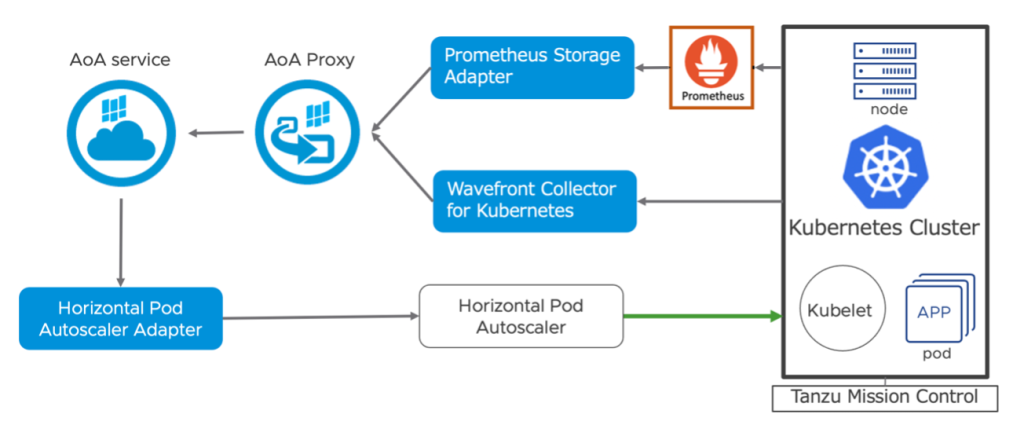
図20 Kubernetes 連携と Autoscaler
構成概要は上図の通りで、AoA Service と Tanzu Mission Control 以外は Tanzu Kubernetes Cluster 上で動作する Pod です。先程 TMC を使用してWavefront Collector for Kubernetes で AoA 連携させた Kubernetes 環境をそのまま使用します。また、Kubernetes ノードの GPU リソースのメトリックは以下のようにすでに Prometheus 用の NVIDIA DCGM Exporter により取得可能な状態にあるものとします。
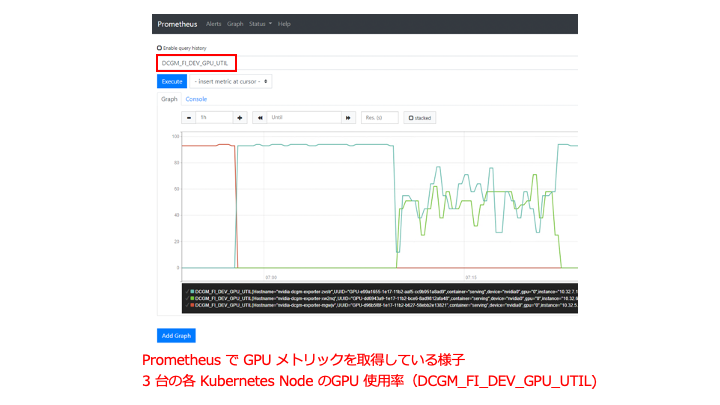
図21 Prometheus のダッシュボードでのメトリック表示
Wavefront Collector for Kubernetes で Kubernetes 環境の監視を行う場合、Kubernetes Cluster の Pod 、 Node などの標準的なメトリックを取得できますが、GPU リソースは取得できません。このため、GPU リソースは Exporter を介して Prometheus にて取得していますが、ここではPrometheus はコレクター・エージェントとしての役割とし、さらに Prometheus Storage Adapter を介して AoA にメトリックを転送する構成をとります。Prometheus には、リモートストレージというデータの永続化を目的とする外部データベースへのメトリックを転送する仕組みがあります。
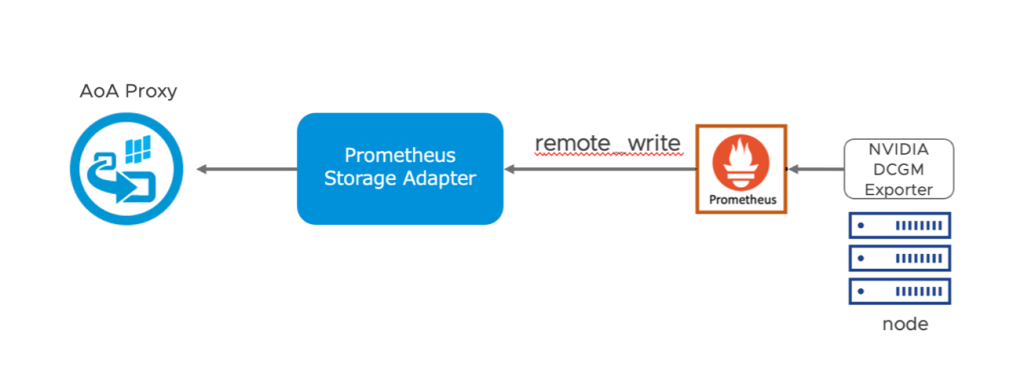
図22 Prometheus Storage Adapter を介してデータを Proxy に転送
Prometheus Storage Adapter をこのリモートストレージの “remote_write” の対象とすることで、リモートストレージのアダプタとして動作させ、AoA にデータを転送します。Prometheus Storage Adapter はこちらより yaml ファイル を取得し、AoA Proxy の設定を環境に合わせて変更します。
|
|
prometheus-storage-adapter として Pod が展開されます。ログを確認して、指定した AoA Proxy (wavefront-proxy-tanzu.tanzu-observability-saas.svc.cluster.local) の 2878 ポートに接続されていることを確認します。
次に、Prometheus 側にも設定を追加します。prometheus.yaml に以下の remote_write の出力先をPrometheus Storage Adapterとする設定を追加設定します。
|
※ここでは、Tanzu Extensions の Prometheus を使用しているため、prometheus-data-values.yaml での設定例です。
以上で GPU リソースのような特殊なメトリックを Prometheus を介して AoA に転送する設定が完了しました。AoA のダッシュボードで GPU メトリックが取得できているか確認します。
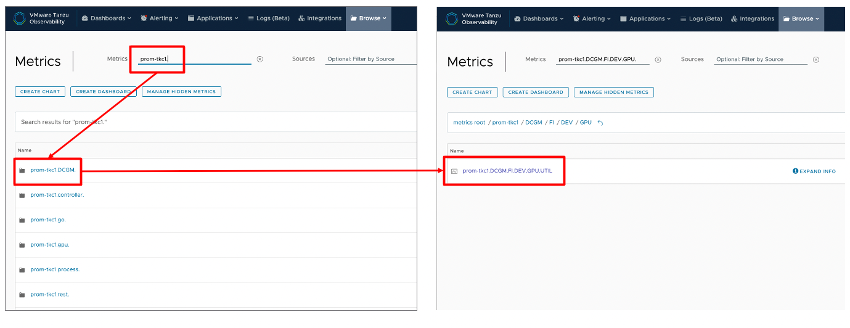
図22 Aria Operations for Applications 上での GPU メトリックの取得
AoA の「Browse」の「Metrics」で Prometheus Storage Adapter で設定した prefix=prom-tkc1 で検索をかけると、メトリックが検出されました。
これまで Prometheus でのみ取得できていたメトリックに、prefix (“prom-tkc1”) が付加されて、例えば “prom-tkc1.DCGM.FI.DEV.GPU.UTIL” としてAoA 側で取得できています。これはそのまま以下の WQL クエリによるダッシュボードが自動生成されてリンクされており、ワンクリックで表示できます。
|
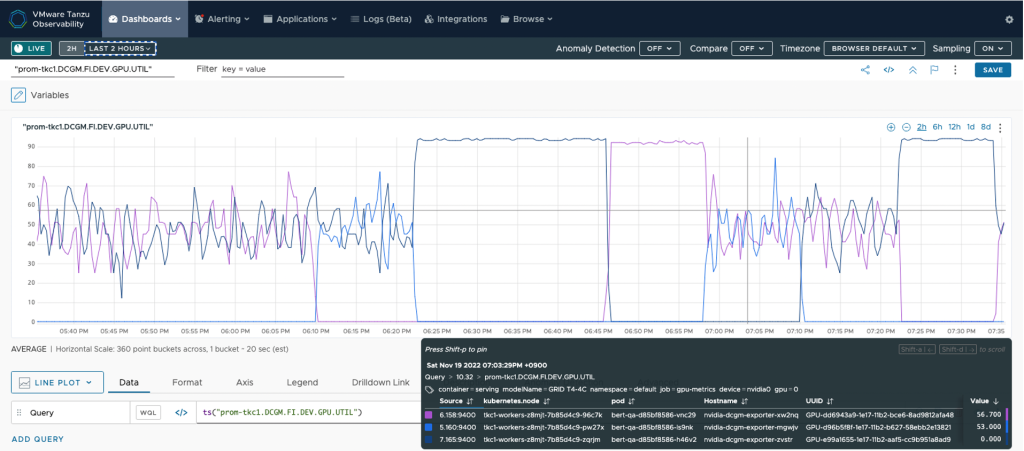
図23Aria Operations for Applications のダッシュボード上での GPU メトリック表示
無事、GPU 使用率が AoA ダッシュボード上でも確認できました。このように、Prometheus Storage Adapter と prometheusの remote_write の設定で、 Promethus をコレクター・エージェントとして動作させ、Prometheus Exporterで取得している外部メトリックを AoA に取り込み、監視することが可能となります。
Wavefront HPA Adapter for Kubernetes
せっかくですのでもう一歩踏み込んでみましょう。次に、この AoA で取得している GPU のメトリックに基づいて、Kubernetes が持つ Horizontal Pod Autoscaler (HPA) 機能を使用して推論サーバの Pod をスケールアウトさせてみます。デフォルトで HPA は Kubernetes Metrics Server 経由で CPU とメモリの情報を取得、使用することが可能ですが、Wavefront HPA Adapter for Kubernetes を追加することで、その他 AoA で利用可能なさまざまなメトリックに基づいてスケーリングさせることができます。AoA のメトリックを使用した Kubernetes の HPA によるスケールアウトについてはこちらのドキュメントに従って構成します。
まず、Wavefront HPA Adapter for Kubernetes を helm でインストールします。wavefront.url と wavefront.token は使用している環境に合わせて設定します。
|
Kubernetes HorizontalPodAutoscaler (HPA) コントローラは、Metrics API を介してメトリックを提供するために、Metrics Server がクラスタ内にデプロイされている必要がありますが、この Wavefront HPA Adapter for Kubernetes アダプタは、Metrics Server に代わり以下の API を実装しており、AoA で利用できるメトリックに基づいて Pod をスケールさせることを可能にします。
metrics.k8s.io
- Wavefront Kubernetes Collectorを使用して収集されたすべてのKubernetes メトリックを提供
metrics.k8s.io
- Kubernetes以外のメトリックや、Wavefront Collector以外の別のメカニズムを使用して収集したメトリックを提供
ここでは、external.metrics.k8s.io を使用するので、以下のように HPA 設定します。
|
GPU 使用率の値をそのまま使用しても良いですが、AoA にメトリックを取り込むことにより、WQL で定義可能なクエリによる派生メトリックを使用しています。これを gpu_util というアノテーション名で以下のように定義し、HPA のオートスケールのファクタとして定義、適用します。
|
この値をターゲット値として、設定した単位 (30) 毎に上回った際はターゲットの Pod (bert-qa) をスケールさせるという設定になります。なお、align というのは AoA のWQL 独自のクエリです。avg は過去 1 分間の ts() のメトリックの平均値を取るというものですが、その際に何かしらの理由でメトリックの欠損があった場合でも、前後のメトリック値の状況から欠損を補間し、極端なメトリック値とならないよう値を表示させるのが align です。AoA の WQL において合計値や平均値を取る際に使用が推奨されています。この HPA wf-gpu-hpa を展開後、external.metrics.k8s.io API から取得できるかを以下のコマンドラインで確認します。
|
以上で Wavefront HPA Adapter for Kubernetes ならびに HPA の設定が完了しましたので、推論サーバへの負荷をかけます。使用率が 30 単位を超える毎に Pod が追加され、maxReplicas で指定した 3 Pod まで自動的にスケールすることが確認できました。
|
- HorizontalPodAutoscalerメトリックは、接尾辞なしで整数を返す、またはミリ単位で数量を返す場合があります(1=1000m)
ここでは、機械学習の推論サーバという少し特殊な Kubernetes 環境での監視ならびにスケーリングを見ていただきましたが、このような外部メトリックをも取り込んで AoA の機能を生かしての統合監視を行い、また AoA を介することで独自のメトリック指標によって Horizontal Pod Autoscaler 機能にも対応できることがご理解いただけたかと思います。
なお、AoA の Integration オプションの一つとして NVIDIA GPU Integration も提供されており、AoA 独自にメトリックを取得することも可能にはなっていますが、比較的わかりやすい Prometheus 連携や HPA の応用例として挙げさせていただきました。
以上、Aria Operations for Application の機能のうち、メトリック監視の機能を中心にご紹介しました。今回紹介した内容はいわゆる「オブザーバビリティ」というよりも、従来のメトリック「モニタリング」の域を出ていない機能と感じるかもしれません。AoA ではさらにトレース、ならびにログ機能に対応により、従来の方法では監視しきれなかった Kubernetes ならびにマイクロサービスの「オブザーバビリティ」に対応してきています。これらトレースとログについては別の機会でご紹介したいと思います。


