

アプリケーションの可用性やセキュリティを高めるために、ロードバランサーを導入している企業が多いと思います。ロードバランサーを運用しているとき、「Web サイトの表示が遅い」、「アプリケーションでエラーが発生した」、「セキュリティ上の理由でSSL の設定を見直してほしい」などの問い合わせを受けることはないでしょうか。アプリケーションオーナーはユーザーエクスペリエンスの向上を求めますし、セキュリティチームは当然セキュリティの強化を求めてきます。システムやサービスに何か問題が発生した場合、ユーザーとアプリケーションの間に位置するロードバランサーに疑いの目が向けられることも多いでしょう。このような難しい状況で的確な判断を下すためには、ロードバランサーの高度な分析と可視化の機能が欠かせません。
ロードバランサーで可視化するメリットと課題
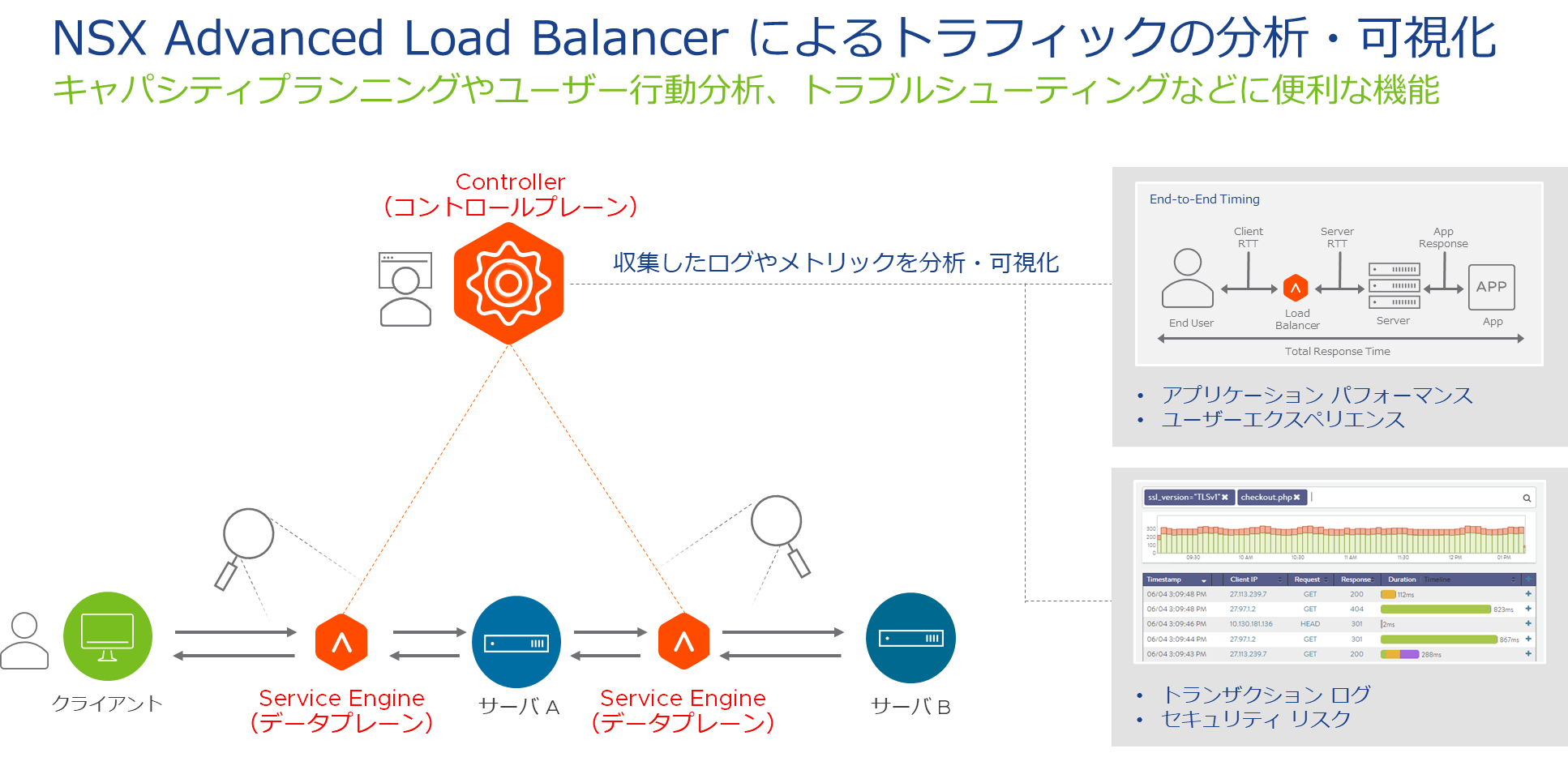
ロードバランサーはユーザーとアプリケーションの間に設置されるため、基本的にすべてのトラフィックはロードバランサーを経由します。ルータやファイアウォールと違い、ロードバランサーは、L4/L7レイヤでクライアントとサーバのコネクションを終端し、サービスの種類によってはSSL も復号化するため、アプリケーション層の高度なレベルで可視化することができます。たとえば、クライアントのOS やブラウザの種類、アクセス先のURL、エンドツーエンドの遅延、HTTP ヘッダなどの情報を取得することができ、アプリケーションオーナーにとっても有益な情報を提供することができます。また、万が一アプリケーションで不具合が発生した場合でも、障害の切り分けや原因の究明が容易に行えます。その他にも、キャパシティプランニングやSSL 設定のチューニングを効果的に行うための情報としても活用できるでしょう。
このようにロードバランサーで可視化するメリットは大きいにもかかわらず、従来のロードバランサーではネットワーク機器としてのパフォーマンス情報を可視化することしかできませんでした。具体的には、仮想サーバのコネクション数やリクエスト数、トラフィック量、スループットなどの統計情報の可視化です。もちろん、これらも有益な情報ですが、アプリケーション層で何が起きているのか、個々のリクエスト/レスポンスであるトランザクションレベルで詳細に把握することは難しかったと思います。その背景には、従来型ロードバランサーのアーキテクチャに起因する課題がありました。コントロールプレーンとデータプレーンが一体となっている従来型のロードバランサーでは、アプリケーション層の詳細な分析・可視化をすることによって処理負荷が生じ、ロードバランサー本来のサービスへのパフォーマンス影響が避けられませんでした。そのため、アプリケーションのトランザクションレベルで何か問題が起きた場合、パケットキャプチャを実施して調査することが多かったと思います。パケットキャプチャではリアルタイムのパケットしか取得できないため、残念ながら過去にさかのぼってトラブルシューティングをするのは困難です。また、ロードバランサー上でパケットキャプチャを実施することによって生じる処理負荷も無視できません。
NSX Advanced Load Balancer の革新的な分析・可視化
VMware が提供するNSX Advanced Load Balancer では、コントロールプレーンとデータプレーンを分離したアーキテクチャを取っているため、従来型ロードバランサーの可視化の課題を克服できます。データプレーンで取得したすべてのトランザクションのログやメトリックをコントロールプレーンに送信し、コントロールプレーンで集中的に分析・可視化を行います。このようにコントロールプレーンに分析・可視化の処理負荷をオフロードすることで、データプレーンで動作するロードバランサー本来のサービスへのパフォーマンス影響は限定的になります。また、管理者はコントロールプレーンの役割を担うコントローラにアクセスすることで、オンプレミス・クラウドを問わず、すべてのアプリケーションの状態を一元的に把握することができます。
可視化のユースケース
それでは、NSX Advanced Load Balancer が提供する分析・可視化の機能を活用したユースケースを紹介したいと思います。
ユースケース① Web サイトの表示が遅い原因の調査
Web サイトを通じてサービスを提供する企業が多い中、Web の表示が遅いという状況はユーザーの不満を招き、機会損失につながる可能性があります。Web が重い原因はさまざまですが、ある程度までは原因の切り分けができます。
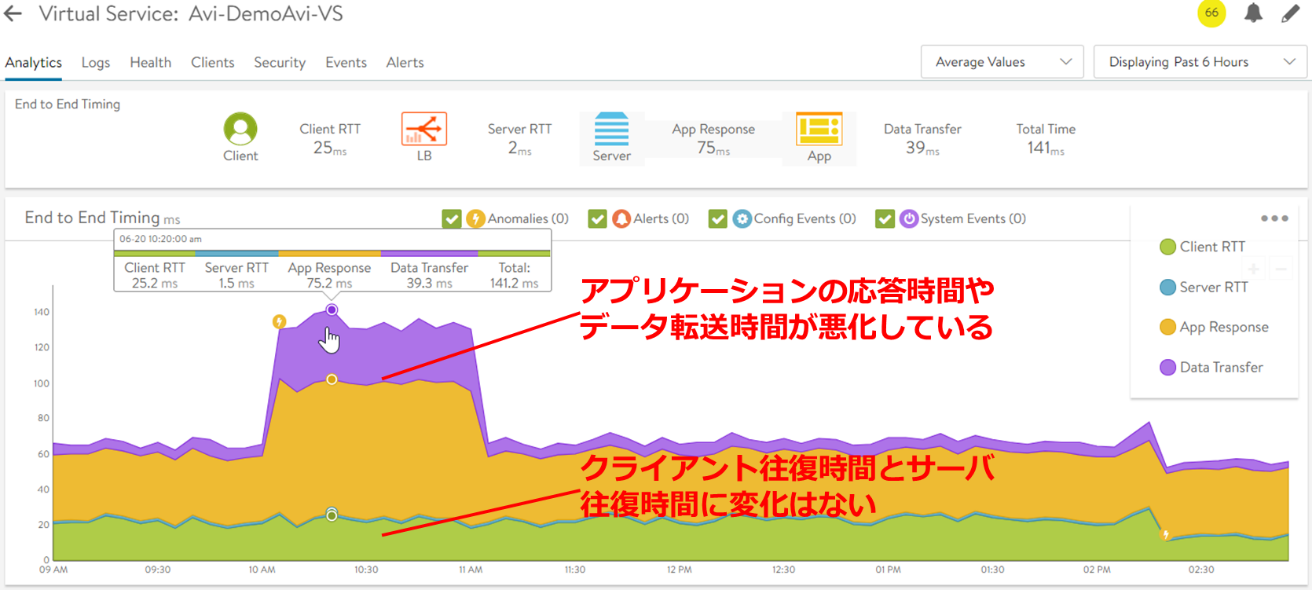
Virtual Service のAnalytics 画面では、End to End Timing と呼ばれるユーザーエクスペリエンスを見ることができます。具体的には、クライアントとロードバランサー間の往復時間(Client RTT)、ロードバランサーとサーバ間の往復時間(Server RTT)、アプリケーションの応答時間(App Response)、データ転送時間(Data Transfer)の合計がエンドツーエンドの遅延として、ユーザーエクスペリエンスを表します。
以下の例では、午前10時から11時の間でユーザーエクスペリエンスが急激に悪化していることがわかります。エンドツーエンド遅延の内訳を見ると、Client RTT とServer RTT に変化はなく、むしろApp Response とData Transfer が原因であることが一目瞭然です。つまり、クライアントとサーバ間のネットワークの問題ではなく、サーバ側アプリケーションに問題がある可能性が高いと推測できます。
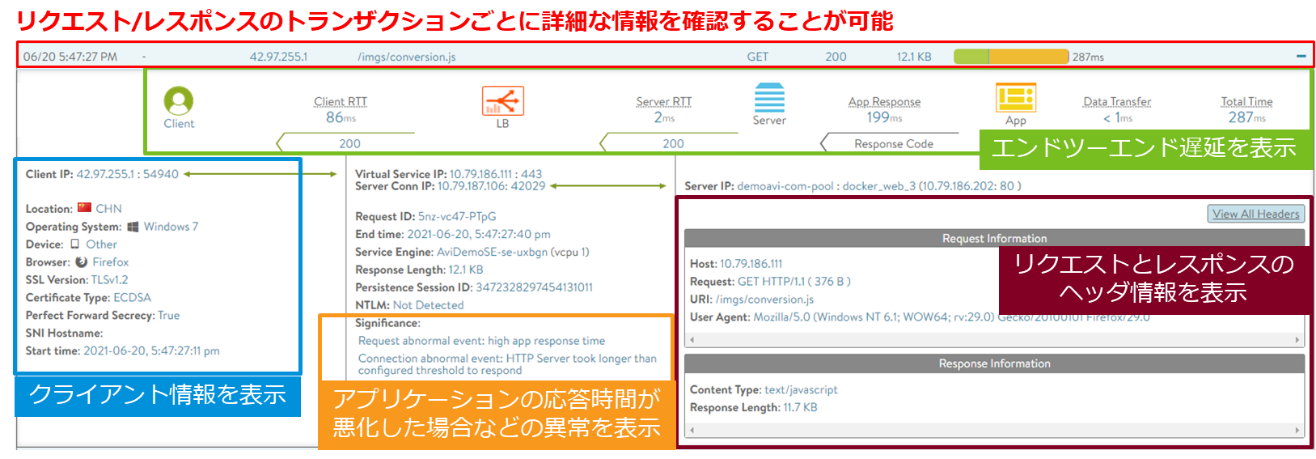
以下のLogs 画面では、リクエスト/レスポンスのトランザクションごとにユーザーエクスペリエンスなどの詳細な情報を確認できます。
Web サイトの表示が遅い原因の調査方法として、アプリケーションの応答時間が〇〇msec 以上のログを抽出してから、その原因となるバックエンドサーバを確認します。
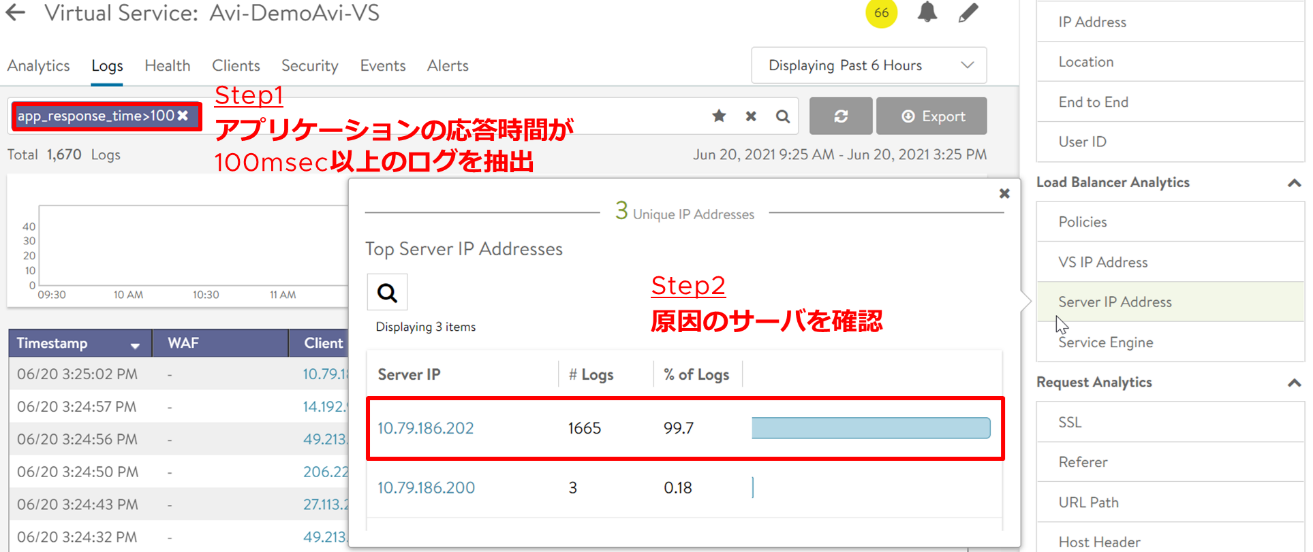
調査の結果、○○時間帯に△△サーバで実行中のアプリケーションを重点的に調査するようにアプリケーションまたはサーバチームに伝えることができます。
ユースケース② アプリケーションがエラーを返した原因の調査
サーバの過負荷が原因でリクエストを処理できなかったり、レスポンスのコンテンツが欠けていたりすると、サーバはHTTP レスポンスコード 4xxや5xxのエラーをクライアントに返す場合があります。たとえば、サーバがHTTP レスポンスコード404を返していた場合の原因について調査してみましょう。
最初にHTTP レスポンスコード404のログを抽出し、続いてその原因となるバックエンドサーバを確認し、最後にURL パス(コンテンツ)を確認します。
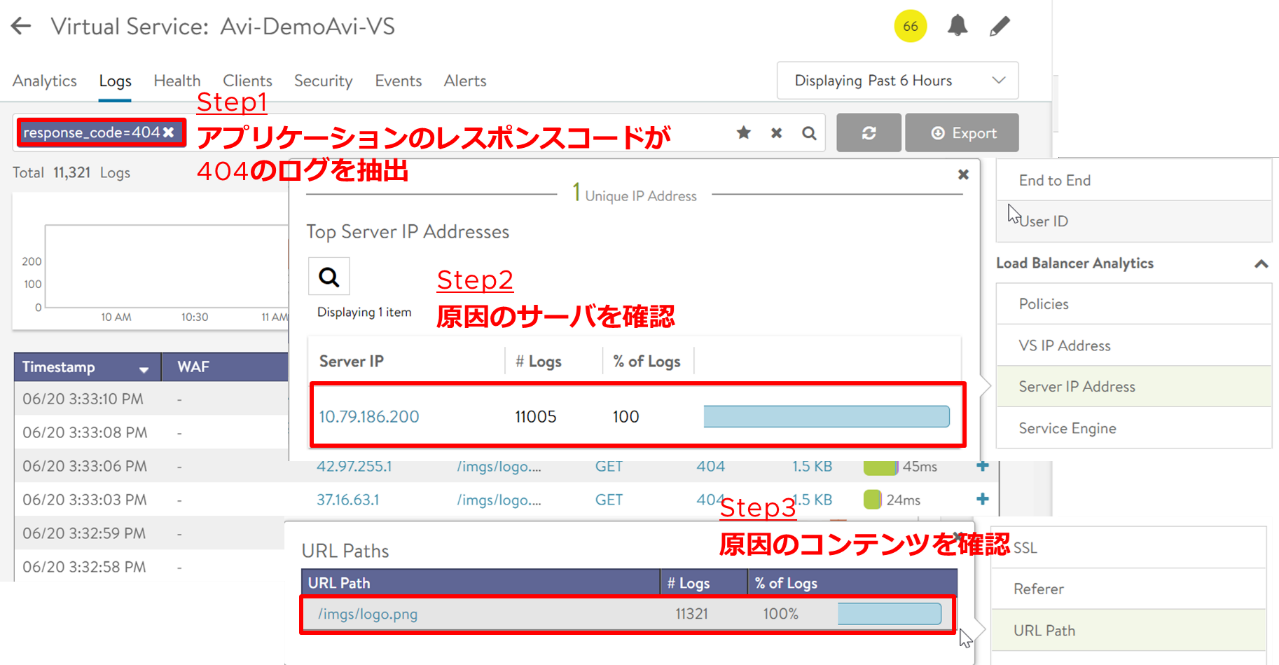
調査の結果、〇〇サーバの△△コンテンツが存在しない旨、アプリケーションオーナーに伝えることができます。
ユースケース③特定のクライアントとの通信が失敗した原因の調査
クライアントとロードバランサー間、またはロードバランサーとサーバ間で通信中に何らかの異常が原因でコネクションが切断されることがあります。トランザクションのSignificant Logs には異常なイベントが記録されるため、原因究明に役立てることができます。たとえば、TCP スリーウェイハンドシェイクやSSL ハンドシェイクの失敗、タイムアウトの発生、TCP リセットの送信などの詳細を確認することができます。
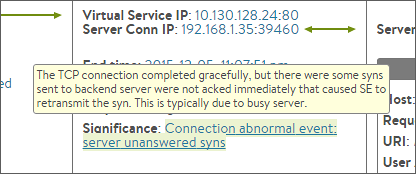
トランザクションの異常なイベントを可視化することで、日々の監視では見落としやすい軽微なエラーに対処することができ、より重大な障害を回避できます。
Significant Logs Events 一覧
ユースケース④SSL/TLS の設定をチューニングした場合のユーザー影響の調査
2021年現在、TLS プロトコルのバージョン1.0と1.1は、セキュリティ上の理由で無効化することが求められています。しかし、無効化した場合のユーザー影響も気にする必要があります。TLS 1.0と1.1でアクセスしているユーザー数の割合を把握することができれば、無効化することによるユーザー影響を事前に把握することができるため、より的確な判断を下すことができます。また、サーバ証明書や暗号アルゴリズムをRSA からECC に変更する場合も同様のアプローチが取れます。
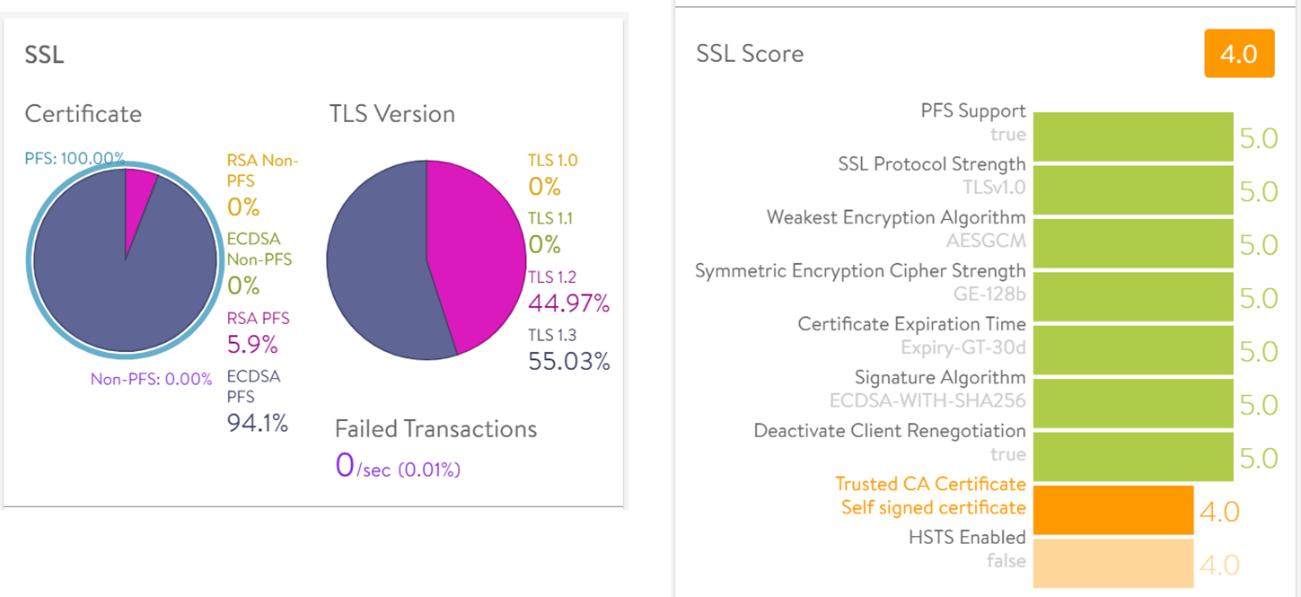
SSL Score は、脆弱な暗号アルゴリズムが使われていたり、証明書の有効期限が近づいていたりするなどのセキュリティリスクを数値化して管理者に教えてくれる機能です。
ユースケース⑤ クライアントのロケーションやアクセス環境の把握
クライアントのアクセス環境を把握したり、ユーザー行動分析したりするケースもあると思います。クライアントがアクセスに使用しているデバイスやOS、ブラウザの種類、アクセス元の国やアクセス先のURL などを把握することで、Web サイトのコンテンツをクライアントのアクセス環境に合わせて最適化することができます。
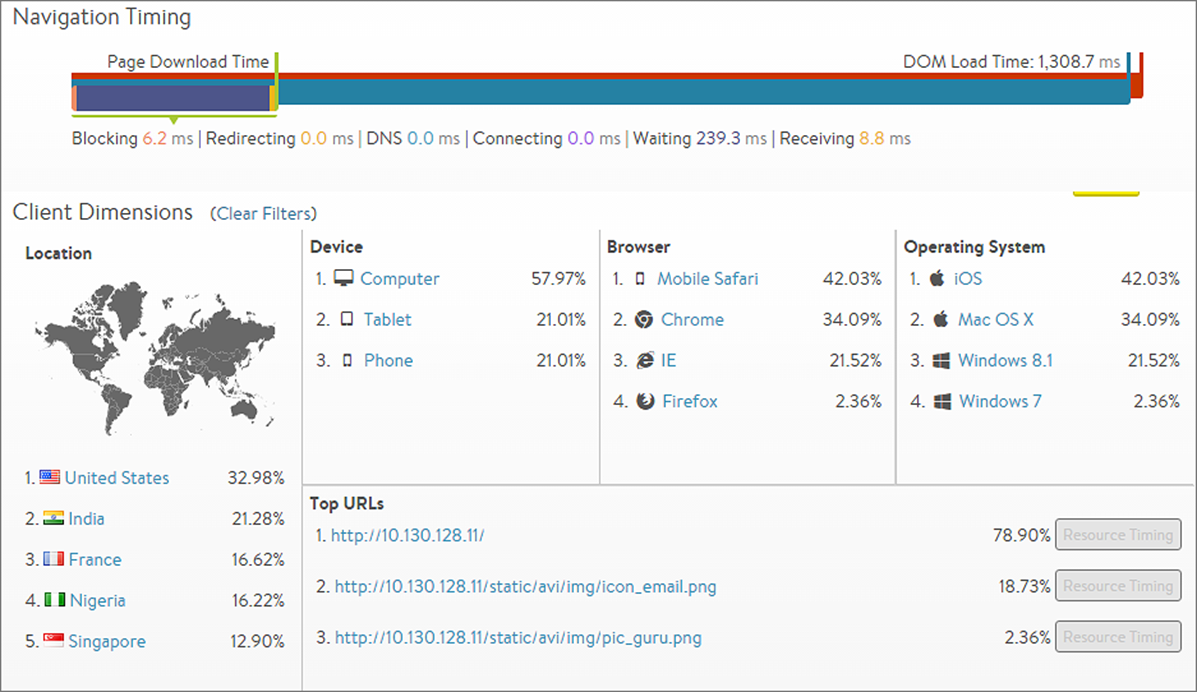
ユースケース⑥ アプリケーションの危険信号の把握
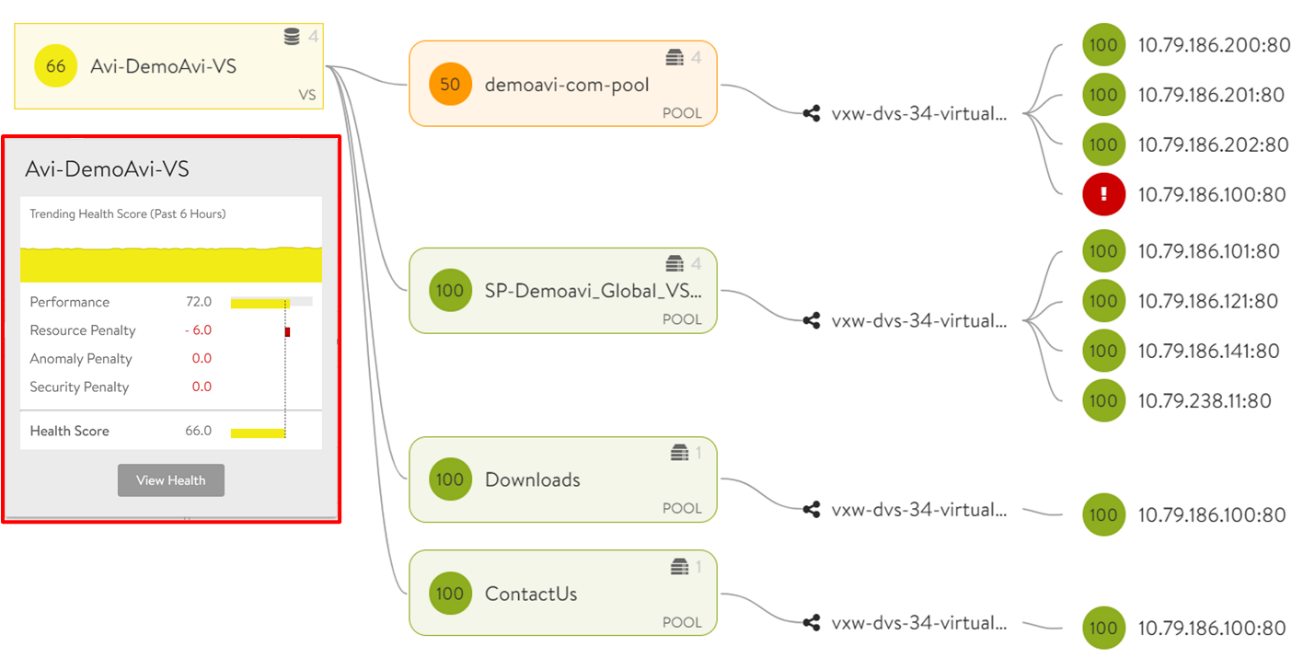
サービスが停止してから慌てて対処するのではなく、サービスが停止する兆候を察知して、予防措置を講じることが重要です。そのためには、サービスがUP またはDOWN のような単純な指標を監視するだけでは不十分です。NSX Advanced Load Balancer が提供するアプリケーション ヘルススコアでは、アプリケーションの健全度を数値化して、アプリケーションの微妙な状態を定量的に可視化することができます。たとえば、サービスはUP だが実は危険な状態を把握することが可能になり、予防措置的な対策が取れるようになります。
アプリケーション ヘルススコアは、パフォーマンスとリソース、アノマリー、セキュリティの指標をベースに算出しております。
ログの検索と分析機能
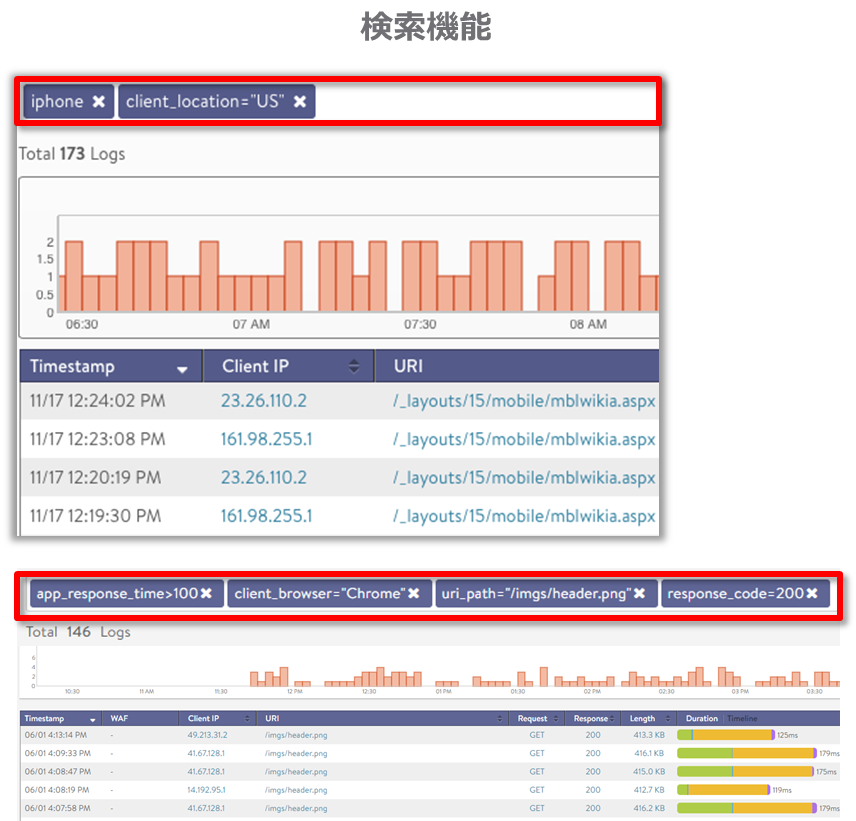
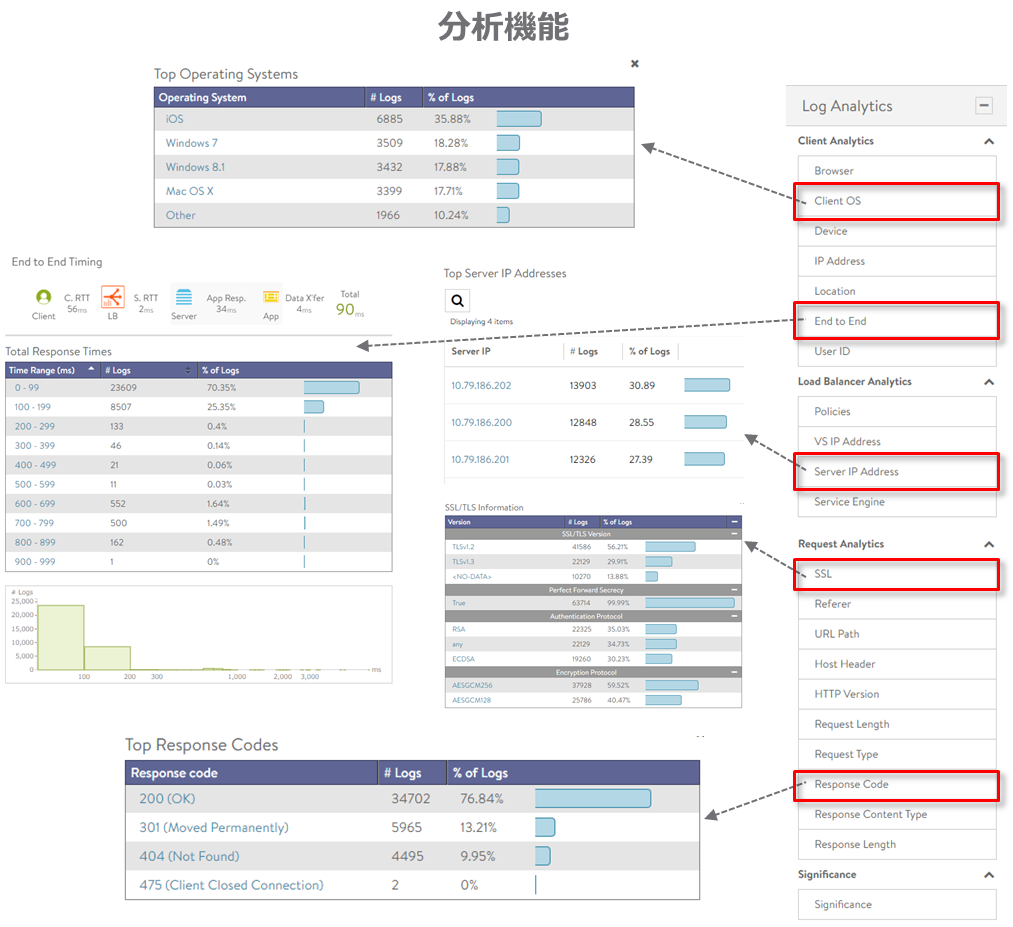
最後に、ログの検索と分析機能を簡単に紹介します。アプリケーションの膨大なトランザクションログがロードバランサーに記録される中、管理者がピンポイントに確認したいログを簡単に表示することができます。
検索機能では、「アプリケーションの応答時間が100msec以上」のような条件を指定して検索することもできれば、「iphone」、「abc123」のような任意のキーワードで検索することもできます。
分析機能では、「クライアントのOS」や「レスポンスコード」のような調べたい項目を選択することで、該当するログの数や割合を見ることができます。
まとめ
NSX Advanced Load Balancer による可視化はいかがでしたか。ロードバランサーの可視化の常識を覆すようなレベルではないでしょうか。アプリケーションがマイクロサービスアーキテクチャに移行し、コンテナやマルチクラウドで運用される時代には、アプリケーションのトラフィックはますますブラックボックス化されることが予想されます。そのようなときでも、アプリケーションの高度な分析・可視化機能を備えることで、万が一の障害や不具合が発生した場合でも、迅速かつ容易にトラブルシューティングが行えるようになります。今回はアプリケーションに焦点を当てた可視化の紹介になりましたが、NSX Advanced Load Balancer はセキュリティ(WAF, DDoS など)の可視化でも優れた能力を発揮します。また次の機会で、ロードバランサーによるセキュリティの可視化についてもご紹介したいと思います。
〜お知らせ〜
※VMwareでは、各種製品をクラウド上でご評価いただくHands-on Labs(HOL) という仕組みを無償でご提供しています。
今回ご紹介した各種ソリューションへの最初の一歩の入り口としてぜひご活用ください。
おすすめのHOLメニューはこちらから
- VMware NSX Advanced Load Balancer (Avi Networks) – Getting Started (HOL-2237-01-NET)
- VMware NSX Advanced Load Balancer (Avi Networks) – Global Server Load Balancing (HOL-2237-02-NET)
- VMware NSX Advanced Load Balancer (Avi Networks) Web Application Security (HOL-2237-03-NET)
- VMware NSX Advanced Load Balancer (Avi Networks) with Kubernetes (HOL-2237-04-NET)
- VMware NSX Advanced Load Balancer (Avi Networks) Lightning Lab (HOL-2237-91-ISM)



