

In this blog post, I’ll share my findings regarding scanner detection accuracy of open source inventory for containers and the open source license detection accuracy. Also, I’ll explore the scanner tooling landscape.
When looking at the container image scanners three years ago, I never could have imagined where all of this would lead. “A 20-minute adventure,” they said, “in and out. Let’s go!”
And here we are, three years later.
Scanners and container images
As the importance of software bills of materials (SBOMs) grows, there is a high demand for tools that build accurate software inventories. Containers, in this regard, require a special approach when dealing with open source inventory. Scanning software, as a tool, is not the most ideal way to gather SBOMs due to its non-deterministic or partially deterministic nature, but it is often the only option available.
Scanners identify the open source packages within a container image, recognize the open source licenses associated with the packages, and list known vulnerabilities for the discovered packages. I prioritized my focus here on package detection and license detection accuracy.
Scanner and container image selection for analysis
The analysis below includes a revised list of scanners and container images for comparison, along with a new approach to establish a comparison baseline.
The scanners selected are based on popularity, accessibility and existing usage, incorporating proprietary and open source tools for the analysis.
Also, I chose a couple general purpose file scanners for the analysis since they are used in combination with the container scanners.
Methodology for comparing scanner and container image results
In 2020, I needed to develop a methodology for comparing the scanners and decided to establish a baseline for each container image. I selected the following parameters for comparison:
- Inventory accuracy
- Detected license false positives
- Detected license false negatives
The baseline was collected as follows:
- An inventory was collected from a container image both for the BaseOS and the application layers (if present), using corresponding ecosystem commands (such as rpm, dpkg, go, npm, etc.).
- Each inventory entry was matched to a distributable package.
- Each package was retrieved and unpacked.
- All the files within each package were inspected for the license information, with the results stored in a spreadsheet for further comparison against scan results.
The analysis showed that most of the scanners do a decent job of listing open source software components or packages within a container image. However, the scanners have problems identifying the associated open source licenses. The analysis also revealed limitations in the approach taken to establish the baseline, a manual and very time-consuming process.
Tool-based baseline analysis
For the next iteration of study, I developed a tool-based baseline analysis. As I considered the available tools, I realized that a third-party tool may not be the most suitable option for a baseline source. I then considered developing a custom tool to parse the source code files in search of the license information: the FOSS License Parser / Ratum tool.
This approach made sense since the baseline didn’t need to be perfect, only sufficiently consistent for the comparison. The analysis involved these steps:
- Testing the selected scanners against the same batch of container images, following precise name tag correlation to keep the results consistent.
- Establishing the baseline required, beginning with building the inventory of the open source packages or open source components within any container image. Depending on the BaseOS type, the underlying package manager and the application package ecosystem involved, each approach differed.
- If there was just a BaseOS, I resorted to collecting output of the installed packages using the standard package manager.
- If there were application packages, such as NPM or go modules, I relied on each language ecosystem tool to list used modules or dependencies.
- As my final step, I combined the BaseOS and application inventory into one spreadsheet.
An overview of the analysis process
This process began by deploying each scanner to a Linux sandbox, unless a different environment was required for compatibility.
If the scanner processed a test image successfully, I determined the most convenient way to collect the results, such as having output in a JSON or some human-readable format.
Next, I used a bash script to run the scanner against the full list of the container image targets, collected the scan reports, and processed them to build both an inventory and a license listing for each scanner report per each image. Afterward, I updated each container image baseline with scanner results on the spreadsheet and compared the license listings against baseline license listings to collect false positives and negatives for each scan report.
Scanner accuracy calculation formulas used in the process:
- Inventory number accuracy against baseline, % = (“Scan inventory number” / “Baseline inventory number”) * 100%
- License false positives, % = (Number of licenses found in “Scan License Result,” but not found in License baseline / “Scan License Result”) * 100%
- License false negatives, % = (Number of licenses found in “License baseline,” but not found in “Scan License Result” / “License baseline”) * 100%
The interpretation of the results
The findings show a comparison between the scanners, but they don’t offer a conclusive answer to which scanners are best, given the multitude of parameters and scenarios to consider.
The scanner comparison also includes a feature comparison, as well as scanner accuracy calculation based on analysis formulas. The results are highlighted below.
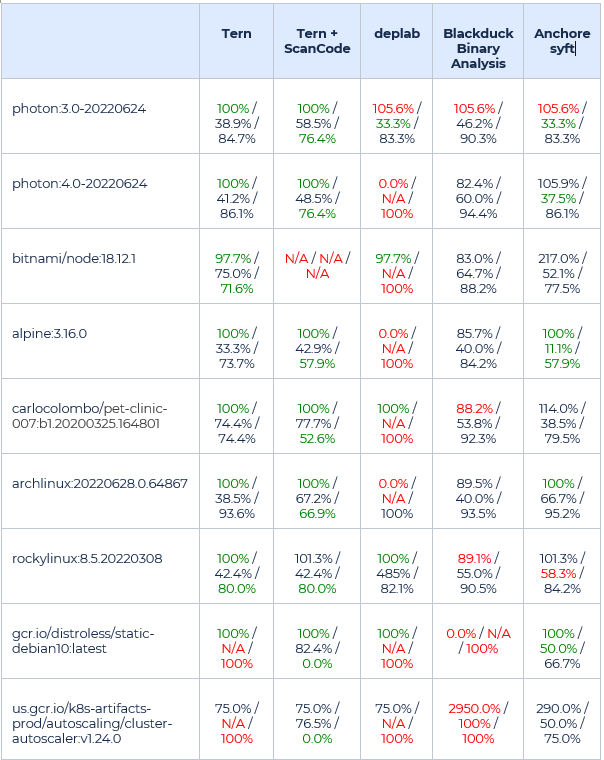
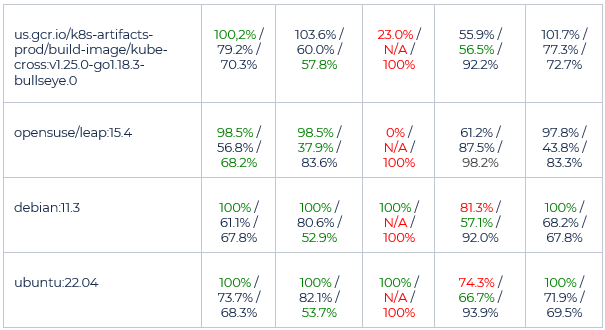
The most consistent scanners relied on deterministic data (the package manager listing) to build a scan report. These are Anchore syft and Tern container scanners.
I don’t recommend that you rely upon individual scanners. Rather, pair two or more complementary scanners. For instance, it’s common to use ScanCode with Tern (or other container scanners) to produce better license detection results on top of the detected inventory items.
A combined scanner usage requires some sort of a result merging mechanism. It’s possible that more work is necessary to find a combination of tools to develop a merging algorithm. Generally, the best combination is to use a deterministic scanner (using package manager data) combined with a general purpose scanner and/or a signature scanner.
The results from separate scanners would need to be merged, which means developing an algorithm and tools to deduplicate the results based on evaluated accuracy of each scanner.
Next steps
The analysis is far from over for there are more scanners out there and more potential use cases to cover.
Currently, I am working on enhancing the analysis based on RedHat Universal Base Image 8 and assessing the feasibility of adding K8S-sigs BOM tool and Microsoft SBOM tool.
Undoubtedly, there is more work to be done to keep up with the current trends in container scanning. Stick around!
Stay tuned to the Open Source Blog and follow us on Twitter for more deep dives into the world of open source contributing.




