

The 2022 Kubeflow User Survey was opened in May, and the results were published to the community, highlighting the top challenges of the machine learning lifecycle, gaps in Kubeflow and features needed to increase adoption.
At a high level, the latest user survey revealed:
- 44% of Kubeflow community members are running Kubeflow in production
- 85% are leveraging more than one component of Kubeflow
- Security and monitoring are the top machine learning lifecycle gaps for end users
- Documentation and tutorials are the biggest challenges in adopting Kubeflow
While it’s important to focus on the current state of Kubeflow, it’s also important to look at the journey. Let’s take a deeper look at how the Kubeflow project and community have evolved by comparing this year’s 1.6 user survey with last year’s 1.3 User Survey, results that were recently shared at the Kubeflow Summit 2022.
Increase in community expertise
In the 2021 survey, the Kubeflow community was made up mostly of ML engineers, architects, DevOps engineers, data scientists/analysts and software engineers. In the 2022 survey, the Kubeflow community showed similar results, where ML engineers made up the majority of the community, followed by architects and data scientists/analysts. While the roles remained similar, the comparison of the survey results revealed the growth of Kubeflow and machine learning expertise within the community.
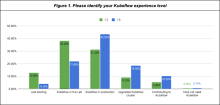
As seen in Figure 1, there was a 16.4% decrease in users running Kubeflow in the lab environment, a 12.3% increase in users running Kubeflow in production, a 9.4% increase in experience with upgrading Kubeflow cluster and a 4.8% increase in project contribution. The percentage may seem slightly low, but compared to last year, experience in upgrading and contributing to the project doubled in percentage year over year.
In addition, Figure 2 shows a comparison of how many models were successfully deployed into production. Again, we see a double in percentage for “100%” of the models, and Figure 3 shows a decrease in the iterations it took to produce a final model into production. Both figures show that many machine learning models take fewer iterations to build and are successfully deployed into production.

Continued challenges and gaps in machine learning lifecycle
Last year’s survey revealed that the top three gaps in machine learning activities and workflows were connecting data pipelines to machine learning pipelines (50%), manually building machine learning pipelines (43.8%) and monitoring models (42.7%). This year, the top answers stayed the same but in a different order, with monitoring models (59%) becoming the top answer, followed by connecting data pipelines to machine learning pipelines (45%) and manually building machine learning pipelines (42%).
Even though the gaps in the ML lifecycle remain the same, it’s important to note, as seen in Figures 4 and 5, the data shows the model building and pipeline building steps have become significantly less time consuming and challenging for users in comparison to the year before.
At the same time, the results also clearly show that data preprocessing and transformation continue to be the most time consuming and the most challenging steps for users.

Kubeflow, a coherent platform with gaps to fill
It’s not a secret that Kubeflow is a complicated tool. To facilitate easy adoption, Kubeflow allows users to leverage one component as standalone or many components as a coherent platform. As seen in Figure 6, when the community was asked how they leverage Kubeflow, 84.5% responded that they use it as a coherent platform with more than one Kubeflow service, an increase of 13.3% from the previous year.

When asked the reasons why some users prefer using a standalone service, some of the responses included the following:
- Kubeflow is too complex to set up and manage for a small team.
- There is only a need for one component.
- Leveraging more than one component increases complexity in integrating Kubeflow with other user-specific tools.
- A standalone service allows better control over security.
- There are no resources or time to explore and manage other components of Kubeflow.
Even though survey data does not show which combination of components is most used, the most popular component of Kubeflow continues to be Pipelines followed by Notebooks. While the top two stayed the same, Figure 7 shows a slight change in the ranking for this year, with KServe moving up in the ranks, overtaking hyperparameter tuning (Katib) and placing it as the third most used / will be used component.

Similar to the answers received on why some users prefer standalone service, there are clear gaps that discourage users from exploring Kubeflow and leveraging more than one component. Figure 8 shows the comparison of what the biggest gaps are in adopting Kubeflow. In the last year, there is a notable difference within security, which showed an increase of 11.7%. However, the most noticeable insight is that documentation still remains to be the biggest gap year over year and is clearly on top of the mind for many of the users.
Where do we go from here?
Over the past year, it’s clear that the Kubeflow project has evolved with the community’s help in addressing some of the key challenges of the machine learning lifecycle. However, there are critical concerns that remain to be addressed. For instance, regardless of your technical expertise and experience, you can get involved to help improve documentation and tutorials, a task that doesn’t require coding and has a positive impact on the community.
The Kubeflow community holds open meetings regularly. We welcome everyone to participate and help us grow the machine learning community together.
In closing, a huge thanks to everyone who participated in the survey!
Stay tuned to the Open Source Blog and follow us on Twitter for more deep dives into the world of open source contributing.




