
In part 1 we looked at GPUDirect RDMA Concepts and vSphere 6.7. In this part we will look at benchmark results for tests we ran comparing bare metal configuration with those of vSphere 6.7.
Benchmark Results
To achieve high performance, data must be moved between GPU memories efficiently with low latency and high bandwidth. To assess this, the OSU Micro-Benchmark was used to measure the MPI Send/Recv half round-trip latencies in microseconds and bandwidths in MB/s when moving data between two GPUs installed in separate ESXi host systems.
Configuration
Figure 3 illustrates the virtual testbed configuration. Point-to-point tests were performed using two hosts connected through a Mellanox InfiniBand/Ethernet switch. Each host was equipped with an NVIDIA P100 GPU card and a Mellanox Connect X-3 FDR (56 Gb/s) InfiniBand adapter, which also supports 40 Gb/s RoCE. The virtual tests were run with a single VM running Ubuntu OS on each ESXi host. The GPU card and InfiniBand/RoCE adapter were configured using DirectPath I/O (i.e., passthrough mode).
As described earlier, there are two possible data paths when transferring data from GPU memory on one host to GPU memory on another host. These paths in our testbed configuration are shown with the yellow and orange dashed lines in Figure 3. Table 1 shows the hardware and software details.
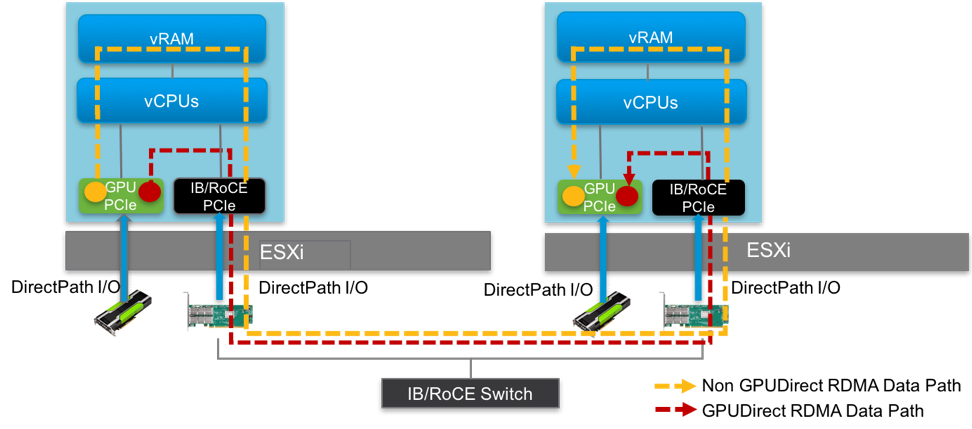
Figure 3: Testbed virtual cluster architecture showing the no-GPUDirect RDMA vs. GPUDirect RDMA data path with DirectPath I/O on vSphere 6.7
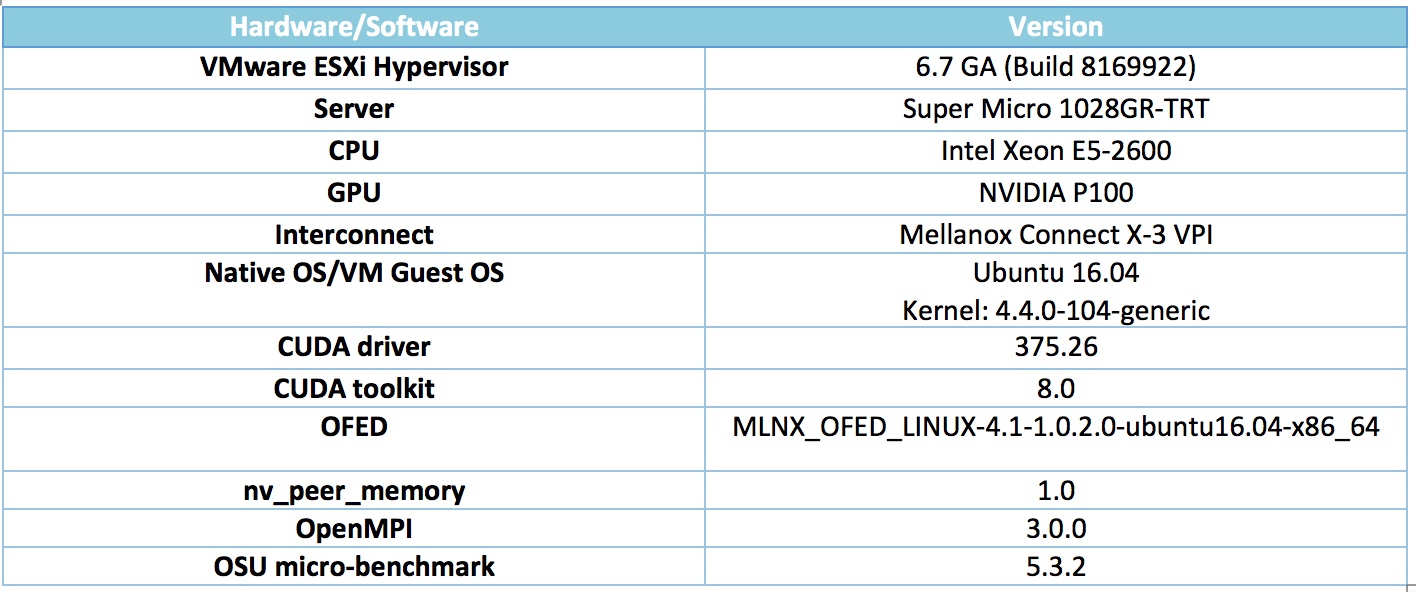 Table 1: Hardware and Software Details
Table 1: Hardware and Software Details
Performance – Latency
Figure 4 through Figure 7 show MPI half round-trip latencies, which were measured using osu_latency over message sizes from 1B to 4 KB. The figures focus on small messages since latency is most critical factor in this range of message sizes. Each reported data point represents the mean of 1000 iterations at that message size and half round-trip numbers are reported as the traditional HPC figure of merit.
Our previous work, “Performance of RDMA and HPC Applications in Virtual Machines using FDR InfiniBand on VMware vSphere”, has demonstrated close-to-native MPI latencies transferring data between guest OS memory buffers on two hosts using InfiniBand with Direct Path I/O. We have also observed close-to-native MPI latencies with RoCE.
Figure 4 and Figure 5 shows MPI half round-trip latency comparisons between bare-metal No-GPUDirect RDMA and bare-metal GPUDirect RDMA for data transfers between GPU memories. We can see that GPUDirect RDMA is able to achieve a 3X improvement, reducing the latency from ~15 μs to ~5 μs, for both InfiniBand and RoCE.
Figure 6 and Figure 7 shows MPI half round-trip latency comparisons between virtual No-GPUDirect RDMA and virtual GPUDirect RDMA for data transfers between GPU memories. Similar to the bare-metal case, the No-GPUDirect RDMA latency is ~15 μs while GPUDirect RDMA latency is ~5 μs, demonstrating that the overhead due to virtualization is negligible.
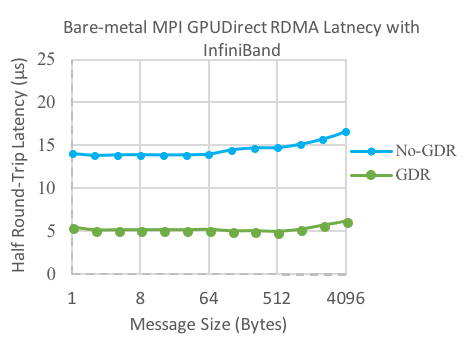
Figure 4: Bare-metal Latency vs. Message size for No-GPUDirect RDMA (No-GDR) vs. GPUDirect RDMA (GDR) on InfiniBand

Figure 5: Bare-metal Latency vs. Message size for No-GPUDirect RDMA vs. GPUDirect RDMA on RoCE
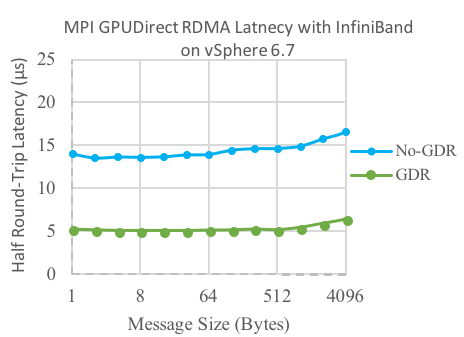
Figure 6: Virtual Latency vs. Message size for No-GPUDirect RDMA vs. GPUDirect RDMA on InfiniBand
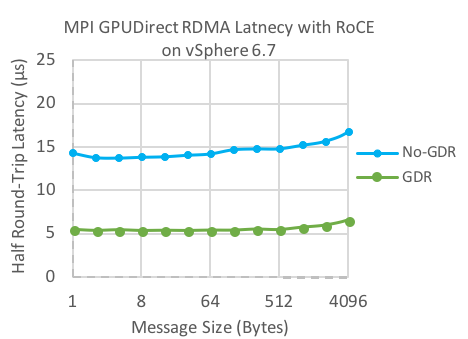
Figure 7: Virtual Latency vs. Message size for No-GPUDirect RDMA vs. GPUDirect RDMA on RoC
Performance – Bandwidth
Figure 8 through Figure 11 show MPI bandwidth, which was tested using osu_bw over message sizes from 1B to 4MB. Figure 8 and Figure 9 show MPI bandwidth comparisons between bare-metal No-GPUDirect RDMA and bare-metal GPUDirect RDMA for data transfers between GPU memories. GPUDirect RDMA significantly improves the bandwidth — by roughly 3X. We did note that when not using GPUDirect RDMA, the tests hung for message sizes larger than 8 KB in both the bare-metal and virtual cases. We did not root-cause this issue as it was not virtualization-specific.
Figure 10 and Figure 11 show MPI bandwidth comparisons between virtual No-GPUDirect RDMA and virtual GPUDirect RDMA for data transfers between GPU memories. Similar to bare-metal performance, the No-GPUDirect RDMA bandwidth is much lower than that of GPUDirect RDMA. Once again, the overhead due to virtualization is negligible.

Figure 8: Bare-metal Bandwidth vs. Message size for No-GPUDirect RDMA vs. GPUDirect RDMA on InfiniBand
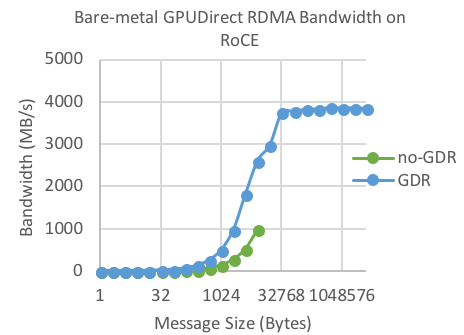
Figure 9: Bare-metal Bandwidth vs. Message size for No-GPUDirect RDMA vs. GPUDirect RDMA on RoCE
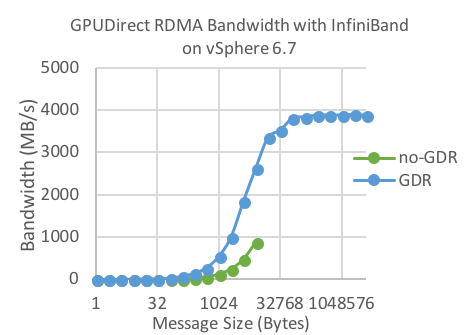
Figure 10: Virtual Bandwidth vs. Message size for No-GPUDirect RDMA vs. GPUDirect RDMA on InfiniBand
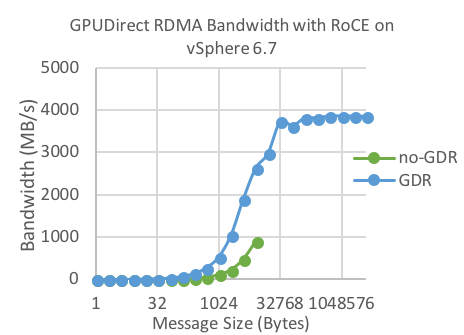
Figure 11: Virtual Bandwidth vs. Message size for No-GPUDirect RDMA vs. GPUDirect RDMA on RoCE
Conclusion and Future Work
GPUDirect RDMA is a useful technology for accelerating performance of HPC and ML/DL applications when those applications are scaled to span multiple hosts using multiple GPUs. It can significantly reduce latencies and deliver close to bare-metal InfiniBand or RoCE bandwidths while also offloading significant work from host CPUs, freeing them to perform additional application processing.
We have shown that this feature can be enabled on vSphere 6.7 and that near bare-metal performance can be achieved. We continue to explore other GPUDirect technologies and to expand the applicability of VMware private and hybrid environments for an increasingly wide range of HPC and Machine Learning workloads.
Authors: Na Zhang, Michael Cui & Josh Simons. (VMWare office of the CTO)
Discover more from VMware Cloud Foundation (VCF) Blog
Subscribe to get the latest posts sent to your email.





