
Introduction
High Performance Computing (HPC) and Machine Learning (ML) workloads are extremely resource intensive, often relying on hardware acceleration to achieve the performance necessary to solve large, complex problems in a timely way. Interconnect acceleration – special hardware that delivers extremely high bandwidth and low latency, and compute acceleration – often delivered through exploitation of very highly-parallel GPU compute engines, are the most common forms of such acceleration. While both types of acceleration have long been available on vSphere, it is now possible with vSphere 6.7 to combine these technologies to support advanced HPC and ML applications that exploit the cross-host coupling of multiple GPUs to solve problems that scale beyond the capacity of individual hosts. This technique, called GPUDirect RDMA, allows applications to combine the compute power of NVIDIA GPUs with the high-performance data transfer capabilities of Mellanox RDMA devices.
This article presents a performance evaluation of GPUDirect RDMA on vSphere 6.7.
GPUDirect RDMA
GPUDirect is a family of NVIDIA technologies that enables direct data exchange between multiple GPUs, third party network adapters, solid-state drives and other devices using standard features of PCIe. Among these features, the two most related to HPC and ML are peer-to-peer (P2P) transfers between GPUs and remote direct memory access (RDMA). GPUDirect P2P enables data to be directly exchanged between the memories of two GPUs on a host without the need to copy data to host memory, offloading the burden from the host CPU. GPUDirect RDMA is a multi-host version that enables a Host Channel Adapter (HCA) to directly write and read GPU memory data buffers and then transfer that data through a remote HCA to a GPU on a second host, again without the need to copy data to host memory or involve the host CPU. Both approaches have demonstrated significant performance improvement for GPGPU accelerated HPC and Machine Learning/Deep Learning (ML/DL) applications. Figure 1 and Figure 2 illustrate the concepts of GPUDirect P2P and GPUDirect RDMA. This article focuses specifically on GPUDirect RDMA.
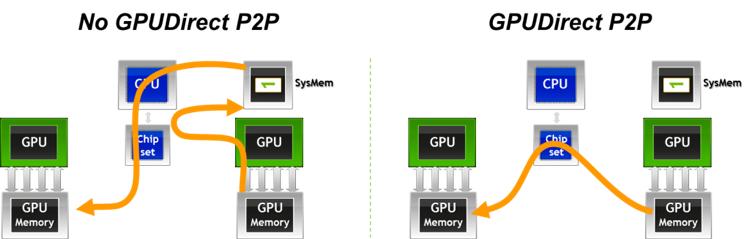
Figure 1: P2P GPUDirect Configurations
Figure 1 Without GPUDirect P2P, the host CPU must transfer data from one GPU’s memory, to host memory, and then into the second GPU’s memory. With GPUDirect P2P, the data can be transferred directly without host CPU involvement and without data being transferred to host memory.
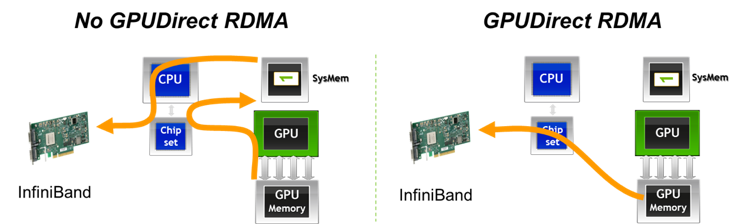
Figure 2: RDMA GPUDirect Configurations
Figure 2 Without GPUDirect RDMA, data must be copied by the host CPU from GPU memory to host memory and then from host memory it is sent via RDMA (InfiniBand) to the remote host. With GPUDirect RDMA, the data is transferred directly from GPU memory to the remote host with no host CPU involvement. Source: NVIDIA CUDA Aware MPI
GPUDirect RDMA on vSphere 6.7
To use GPUDirect RDMA between VMs on two ESXi hosts, the following prerequisites must be met.
GPUs – NVIDIA supports the use of GPUDirect RDMA with Tesla/Quadro K-Series or Tesla/Quadro P-Series GPU cards.
RDMA devices — Mellanox supports RDMA with both its InfiniBand and RDMA over Ethernet (RoCE) devices, including Connect-IB, Connect X-3, Connect X-4 and Connect X-5. RDMA is a popular option for HPC system interconnects because it allows a network adapter to transfer data directly to or from application memory without involving the operating system, thus enabling high bandwidth and low latency, which are critical characteristics of interconnects for distributed systems.
DirectPath I/O — VMware DirectPath I/O technology allows the guest OS to directly access a PCIe device by bypassing the virtualization layer. DirectPath I/O generally works with all PCIe devices as long as the platform satisfies the DirectPath I/O requirements (KB article: 2142307). Note that for PCI devices with large BARs (Base Area Registers) — PCI configuration spaces larger than 16 GB — special VM settings are needed. Examples of such devices include the NVIDIA K80 and P100 and Intel Xeon Phi. Please refer to article “How to Enable Compute Accelerators on vSphere 6.5 for Machine Learning and Other HPC Workloads” for details. If you have any trouble in configuring DirectPath I/O with large-BAR PCI devices, please contact us.
vSphere 6.7 — GPUDirect RDMA depends on peer-to-peer memory transfers between PCIe devices in DirectPath I/O mode, which is enabled on vSphere 6.7. To enable this for a VM, add the following line to its VMX file:
pciPassthru.allowP2P = “TRUE”
Software/Plugins — Several software components are required to enable GPU Direct RDMA
- NVIDIA driver/CUDA toolkit: CUDA 5.0 or later is required. Consult NVIDIA support for the device driver version appropriate for a specific card.
- MPI library: A version of MPI that is CUDA-aware is required. Several MPI implementations have GPUDirect RDMA support. For example, Open MPI has basic GPU direct support since 1.7.0 and MVAPICH has a binary release MVAPICH2-GDR to support GPUDirect RDMA. MPI is a messaging library commonly used in HPC to enable communication of data via distributed processes.
- Mellanox software: A Mellanox version of standard OFED (The OpenFabrics Enterprise Distribution) is required. MLNX_OFED v3.1 or later is required for Connect-IB/ConnectX-3/ConnectX-3 Pro/ConnectX-4 and ConnectX-5; MLNX_OFED v2.1 or later is required for Connect-IB/ConnectX-3/ConnectX-3 Pro. In addition, the Mellanox nv_peer_memory module needs to be installed and loaded on each system.
In Part 2, we will look at benchmark results for tests we ran comparing bare metal configuration with those of vSphere 6.7.
Authors: Na Zhang, Michael Cui & Josh Simons, (VMWare office of the CTO)
Discover more from VMware Cloud Foundation (VCF) Blog
Subscribe to get the latest posts sent to your email.




