A few weeks ago, I laid out a view of configuration management (“CM”) in a world where modern applications dominate. I also mentioned taking a (more or less) code-first view of the Kwite projects mentioned with respect to CM.
In this article, I’ll go through how the Kwite and Kwite-operator projects make features more readily accessible by taking advantage of Kubernetes. The hope is to get some hands on experience working with the Kubernetes operator pattern. To be sure, this is not about the features of Kwite services. What that means is producing a cool Kwite demo with appealing content Kwites can serve is not in the offing, at least in this article – that’s for later. What is of interest is some of the code connections to CM when writing applications for, versus just to run on, Kubernetes.
Setting Up
To work on anything ‘Kubernetes’, you need a reasonable container setup, for example Docker. As well, a Kubernetes cluster into which to deploy things. Finally a number of relatively standard dev tools installed on your machine. I use VMware Fusion and all my Kwite work is in a single virtual machine running Arch Linux with these packages and characteristics:
- 100GB Disk
- 6 GB RAM
- 4 Virtual CPUs
- Hostname: concourse.corp.local resolvable via DNS.
- Installed packages (and on the path):
- A container runtime, e.g., Docker
- A Kubernetes cluster, e.g., kind
- Note: to enable the Horizontal Pod Autoscaler Kwite-operater sets up, you also need deploy:
- cert-manager
- metrics-server
- Git
- Go Language version 1.13+
- Kubectl
- Kustomize
- Fly
- Concourse CI
Other Linux distributions will work fine, I just happen to prefer Arch.
The order of things to do to get setup is pretty simple, though some effort is involved any time development around Kubernetes is involved. To be sure, this article is not a tutorial on running Concourse CI, Kubernetes or the like as there are many possibilities and tutorials for those. The assumption is you have a setup running similarly as follows.
- Get Concourse Running
- Assure you have a container registry and related credentials to push and pull containers
- Get a Kubernetes (e.g., kind) cluster up and running
- Get and work with the code.
Getting the Code
Fork the code on Github. The two repositories to fork are at Kwite and Kwite-operator. Once forked, git clone your forks onto the machine you are using for working with Kwite. Note that you will use the name of your account in place of mine (i.e., tdhite) wherever my userid is used when referring to the code repos, Concourse pipeline parameters and the like.
Adding Concourse Pipelines
In each of the Kwite and Kwite-operator projects are pipeline definitions for building and deploying everything. For instructions on getting those pipelines ready, you can look here and here.
Once added, you can either log in to the Concourse UI and unpause the pipelines or otherwise use the fly unpause-pipeline command to do the same.
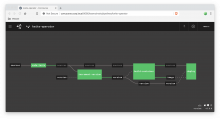
After a successful build, you should see something like the following for both the Kwite and Kwite-operator pipelines:
Now that things are deployed into your Kubernetes cluster, you can issue a couple sample kwites to the Kubernetes cluster. To do so, edit those files to match the needs of your Kubernetes cluster. For example alter the image variable to match your container registry URL and fix up the httpGet call to match your local DNS setup. Finally, from the top of your cloned kwite-operator code repo issue a kubectl command similar to the following:
|
1 |
kubectl -n myk8snamespace apply -f config/samples |
Check the deployments as follows:
|
1 |
kubectl -n myk8snamespace get all |
Take a look the ConfigMaps Kwite-operator setup similarly to the following:
|
1 2 |
kubectl -n myk8snamespace get cm/kwite-1 -o yaml kubectl -n myk8snamespace get cm/kwite-2 -o yaml |
taking particular note of the rewrite values in those ConfigMaps. Those will look like the following:

Delving Briefly Into Kwites
For a description of Kwites, look to the Kwite README. See also an example that Kwite-operator enables in terms of defining Kwites to deploy into Kubernetes clusters.
The Kwite code that enables its features is not really the interest of this article, but one part of that is important. Kwite instances rewrite URLs passed as parameters to functions Kwites expose to template writers. In particular, the http functions they provide. To do so, Kwites need a map that helps translate “kwite://” schemed URLs into standard URLs. For example: kwite://kwite-1.mynamespace/myurl might be translated to something like http://kwite-1.mynamespace.svc.cluster.local:8081.
A log of a Kwite instance detecting and reacting to changes to such a map (actually contained in a ConfigMap) is below.
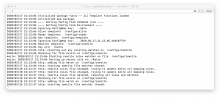
Any time a new Kwite is deployed into a cluster, Kwite-operator updates all Kwite instances in the cluster with a URL mapping so template writers need not know the details of the Kwite deployment characteristics. Kwite-operator does so by modifying the ConfigMaps used to pass configuration info to Kwites. All a template writer needs to know is the name and namespace of the kwite, as in something like the following template snippet:
|
1 |
{{ httpGet kwite://kwite-1.mynamespace/theurl "" }} |
Kwites automatically map such URLs to a proper URL that matches the cluster Service DNS Address, as discussed above.
Looking at Kwite-operator
To setup the mapping, Kwite-operator updates all Kwite ConfigMaps with the mappings that match the Kwite Service address. Note that this is consistent with the first article of this series – Kwite-operator is managing the configuration of the Kwite instances in real-time, all the time. The Kwite-operator code that manages the URL mapping is located here.
Note: To be sure, there are many ways to share configuration data across Kwite instances. For example, the URL rewrite data Kwite-operator writes into the Kwite ConfigMaps could just as well be shared via something like viper. However, the point of the Kwite implementation is to use core Kubernetes facilities as much as reasonably possible and keep Kwite-operator in control of CM.
When Kwite-operator updates the URL mapping rules in ConfigMaps, as in this code, the related volume mount in Kwite instances gets updated inherently by Kubernetes. Therefore a Kwite instance gets the update immediately when made available by Kubernetes. However, there is no signal sent to the Kubernetes Pod that notifies the Kwite instance of those changes. There is some discussion of enabling that, but right now another method is needed.
Looking at Kwite Again
To cover for Kubernetes’ non-signaling of ConfigMap changes, Kwite instances watch for changes to the ConfigMap by monitoring changes to files Kubernetes modifies on the volume mount. The file of interest contains the necessary kwite-to-standard URL mapping. The code that actually handles that is within the Kwite project as opposed to the Kwite-operator.
Understanding the Go language code itself is not the interesting point if you don’t program in Go. The interesting point is recognizing the very tight relationship between Kwite-operator (manages ConfigMaps, among many other things) and Kwite instances (watches files altered by the ConfigMap changes) from a CM standpoint. This is a dance between Kwite-operator and Kwite code, both inextricably linked as discussed in the first article in this series.
Conclusion
This article provides some additional insight into what is involved in writing applications for Kubernetes versus getting apps to just run on Kubernetes. The difference is the extent to which applications take advantage of core Kubernetes constructs. The original blog introduced CM in applications written for Kubernetes. This article took it a step further in discussing dynamically updated CM and the necessity of highly co-dependent and co-operative apps and Kubernetes operator implementations.