

By Tom Hite, Sr. Director, PS Research Labs
Are today’s configuration management (“CM”) solutions headed the way of mainframes or into a flourishing future? Lately this question dogged my mind so I decided to explore what CM looks like down the road assuming modern applications dominate. This blog series (more to follow) discusses this and provides some code level insight to that question.
 To be sure, this is not a simple topic. Then again, as noted in the tweet to the right, neither is Kubernetes.
To be sure, this is not a simple topic. Then again, as noted in the tweet to the right, neither is Kubernetes.
Stick with it, though, because we will discuss (as simply as reasonable at this time) a glimpse into the future Kubernetes brings to CM and how that may affect development and IT operations teams.
Kwite the Journey
For discussion purposes, I’ll refer to a couple projects I threw together – Kwite and Kwite-operator.
The term “Kwite” stands for “Kubernetes Web Integrated Template Engine” and the Kwite docs explain how the term arose. A Kwite is pretty much a serverless, programmable HTTP responder (e.g., web page or REST handler). It’s a fun name and project, but I really just intended to explore what happens to CM if one addresses application modernization by writing code for, as opposed to getting it running on, Kubernetes.
Kwite will ultimately be more powerful than it is right now because I plan to add to it. That and how to build and interact with Kwites will be the subject of a follow-up article so the concepts discussed herein hopefully get more concrete for everyone. More importantly, though, for this discussion, is the initial work to validate my perspective.
The lean-in hereafter regards how modern application efforts, including application modernization, probably sees application development teams taking over application CM, which is often the domain of IT operations.
Kubernetes enables such initatives and yet developers will not need to code in traditional CM DSLs.
Unpopular Opinion
After code journeying with Kwite, a potentially (very) unpopular opinion came to light. Admittedly I was already a bit predisposed to the thought, but Kwite cemented it: the world of traditional CM – Ansible, Chef, Puppet and the like – may well be headed the way of the mainframe: left for dead, but the beasts somehow continue breathing. Further, it follows with the rise of Kubernetes the IT industry will continue its encroachment by app developers into areas often covered by IT operations teams, namely application CM.
By “continue breathing,” I mean to suggest current CM tools will inevitably end up used mostly for use cases aligned with infrastructure automation capabilities one finds fundamental and inherent in VMware vRealize Automation or possibly Terraform. Think this way: use just enough infrastructure as code (i.e., CM) to get servers ready for Cluster API to take over. From there it’s all Kubernetes for app-level CM and arguably GitOps to keep desired application configuration states in line based on custom resource declarations like Kwite manifests. If true, that isn’t going to happen instantaneously – things take time; mainframes are still breathing long after claims they’d be dead and gone. Regardless, the writing may be appearing on the wall and things move faster in today’s IT and Kubernetes-enabled world.
Is Kwite enough to form that opinion? Demonstrably so. To be sure, though, no one claims at this time Kwite features represent anything yet for serious web work. It is a simple application that gives reasonable indications of the future of CM.
Will Modern Apps Start the Demise of Traditional CM?
Kwite came from a rephrase of the original question above: what if servers like the venerable Apache HTTP Server Project didn’t exist and we needed to programmatically serve URLs. The thought was simply that we would probably take a serverless approach and create a “quite small web server” for Kubernetes, expecting Kubernetes do as much of the heavy lifting as possible.
The Kwite code repos speak for themselves if you want to learn more about Kwite and the features it provides. Briefly, Kwite is the exposed application (i.e., programmable web server) and Kwite-operator is the CM solution that manages Kwites. The latter is nothing more than a Kubernetes operator pattern implementation for creating, configuring, maintaining, and cleaning up everything associated with running Kwites in Kubernetes clusters.
One might immediately ask: is an operator really just CM? Well, generally speaking, close enough. Operator implementations are just mechanisms to declare and reconcile desired states of cluster resources. That’s not dramatically different (if at all) from what the Ansible documentation states: “No matter what state a system is in, Ansible understands how to transform it to the desired state.” Other CM solutions are similar.
Kwite-operator’s job is to manage the lifecycle (e.g., setup, configuration and teardown) of Kwites and all they need to operate in a cluster. A picture of that is as follows, further documented in the Kwite-operator repo.
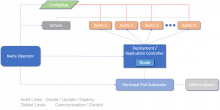
Note that Kwite-operator reconciles Kwite resource requests by managing the lifecycle of a fair number of supporting resources: Horizontal Pod Autoscalers, Deployments, ConfigMaps and Services. Most of those are the Kubernetes infrastructure resources necessary to scale and make available the Kwites, whereas the configuration of Kwites themselves are in the ConfigMaps.
That is pretty much how traditional CM solutions are often used to manage applications – build related infrastructure like network objects, lay down configuration files from templates, make sure there’s a port open to expose the (HTTP) service, etc. So yeah, Kwite-operator effectively is the CM solution.
Once an operator is in place in a Kubernetes cluster, it takes care of all CM for all services (Kwites in this case). With that, life is actually less burdensome on operations teams. For example, by specifying and submitting (e.g., via kubectl apply -f …) a simple Kwite custom resource declaration, such as that below, Kwite-operator will build, run and manage all the necessary cluster resources shown above.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
apiVersion: web.kwite.site/v1beta1 kind: Kwite metadata: name: kwite-1 spec: url: "/kwite" port: 8080 image: "concourse.corp.local/kwite:0.0.11" targetcpu: 50 minreplicas: 1 maxreplicas: 10 ready: "OK!" alive: "OK!" template: | <html> <body> <h1>My First Kwite</h1> <p>This is a kwite template where x is {{ .x }}</p> </body> </html> |
Can traditional CM tools do all that? Sure – by fully understanding and creating all the necessary Kubernetes resource manifests, for example with some Ansible template work, some CI pipeline scripting and a GitOps setup like Argo CD. Operator implementations are simply more elegant and manageable solutions and I foresee developers preferring them. Further, as discussed in the next section below, traditional CM approaches cannot actually compete with what operator implementations bring to the table.
Longer story short: Kubernetes operator pattern implementations and ConfigMaps are all you need for application CM in a Kubernetes world. Will the world ultimately be all Kubernetes API driven? If VMware’s Project Pacific and KubeVirt are any indication, it probably will. Given that, skilling-up on writing operator implementations might be a very good idea while the shift occurs.
Why Developers Will Further Encroach on IT Operations
The second part of my (probably) unpopular opinion is that because CM in Kubernetes is often an operator implementation, application developers will likely further encroach on IT operations, particularly with respect to CM.
Arguably the most obvious thing is that where it is appropriate to use Kubernetes operator implementations as CM, one should realize operators can be relatively healthy programming efforts. That is true regardless of the selected programming language and development framework (e.g., Kubebuilder or Operator Framework). With that noted, developing Kubernetes operator implementations is therefore not something IT operations would normally do, absent a good Site Reliability Engineering team or similar. Further, one can question even the need for SRE teams to create operator implementations for applications other than those they might write specifically for operations’ purposes.
The less obvious reason IT operations may not write operator implementations is operators arguably should have intimate knowledge of the ‘guts’ of application feature code.
Consider this Kwite-operator line of code:
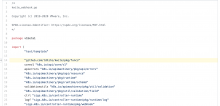
as well as the following line.

That all looks pretty innocuous, but in reality that code is binding Kwite feature code directly into Kwite-operator. Inextricably binding Kwite-operator (i.e., the CM solution) to Kwite (feature) code? Yes – and here’s why: in this case, the code is within Kwite-operator’s admission web hook. That is where Kwite-operator validates that Kwite templates successfully parse. If not, Kwite-operator rejects a request to deploy a Kwite – it will not even let such a Kwite into the cluster and that kind of run-time validation is always good.
To elaborate a bit, in order to most fully vet out the validity of a template any Kwite is supposed to execute to serve an HTTP request, Kwite-operator needs to know about and actually use the extended functionality Kwite injects into the template engine it uses. That information could conceivably come from a separate file or similar means, but that creates multiple sources of truth (Kwite source code and the secondary ‘separate’ file). In such a situation, Kwite-operator could not truly know if a template actually could successfully parse at run-time. The Kwite source code is the only real source of truth so we should use that in Kwite-operator. With Kubernetes operator implementations we can, but cannot with traditional CM solutions.
Longer story short: it is foreseeable that application developers will deliver application feature implementations along with a Kubernetes operator implementations as a single ‘application’ release. In other words, they will deliver to IT operations, similarly to Kwite, both the application code and CM as part of their daily work, alleviating the need for IT operations to write the application CM of their Infrastructure as Code.
Conclusions
When writing applications for Kubernetes, not merely getting applications to run on Kubernetes, the Kubernetes operator pattern allows and encourages application feature and line-of-business developers to take application CM work from IT operations. If and when that happens, traditional CM tools will be relegated to lower-level purposes. As noted above, one look at Project Pacific just may tell us that in the long term the Kubernetes API is headed toward near application CM ubiquity.


