
By, Luis M. Valerio Castillo, Consultant, PS Research Labs; Neeraj Arora, Staff Architect, PS Research Labs
In the article, Infrastructure Sub-Systems of an IoT Solution, we examined the high-level architecture in the infrastructure plane applicable to IoT deployments. We learned about Solution Components that form the ingestion system in an IoT Solution in the article Ingestion in a Modern IoT Application, and we explored a layered design approach with infrastructure sub-systems as a base to deploy the solution components and apply the six-processes of multi-cloud to realize the Ingest, Analyze and Engage process.
In this installment of our blog series, we will continue to use the People Counter Modern IoT Application as an example and focus on the inference solution components. Inference is where we turn raw data from the IoT devices into actionable information. Let’s get started!
Analysis is synonymous with inference, and you’ll find that we use either word to describe the same process.
Infrastructure Sub-Systems of Analysis
Analysis in the example People Counter Application has the following sub-systems:
- Compute Edge
- Cloud Services
Compute Edges must have networking capabilities to communicate with Cloud Services and enough computational capacity to process the data generated by devices. In our sample IoT application, the VM simulates the Compute Edge, which represents an Infrastructure Sub-System. To add inference capabilities, the VM runs the People Counter Inference microservice.
The application utilizes Cloud Services we’ll dive into in greater detail later in this post.
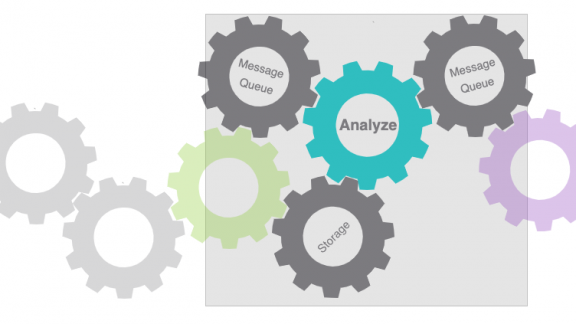
Solution Components
Solution components related to inference found in the example People Counter Application are:
- Deployment Platform
- Storage Platform
- Analytics Platform
- Connectivity Platform
Some items in this list should look familiar since they are also used for ingestion. Indeed, Raspbian OS is our Deployment Platform, MinIO is our Storage Platform, and the Connectivity Platform is a combination of REST and MQTT much like it was for ingestion. This should come as no surprise since the solution components are like Lego building blocks or gears which you can put together to build your solution. However, there is one platform that we have not covered in our previous post – the Analytics Platform, Algorithmia.
Algorithmia
Algorithmia is a platform that allows for the consumption of trained machine learning models with REST API calls. We selected Algorithmia as our Analytics Platform because their consumption-based pricing model allowed us to prototype the solution for a relatively low cost of a few cents per inference request.
Their operating model is not all that different from that offered by Amazon Rekognition.
Development Considerations
One of the early choices any developer has to make is one of a programming language for their product or module. Usually, different modules of a software are written in the same programming language unless there’s a compelling reason to do otherwise. However, with IoT where one might have multiple vendors involved, it is important to know that the choice of a programming language does not, for the most part, limit integration options.
Whereas we were somewhat tethered to using Python for developing the ingestion microservice, primarily because of the availability of a library that assisted us in reading images off of the Raspberry Pi camera, this isn’t the case with the inference microservice. Since the only ask a programming language has to satisfy is to give us the ability as developers to tie together Cloud Services, such as MQTT, MinIO and Algorithmia, with some amount of distributed systems logic, we’re not tied down to our choice of Python. These services have client libraries available in languages other than Python, such as Java and Golang. Any of these languages would do just as well to develop the microservice.
There are however benefits to consistently using the same language for different components of a well-integrated project. With the example People Counter Application, the ingestion and inference microservices consume object storage (MinIO) and message queue (MQTT) similarly. Using a common programming language thus allowed us to write common library code shared between the two microservice codebases, saving us valuable development and testing time.
With our programming language selection out of the way, the next decision we needed to make was on the method to extract a count of people from the photographs. Image analysis using a Machine Learning model is a fairly common functionality and available widely. Further choices we had to make were to train our own models or find already trained models to leverage. Once we had decided that we would leverage pre-existing trained models, the next choice was architectural – should we run the inference locally, or off-load it to a service provider? ML Training requires significant hardware (easy to procure) and a large quantity of curated and labeled data (difficult to procure). Although we have access to hardware, either purchased or consumed as a service, it was the inability to get enough curated and labeled data that cemented our choice. We opted for an already trained model provided as-a-service by a service provider.
Similar considerations around the ease of integration into a DevOps process and the costs of implementing a Proof-of-Concept led us to using Algorithmia. It has a Python client library, REST API and a trained ML model which could extract the count of people from a photograph. All of those capabilities allowed for rapid development and prototyping, which is one of the fundamental tenets of DevOps.
Deployment Considerations
As introduced with the ingestion microservice, MQTT and MinIO are consumed as-a-service. We’ll re-iterate that the deployment type i.e. As-a-Service or Self-Managed does not impact the ingest, analyze and engage architecture. That said, the locality of services deployment changes the performance characteristics of the application, and the locality might need to change depending on the environment in which the application operates.
Should a public cloud provider host the message queue, external connectivity is crucial and so is the reliability of that connectivity to ensure that all messages reach their intended destinations. This is easier to achieve with always-connected IoT devices and microservices, but differences in environments will change the choice of services and their deployment type. This also holds true for the Analytics Platform. There are cases where the locality of the Analytics Platform may need to change, but from a code perspective, it would still be valid to have one module make an API call into another module. As of now, we are consuming the ML model from the public cloud provider Algorithmia using APIs and client libraries. A similar model could be consumed locally via similar APIs and client libraries even if its deployment location was changed to the compute edge.
Data Orchestration Pipeline
The data orchestration pipeline we discussed in Ingestion in a Modern IoT Application (Ingest) extends further with the inference microservice creating the second stage (Analyze). A following blog post will introduce the third stage, i.e. Engage, thus completing the pipeline. For now, let’s take a cursory look at how the inference microservice works.
The first thing our microservice does is to subscribe to MQTT using the Paho MQTT Python client library. Once connected, the microservice gathers metadata on new photos available for analysis posted by the ingestion microservices. The metadata for each photo is JSON encoded and looks as follows:
{
‘type’: ‘data’,
‘deviceID’: ‘60261e35-7c0c-4ad2-9543-43855f35a1e6’,
‘filePath’: ‘people-counter-images/imagef9f90802-d5d2-44fb-bcd5-16cfc6ad6035.jpg’,
‘creationTimestamp’: 1577830187.990863
}
The inference microservice processes incoming photos as a batch with some smarts applied. Each instance collects a configurable number of photo metadata like the one shown above. When an instance is ready to process a batch, it informs all other inference microservices. There could be more than one inference microservice that tries to process the same batch of photographs. However, with some smarts, only one of them does, with the other instances going back to collecting metadata updates and preparing for the next batch.
Of the batch selected for processing, the microservice instance selects the latest photograph per device and submits these to the Analytics Platform, Algorithmia, for analysis.
This allows us to have many instances of the inference microservice running simultaneously and analyzing data from the same pipeline without interfering with each other. This also means that we can scale the number of microservices as the amount of data generated from IoT devices increase. Scalability is crucial for an IoT system that might end up having hundreds or thousands of devices gathering data. We will cover the inner workings of the distributed batch processing algorithm in a subsequent blog post.
The Analytics Platform completes the image analysis and delivers a count of the number of people in the photo. The results get pushed to MQTT for the next microservice to use. The processed image is no longer needed after the analysis and is deleted. Clean up of each photo after analysis is good practice for several reasons, the foremost ones being privacy, security and better resource utilization.
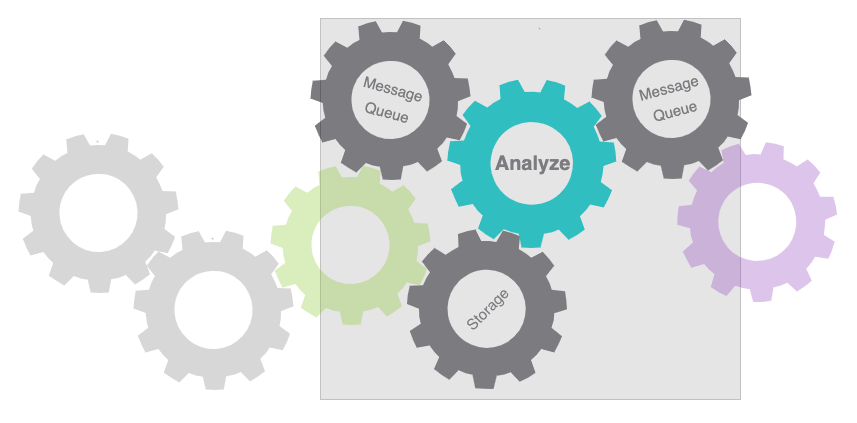
The following diagram illustrates the data flow and control:
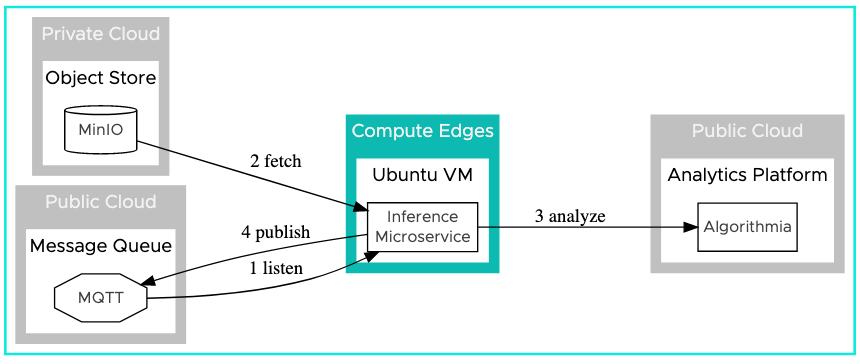
Notice the direction of the arrows which represent the interactions between the inference microservice and the other services. The order of operations are:
- Listen to MQTT for new image metadata
- Fetch the image from MinIO
- Analyze the image using Algorithmia to get the count of people
- Publish the count of people to MQTT
Conclusion
As we’ve discussed, both infrastructure sub-systems and solution components layered together to orchestrate analysis of photographs make up our inference architecture. The People Counter inference microservice is an implementation which demonstrates how the architecture looks like in practice. Next in our blog series, we will explore the Engagement stage of our modern IoT application.
About the Authors
Luis M. Valerio Castillo is a Solutions Development Consultant with PS Research Labs at VMware, focusing on IoT, and Edge Computing. Prior to this role, Luis worked in the field implementing solutions for customers, which included application deployment automation, third party system integrations, automated testing, and documentation. His six years of experience started at Momentum SI, which was acquired by VMware in 2014. He holds a Bachelor of Science, with a major in Computer Science.
Neeraj Arora is a Staff Architect with PS Research Labs at VMware. He leads the development of service offerings for Machine Learning, IoT, and Edge Computing. Previously, Neeraj was part of the VMware Professional Services field organization delivering integrations to Fortune 500 companies using VMware and non-VMware products. Industry experience includes gaming, utilities, healthcare, communications, finance, manufacturing, education, and government sectors. Neeraj has published research papers in the areas of Search Engines, Standards Compliance, and use of Computer Science in Medicine.