

Ten months ago, I joined xLabs, an “agile incubation lab” for all kinds of innovative ideas, within VMware’s Office of the CTO. I had just completed my PhD in computer science at George Mason University, with a focus on machine learning, federated learning, multi-task learning and deep learning. Now as a machine learning engineer tasked to work on an API security and analytics platform project (Project Trinidad), this role couldn’t be more aligned with my career goals.
The Project Trinidad team has six core members, including myself, and an extended team of the same number. Project Trinidad’s objective is to protect modern applications by detecting and blocking cyberattacks. It acts as an X-ray machine that allows us to study the internal communication of modern apps and monitor both north-south and east-west API communication between microservices. My mission on the project is utilizing the forefront of ML technologies (e.g., federated learning, deep learning) for anomaly detection, while maintaining the low false positives of our detection system.
Privacy-preserving ML with federated learning
At the initial development stage of Project Trinidad, the goal had been to develop centralized ML models for individual applications and leveraging this unique visibility, train models that capture the regular traffic and communication patterns of those applications that are normal. The models were to consider a range of basic network traffic properties, service-specific API function parameters and API sequences. When Trinidad identifies an attack, it reports an alert, and in the future, initiates an automated remediation response.
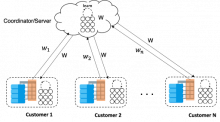
Conventional centralized ML approaches have always come with long-standing privacy risks to personal data leakage, misuse and abuse. Additionally, many customers don’t want data leaving their home environment. Federated machine learning (FML) has emerged as a prospective solution that facilitates distributed collaborative learning without disclosing original application data. Created by Google in 2016, FML is a machine learning paradigm used in many open source projects that trains a shared model across multiple decentralized applications, while keeping the data of each application locally. Moving computations to data is a powerful concept in building any intelligent system, but the game-changing facet of FML is that it simultaneously protects the data privacy of any individual application.
Prototyping Trinidad with FML: Enter OpenFL
When exploring open source FML projects that would collaboratively train a model without sharing sensitive information as an efficient solution for Project Trinidad, I identified OpenFL as a suitable fit. OpenFL is developed by Intel Internet of Things Group (IOTG) and Intel Labs and designed to solve horizontal federated learning problems. It introduces user sessions, long-living components that allow conducting several subsequent experiments while reusing existing connections, and an interactive Python API developed to ease adapting their one-node training code with minimal changes to provide developers the single-node experience. These characteristics make OpenFL work with remote data and start remote experiments easily.

In Project Trinidad, a group of applications have the same set of features (horizontal data). The combination of Project Trinidad with OpenFL, however, presents the same cross-silo federated learning problems — multiple applications with large amounts of data that share the same feature space.
The advantages of FML in Project Trinidad are:
- Keeping customer data locally to prevent privacy risks to personal data leakage
- Saving massive cost of moving data from customer’s own cloud
- Reducing the overall computation cost across all participating customers
- Improving the overall prediction performance by utilizing a much larger dataset from multiple customers
- Solving cold-start problems for new customers
We conducted some preliminary experiments with demo applications and received some promising results.
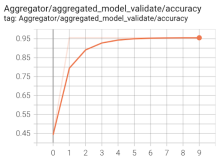
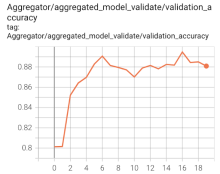
Prediction accuracy with FML on point anomaly detection (left: online-boutique) and sequence anomaly detection (right: HotROD)
Privacy-preserving and sustainable cross-application solution
There were additional, more advanced requirements to learn high-performance anomaly detection models in Project Trinidad, including protecting the data privacy of each application, so I designed a block-based feature processing component for it, which can be easily applied on different applications for feature extraction. These feature blocks can be used in any ML method for targeting different anomaly types (e.g., point anomaly, sequential anomaly) and provide flexible solutions for local model design with OpenFL. I am also working on designing an aggregation algorithm to leverage the most beneficial information on an optimal central model across all federated applications. Last but not the least, we want to look for more secure ways of protecting the data of each application in addition to keeping data on the applications, as there are risks of model leakages during the FML communications.
To achieve this, one aspect is using mTLS (mutual Transport Layer Security); another aspect is using homomorphic encryption (HE). Homomorphic encryption makes it possible to perform calculations on encrypted data. This means that data processing can be outsourced to a third party without the need to trust the third party to properly secure the data. With this technique, the FML frameworks in Project Trinidad will be much more robust against cyberattacks.
Another important aspect of using FML is the long term sustainability. There is a much lower network cost compared with centralized models as we no longer need to transfer customers’ data to a datacenter and benefit from a lower carbon footprint due to lower computation cost.
Our team has talked to design partners and customers who are very excited about this solution, and we expect to offer it to customers before the end of the year.
Machine learning is changing the world
Thanks to machine learning and deep learning, AI applications’ ability to self-learn and self-optimize enables organizations to adapt at speed, providing a steady stream of insights to drive innovation. But that’s not the reason I pursued my advanced education in computer science. It’s because humanity flourishes by innovating and we’re more productive, healthier and happier than ever before with machine learning tools.
Stay tuned to the Open Source Blog and follow us on Twitter for more deep dives into the world of open source contributing.




