

Digital innovation goes hand in hand with data. To be successful, businesses need to be data driven. But extracting value from data is a tedious process, and it’s only possible when the data system value grows faster than its cost. Data engineers face a lot of challenges to focus only on work that requires data engineers’ business domain expertise.
Versatile Data Kit is a data engineering framework that enables data engineers to develop, troubleshoot, run, and manage data processing workloads (called “Data Jobs”). A “Data Job” enables Data Engineers to implement automated pull ingestion (Extract and Load in ELT/ETL) and batch data transformation (Transform in ELT/ETL) into a data warehouse. This framework, in production for more than 3 years in VMware’s internal Data Analytics platform, helps VMware data engineers, analysts, and scientists manage hundreds of terabytes of data. Today, we are making this framework available in open source on GitHub as Versatile Data Kit.
A Closer Look
Let’s look at what data engineering challenges Versatile Data Kit tackles.
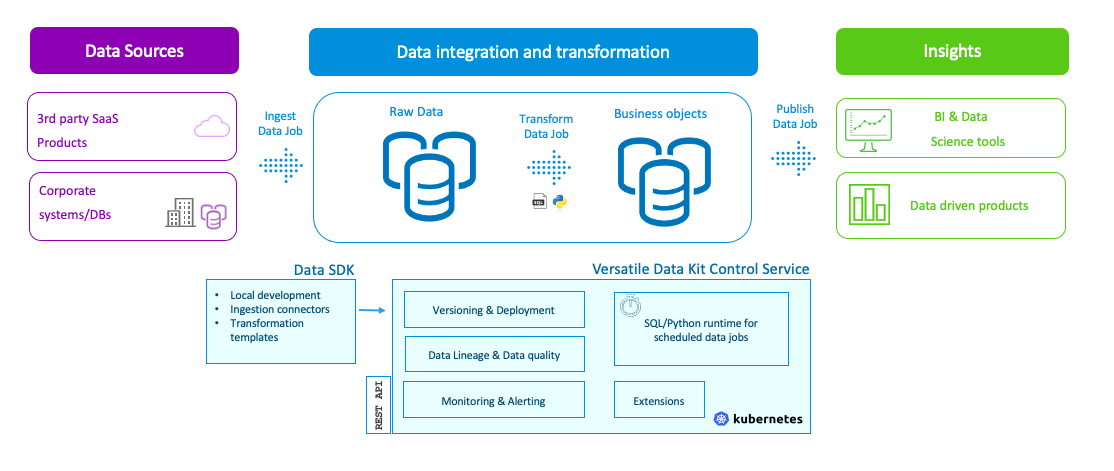
A core skill of data engineers is to understand the business domain and apply that business knowledge and data model or ML knowledge to create the correct model. For example, it may be a data model or fact and dimension tables that not only enable historical reporting and BI, but also enables companies to look forward by creating machine learning models and performing predictive analytics.
A big challenge for data engineers is how to focus on only those tasks that require their core data engineering skills. When building out a data product with standard tools, 10% of the effort requires using data engineer core skills, while the remaining 90% are tasks that require system or infrastructure knowledge. Those tasks are still critical work such as setting up packaging, configuration, monitoring, testing, deployment, and automation. Similar to how electricity today has become infrastructure that you buy from a utility company, that 90% should be provided by the tools around the data engineers as utility.
In the last decade, software development has evolved to fully owning the entire application lifecycle (DevOps) and introduced methodologies for building services (12 factor app). We can make those practices accessible to data engineers and analysts without needing to learn them.
Many best practices and patterns are established in the data engineering world (like Kimball’s patterns for data warehouse). Those practices can be automated and abstracted so that engineers do not reinvent the wheel or do the same tasks repeatedly.
A framework that provides such capabilities can make data engineers focus all their efforts only in the 10%.
Another big challenge is reducing “unplanned work.”
Unplanned work comes from incidents and issues or due to unforeseen consequences of the development work—data in a report suddenly shows unrealistic numbers, or a customer-facing application makes incorrect recommendations based on bugs in data.
Unplanned work is unpredictable as it can come at any time. It often pushes out planned work, breaks commitments, and lowers productivity.
To minimize time spent in unplanned work, it’s important to troubleshoot efficiently, and when in firefighting mode—quickly return to a stable state. All data applications consist of four basic elements—input (data), code (version), configuration, and dependencies (other software applications). By keeping track of both data lineage and code lineage (version of the code and its dependencies), a data engineer can scan the data jobs to quickly pinpoint and resolve issues.
Versatile Data Kit
Versatile Data Kit optimizes the work of data engineers at every step of the engineering cycle. In doing so, data practitioners can focus on work that requires business domain expertise.
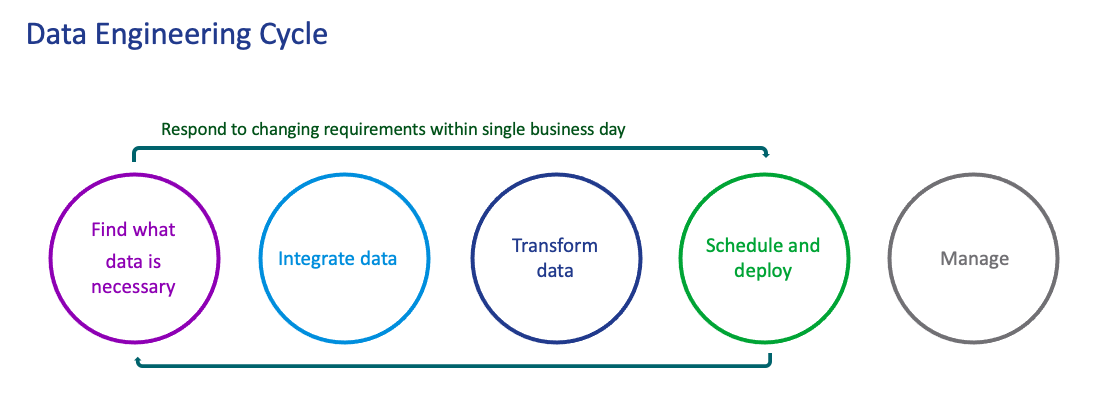
- Define and discover: If we look at a data engineer’s development cycle, it starts with defining the business problem and identifying the required data. Data engineers need to track data source owners, check out contacts, and find documentation about the data. Versatile Data Kit can keep lineage—enabling tracking this information. Versatile Data Kit keeps a catalog of all data applications which enables better knowledge sharing.
- Integrate: Versatile Data Kit automates data integration in an almost codeless flow—data engineers only need to specify the source and the source objects required and identify the destination database and tables. Versatile Data Kit then extracts the specified data and loads the database and tables automatically.
- Transform: Efficient data transformation requires simplifying complex transformation tasks. This starts with removing unneeded information—known as boilerplate—so engineers can focus on data modeling logic. This enables creation of declarative transformations using SQL only, implementing common data patterns like Kimball and when necessary, using the full power of Python.
- Deploy: The ideal state for data engineers is a single click deployment of their data applications. Versatile Data Kit takes care of building, packaging, versioning, and scheduling the data applications.
- Manage: To efficiently manage many applications, Versatile Data Kit takes care of monitoring, tracking data lineage, and code lineage—thus enabling engineers to quickly pinpoint issues and revert to the latest stable version.
Versatile Data Kit consists of:
A Data SDK which includes the building blocks to build data applications with minimal effort and a plugin framework to extend or inspect any part of the data application.
A Control Service Server that enables users to manage data jobs by building, packaging, installing, tracking dependencies, and maintaining versioning. Jobs are run in a managed runtime environment with telemetry, logging, notifications.
Try it Out and Get Involved
While the project has been in development for some time, it still has a long way to go. And now that it’s open source we look forward to new insights and fresh ideas. We welcome everyone to join and contribute—whether you’re a data engineer or an analyst who wants to try out the project and provide feedback, ideas and a fresh perspective or an engineer who wants to contribute to the project by adding a new database connector via the pluggable architecture, or a completely new core feature—you are welcome.
You can check out Versatile Data Kit GitHub repository here: https://github.com/vmware/versatile-data-kit
Please check out the Versatile Data Kit GitHub repository and join our public Slack workspace.



