

Our Cloud Providers offer Disaster Recovery services and backup and restore services using all sorts of technologies, these are often measured against each other for their relevant benefits or shortfalls. Specifically, Disaster Recovery, there are two key technologies that you can use to replicate data; journaling & snapshots, each has its pros and cons. In this blog we will look around each and hopefully detract from some of the myths around both.
Firstly, snapshots. What are snapshots?
Snapshots are a point in time of the state and data of a Virtual Machine (VM), they should not be considered a backup. The state includes the VM’s power state at the time of snapshot and data includes all files and folders that constitute the VM, including VM file items like memory and vNIC, vmdk etc, this typically is achieved by ‘stunning’ the VM or quiescing. (Stunning a VM makes the VM temporarily unavailable for operations like vMotion, snapshot, etc and unreachable, meaning there is application outage.)
Always consider the ‘state’ of a replication, if the OS does not support quiescing, then you should be carefully considering the process to recover in the event of a Disaster to ensure continuity for your application type – do not forget this!
Why should they not be considered a backup? Well simply put, they are useful for a quick rollback point, as they primarily record delta between the original source disk from a certain point in time, also the parent must be on the same storage infrastructure for this to work. Backups need to be separately and whole (not dependant on parent), and certainly not on the same infrastructure they are protecting from failure. Snapshots are therefore inherently – short term.
Does VMware Cloud Director Availability use snapshots?
In a nutshell, no, we do not. We use Delta vmdk at the source and Point in Time (PIT) instances at the destination, these are not the same as snapshots. Multiple Point in Time (PIT), mPIT, are based on deltas from the source disk, these are sent via the Host Based Replication agent (HBR) IO Filter on the ESXi host. VMware Cloud Director Availability does not stun the VM for the source replication therefore it is not the same as a snapshot.
vSphere Replication, has several components that are used by VMware Cloud Director Availability; the Data Mover and the Host Based Replicator (HBR) services on ESXi hosts, these essentially filter the IO from the running VM to the lightweight delta syncs, which is then replicated to the target site via a Replicator Appliance. You can have multiple PITS (mPITS) and vSphere Replication supports 24 instances – that’s 23 lightweight deltas from the initial sync before they are cycled and overwritten.
For the initial sync, only the written areas of the ‘base’ disk of the VM are marked as ‘dirty’ and the whole vmdk is copied, this does cause a small increase in IO as disk is being replicated, and the time it will take will depend a lot on the source and target datastore types. From this point on only delta changes are marked as dirty and needing copy.
Let’s define what is an initial full sync
When replication is first configured using VMware Cloud Director Availability for a powered on virtual machine. The entire contents of a source virtual disk (VMDK) are copied to its target empty virtual disk (which is created at the target location), these are compared using checksums. This process identifies the differences between the source and target virtual disks, which in a new replication is zero, requiring very few CPU cycles. While checksum comparisons are being calculated and compared, vSphere Replication will periodically send any differences that were discovered. The amount of time it takes to complete a full sync primarily depends on the size of the virtual disk(s) that make up a virtual machine, the amount of data that must be replicated, and the network bandwidth available for replication.
How about lightweight delta syncs?
After a full sync is completed, the vSphere Replication agent built into vSphere tracks changes to virtual disks belonging to virtual machines configured for replication. A lightweight delta sync replicates these changes on a regular basis depending on the recovery point objective (RPO) configured for replication of a virtual machine. For example, changed data in a virtual machine with an RPO of four hours will be replicated every four hours. Data at the 4hr window will go into the lightweight delta vmdk, so anything added and removed within the 4hrs will not be in the delta, this reduces networking traffic as multiple writes to the same block within the RPO interval will only result in the last value being sent at sync time. This schedule can change based on a number of factors such as data change rates, how long each replication cycle takes, and how many virtual machines are configured for replication on the same vSphere host. vSphere Replication uses an algorithm that considers these factors and schedules replication accordingly to help ensure the RPO for each replicated virtual machine is not violated.
Thanks @jhuntervmware for the blog relating to this.
What about performance?
The more lightweight delta sync vmdk you have, the more potential variant data between the deltas, the longer it will take to restore as the more delta ‘drift’ from the base, the more compute and storage will be needed to consolidate all the differences. Also, the more you maintain, the more disk space will be used. If the destination datastore runs out of space, no new delta instances can be created, but the existing instances are unaffected. When free space becomes available a new incremental instance is created (albeit likely with some RPO violation), but there are no re-syncs.
With VMware Cloud Director Availability, we use SLA policies to control what is allowed for replication retention policies (number of PIT instances) and an overarching Recovery Point Objective. Remember a PIT is a lightweight delta sync, i.e., a vmdk delta record, but it is not a whole vmdk as there has been no stunning or cloning, it is a subset of the chain from the base disk to a designative instance and is an independent flat vmdk.
Lightweight vmdk delta sync are cascading and interdependent, there for each time an instance expires some disk space is freed. You can retire instances explicitly, or you can urgently reclaim space after unusual I/O events that create larger instances, by adjusting the Cloud Director Availability retention policy. This will retire (a.k.a. consolidate) the instances. Then you can restore your normal retention policy when the space is available. Providers can monitor all aspects of IAAS consumption and view storage allocated vs used by tenant organization.
Stored instances – are these backups or snapshots?
Stored Instances in VMware Cloud Director Availability are delta vmdk. They are deltas that have been ‘taken out’ of the retention cycle and therefore needs the parent disk to be used for a restore purpose. A VMware Cloud Director Availability replication can have both stored instances and rotated instances (mPITS) and these are controlled by policies. These will be relatively fast to restore in comparison with ongoing deltas (they will be closer to the source parent) that will grow (‘drift’) as time moves on.
Does consolidating disks help increase recovery speed?
Yes and no. Consolidating takes the base disk and all the deltas into account, this disk hierarchy consolidation process runs to the restore point required. It is a compute and storage intensive task to aggregate and compare the deltas, and from that point on all deltas are created with the consolidated disk as the parent. For a failover, consolidating when there is a disk hierarchy of deltas will not be quicker if there are a lot of delta vmdk to compare, especially if there is a high data change rate. However, from that point on recovery will be fast as the ‘drift’ between the base vmdk and delta vmdk will be less. VMware Cloud Director Availability allows you to force consolidation as a part of recovery, or later regardless of the VM power state.
What about RPO & RTO?
Some vendors state a very fast RPO with journaling, this is true where every changed data block is written constantly to the target, why then would I use delta instances? The typical VM generates valuable data that needs to be replicated, using split IO whereby IO goes to 2 points; the VM and the target recovery delta or journal, there is virtually zero recovery time objective (RTO), until data is generated. Of course, data is generated, after all you are ensuring recovery of an important workload, so there is little chance it will stay still. When data is generated, journaling, which delivers ultimate granularity, considerably increases in RTO, the more data written, the longer the recovery time objective (RTO) to consolidate. With MPITs there is also an RTO impact, the impact is as big as the time to compute the delta difference between the source parent and the desired MPIT to restore, unlike journaling, most of the consolidation will be already done in the delta. As already stated, the more MPITs in between the longer the RTO. Remember the data is still at a granular RPO (VMware Cloud Director Availability supports 5min RPO), but the time to restore (RTO) is longer as compute is needed in both journaling and MPITs to recover the data.
A good rule of thumb for high data intensive workloads would be to consolidate regularly and keep the number of MPITs low so they are never too far away from the parent base disk. For low data intensive VMs you can significantly expand the number of MPITs and consolidate on rotation as required.
Another point to note about RPO and data generation. When data runs though the IO Filter, it is directed to the VM datastore and (depending on the technology you are using) to a lightweight delta vmdk or to a journal. The route to that destination needs to be fast, especially for journaling and the traffic volume will be high if every block of data change is being written 24/7. However, Delta instances only execute on the replication schedule, hence traffic is low and volume of data is low, usually this radically simplifies networking and makes for a much simpler deployment and operational solution to support.
The consideration?
Speed of recovery (RTO) and acceptable data loss (RPO) for a VM
vs
Minimizing data loss (RPO), but increasing recovery time (RTO)
What about rehydration?
Just like animals need to rehydrate, so too data, which needs to be accessible, needs to be decompressed to be useful. Some vendors point out that the recovery rehydration process is ‘instant’, there is no ‘instant’ in decompression, which uses compute; affects performance and disk storage space utilization. When data is rehydrated the data blocks are rendered on the disk in their original form. This can be ‘optimized’ to negate long term disk impact by vendors supporting rehydrate on read functions, however this will still affect the storage used whilst the data is rehydrated.
Journaling has a rehydration process that is compute and storage intensive (imitates file system and needs to convert data to vSphere format) so, in summary, there is an impact on performance to use journaling with rehydration.
VMware Cloud Director Availability uses native vmdk, so there is no need to covert the data to a vmdk format, it is already in this format and hence is optimized out of the box.
So what if I need the fastest recovery from malware.
Firstly, let’s look at the recovery point. Journaling tech offers granular flexibility in recovery, as recovery can be instantiated from any point. Whereas PITs are set at regular intervals.
Let’s take an example, your VM has a 4hr RPO, you discover ransomware on your VM at 12.30 post infestation (point B) on the graph below.
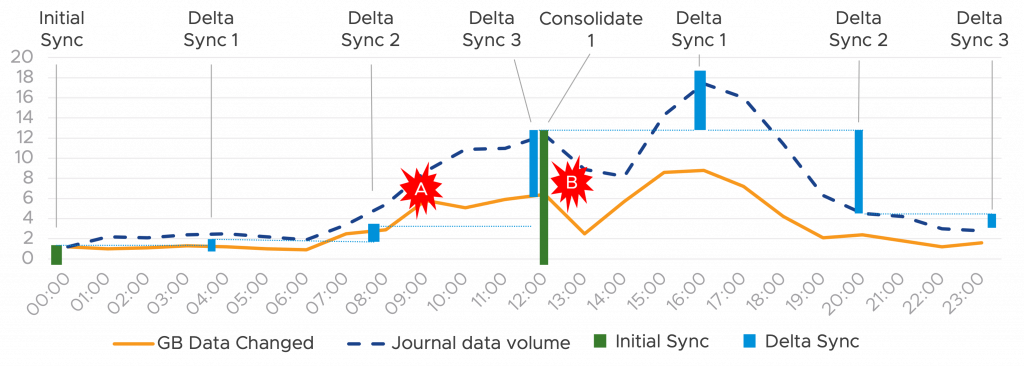
The actual infection was delivered by a trojan horse at 9AM but did not activate until 13:00. Therefore, the ransomware trojan horse was replicated in the lightweight delta sync at Midday, you would need to go back to the previous delta 4hrs before at 8AM, meaning 4hrs of data is lost, but the ransomware would not be present. Is 4hr data loss acceptable? This is the granularity impact and aligned to RPO.
However, the speed of recovery is important, in this case you have several restore points to choose from. You would start with a restore the previous delta, which in this case is a consolidated vmdk, not a delta, and hence the compute comparison against changed blocks on the consolidated delta would be nothing as there is nothing to compare. This would be a fast recovery, but the Trojan horse is still present. Going back to the next delta would be at 8:00AM and wouldn’t contain the trojan horse, this would need to be compared against the last deltas and consolidated source disk, but given the volume of delta changes is small, again this would be a fast RTO. Although you have some data loss you are up and running again fast.
As a rule, the granularity RPO should be aligned to the criticality of the VM. VMware Cloud Director Availability supports a 5min RPO, but the actual recovery time would be the key difference and that would depend how far the delta is away from the source consolidated disk. Keeping the number of recovery points low will ensure a faster recovery as consolidation will happen faster and there is less data drift between source and the last delta. Our recommendation is to find an acceptable RPO and number of mPIT, then use backup to take a permanent copy.
Journaling on the other hand provides 100% granularity, with every block changed, replicated, there is potential for zero data loss, but this doesn’t allow for application consistency, as with lightweight delta, unless quiescing is used (and even then) there is no guarantee of success, particularly with memory resident applications. As I mentioned at the start of the blog, ‘always consider the ‘state’ of a replication’.
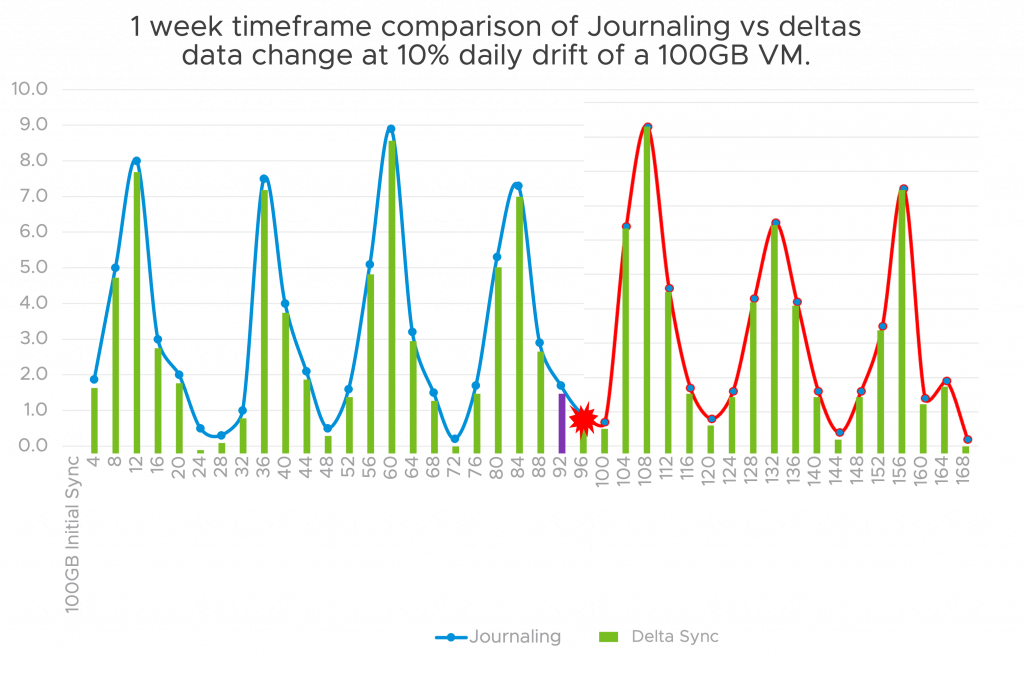
However, with journaling you can rewind and recover from any point in time, if there was malware detected in the chart above, you could ‘rewind’ to any point on the blue line, before the event. You can also do file level restore, which is an advantage over lightweight delta. As you can see the deltas only run on the 4hr window and not consistently like journals, hence the closest delta would then be measured against the source vmdk at the last consolidation. As with everything there is a tradeoff; journaling can bring granularity, but at what cost?
- Networking: Journaling requires fast network speeds to copy each byte, this is often done locally to avoid this overhead, also often journal data will be compressed at source; this is needed to minimize bandwidth requirements. This gives the added ability to recover locally also and faster, but this is dependent on the type of disaster you are recovering from. Faster networks cost more and are more complex, this means you can expect to spend more for this solution. A core difference with Lightweight Deltas is that multiple writes to the same block within the RPO interval will result in only the last value being sent. This reduces the network usage.
- Storage: whilst both use storage, the amount used will depend on the granularity of sync, the more granular the more data needs to be stored. In this case journaling will create the most storage overhead as at the target site the data disk + the journal would be kept, but the flip side is a more granular restore capability.
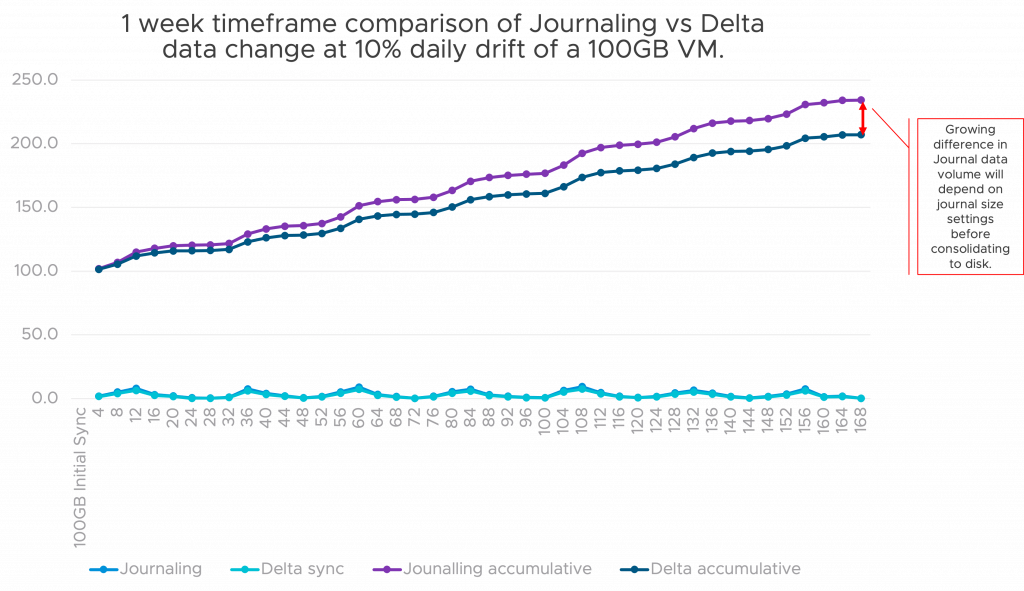
As the diagram above shows, whilst the volume of data for journaling and Delta sync processes is not really a storage factor (more a networking one), the aggregated storage volume is. The further along the timeframe, the more there is a difference between aggregated storage of journal vs delta.
Note that this is not including any deduplication storage technologies at the target site but is an accurate representation of volume.
So, in conclusion, what is the best choice?
Hopefully what I have laid out is that there is no simple answer to this, much of the performance depends on the data change rate you will have and the granularity of restore you want. Don’t be mistaken. There is no clear winner, each approach to replication and recovery has positive and negative points, and there is a commercial cost that I have not explored here also.
I think the major take home to make is that there is no real per second RPO (without synchronous replication with expensive storage arrays and very costly networking), this only exists if there is no data change, and then, that would perhaps apply to all products. Would the fastest be the native VMDK solution that doesn’t need conversion? It is a moot point as there is very little chance of zero data change in reality.
Reality means large volumes of data, reality means unpredictable scenarios, reality means communication ups and downs, and unexpected spikes in utilization. Just like your cloud choices, it’s the right DR solution for the workload, that is what is important. Remember the key levers:
- Compute resources: Journaling will probably require more compute than deltas but this is dependent on consolidation schedules. Keeping smaller journals and less deltas will minimize compute overhead when comparison operations are required for restore.
- Storage: Again, the more granularity, the more storage needed. Be sure to assign the correct level of granularity to the VM criticality.
- Network: Journaling, replicating off site consistently will need to have assigned bandwidth reserved so that replication is not affected. Local replication will minimize WAN costs but will not provide regional protection.
- Granularity RPO: How much can you afford to lose? Nothing, then journaling is your answer, 5 min or more, then lightweight deltas will be a suitable solution. Again, be sure to assign the correct level of granularity to the VM criticality.
- Time to recover RTO: For Deltas, this will be dependent on data drift and the number of deltas between the last one and the last consolidated vmdk. For journaling this will again be dependent on the amount of journal data that needs to be consolidated and converted to vmdk format.
As with many technical solutions, there is no right and wrong about journaling or deltas, these are just the typical DR replication types. There is however a cost consideration, if you need the granularity of journaling, then there is likely to be higher costs in storage and critically networking.
