

Ready to get hands-on with VCF 9.0? Dive into the newest features in a live environment with Hands-on Labs that cover platform fundamentals, automation workflows, operational best practices, and the latest vSphere functionality.
Check out our latest Hands-on Lab and experience Lifecycle Manager, Resource Management, Live Patch, Memory tiering and more in a live VCF 9 environment.
Lifecycle Management
vSphere Upgrade Path: vSphere 9.0 supports direct upgrade from vSphere 8.0. Upgrading directly from vSphere 7.0 is not supported. vCenter 9.0 does not support managing ESX 7.0 or earlier. The minimum supported ESX version that vCenter 9.0 can manage is ESX 8.0. Baseline-managed (VUM based) clusters and standalone hosts are not supported in vSphere 9. Clusters and hosts must use image-based lifecycle management.
Live Patch even more of ESX: Live Patch is extended to more of the ESX image, including vmkernel and NSX components. Increasing the frequency that patches can leverage live patch. NSX components, now part of the base ESX image, can be patched using the live patch process without hosts entering maintenance mode and needing VMs to evacuate the hosts.
Vmkernel, user-space and vmx (virtual machine execution) and NSX components can leverage live patch. Click to read more…
ESX services (for example hostd) might require a restart during a live patch which can cause ESX hosts to briefly disconnect from vCenter. This is expected behaviour and does not impact the running virtual machines. vSphere Lifecycle Manager reports what services or daemons will be restarted as part of the live patch remediation. If the vmx (virtual machine execution) environment is being live patched, running VMs will perform a Fast-Suspend-Resume (FSR). Live patch is compatible with vSAN clusters. vSAN witness nodes are not compatible with live patch and will undergo full reboots when patching. Hosts using TPM and/or DPU devices are not currently compatible with live patch.
Build Clusters Your Way with Mixed Hardware Clusters
vSphere Lifecycle Manager supports mixed vendor clusters, as well as support for multiple hardware support managers per cluster. vSAN includes support for mixed vendor clusters.
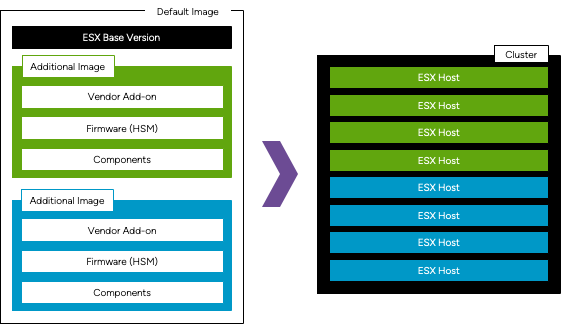
Clusters can have up to 4 additional image definitions to make on a single composite image of the cluster. Click to read more…
The base ESX version is static for all additional images and cannot be customized. The vendor addon, firmware, and components of each image definition can be customized to accommodate clusters with mixed hardware. Each additional image definition can have a unique hardware support manager (HSM) attached.
Additional images can be manually assigned to a subset of hosts in a cluster, or automatically using System BIOS information including Vendor, Model, OEM String and Family values. For example, you can have a cluster that consists of 5 Dell hosts and 5 HPE hosts where the Dell hosts can be assigned one image definition with Dell vendor addon and Dell HSM, and the HPE hosts can be assigned a different image definition with a HPE vendor addon and HPE HSM.
Manage Multiple Images at Scale
vSphere Lifecycle Manager images and image-to-cluster/host assignments can be managed at a global level (vCenter, Datacenter, Folder). A single image definition can be applied to multiple clusters and/or standalone hosts from a central view. Compliance, Pre-check, Stage and Remediation tasks can be performed at the same global level.
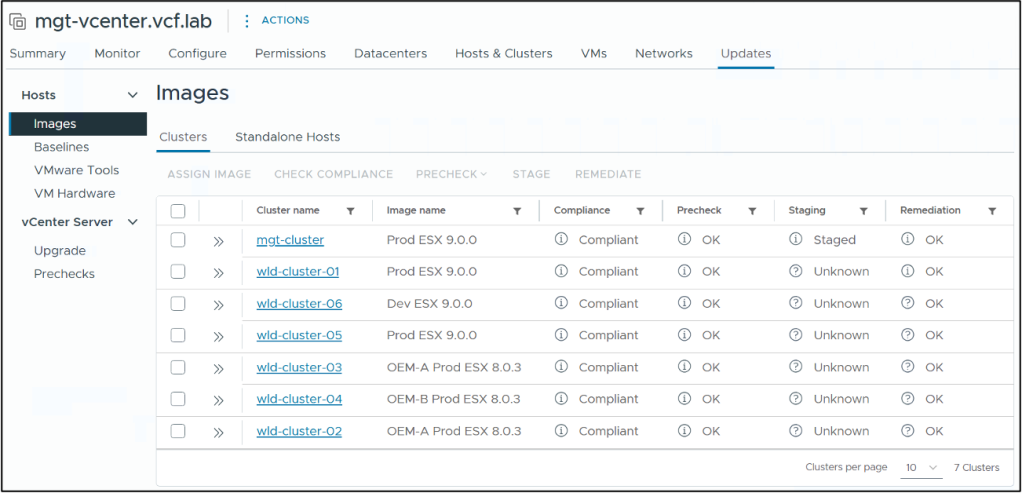
Existing baseline-managed (VUM based) clusters and standalone hosts running ESX 8.x can be managed by vSphere Lifecycle Manager but must be transitioned to image-based in order to upgrade to ESX 9. New clusters or hosts cannot be baseline-managed even if they are running ESX 8. New clusters and hosts automatically use image-based lifecycle management.
More Control over Cluster Lifecycle Operations
When remediating clusters, you have a new option to remediate a sub-set of hosts in a batch. This is in addition to remediating the entire cluster, or remediating just one host at a time.
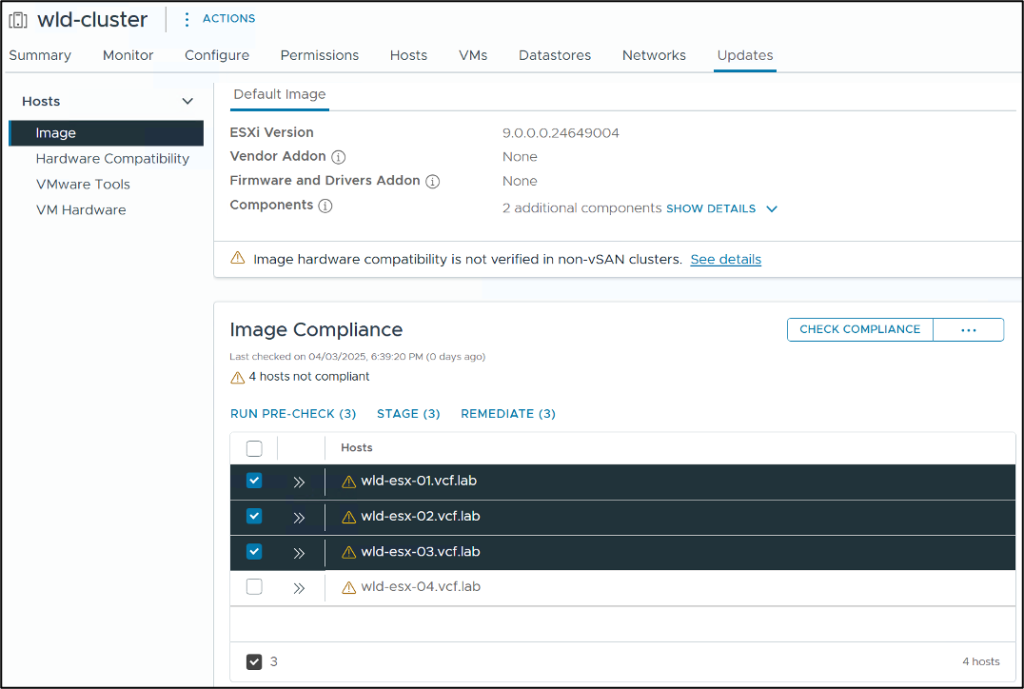
This provides flexibility to customers to select hosts that they would like to upgrade before some other hosts. Another use-case is if they have a large number of nodes in a cluster and upgrading all is not possible in a single maintenance window customers can multi-select hosts in groups to upgrade separately in multiple maintenance windows.
Take the Guesswork out of Updates and Patches
The vSphere Lifecycle Manager recommendation engine takes vCenter versions in account. vCenter version must be higher or equal to the target ESX version. For example, if vCenter is running 9.1, the recommendation engine will not advise updating the ESX hosts to 9.2 as this would put the hosts at a higher version compared to vCenter and into an unsupported configuration. vSphere Lifecycle Manager uses the Broadcom VMware Product Interoperability Matrix to ensure that the target ESX image is compatible and supported with the current environment.
Streamlined Cluster Image Definitions
vSphere HA and NSX components are embedded into the base ESX image. This makes the lifecycle and compatibility of these components more seamless. vSphere HA and NSX components are automatically life-cycled when performing a patch or update to the base ESX image.
Speeds up activation of NSX on vSphere clusters as the VIBs do not need to be pushed and installed by ESX Agent Manager (EAM).
Likewise, vSphere HA VIBs do not need to be manually pushed to each ESX host. Click to read more…
- Improved Reliability: You can expect a more robust and dependable HA environment.
- Faster, More Dependable Deployment: By including the FDM VIB in the ESXi image, the deployment of vSphere HA components will be significantly faster and more reliable.
- Reduced Disruption: Eliminating the need for frequent VIB pushes over the network minimizes disruptions to availability services.
- Streamlined vSphere HA: This improvement simplifies the deployment process, making vSphere HA easier to set up and maintain.
Define and Apply NSX Configuration for vSphere Clusters using vSphere Configuration Profiles
NSX integration with vSphere Configuration Profiles managed clusters. NSX Transport Node Profiles (TNP) are applied using vSphere Configuration Profiles. vSphere Configuration Profiles can apply the TNP to the cluster alongside other configuration changes.
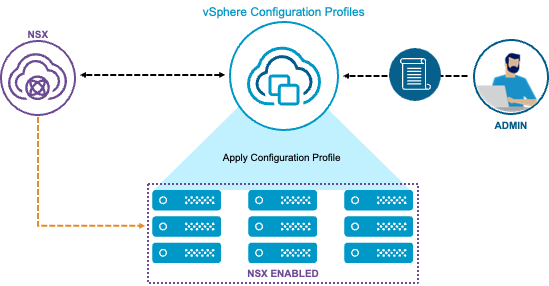
vSphere Configuration Profiles is the recommended configuration management for vSphere clusters as Host Profiles are deprecated in VCF 9.0. Click to read more…
The option to use NSX Manager to apply a TNP is disabled for clusters using vSphere Configuration Profiles.
To apply the TNP using vSphere Configuration Profiles, a Firewall Ruleset for ‘DVFilter=true’ and a Syslog setting for ‘remote_host_max_msg_len=4096’ are also needed.
Reduce Risk and Downtime When Patching vCenter
Reduced Downtime Update (RDU) is supported using the CLI based installer. RDU APIs are available for automation. RDU supports manually configured vCenter HA topologies as well as all other vCenter topologies. vCenter RDU is the recommended method to upgrade, update or patch vCenter 9.0. vCenter RDU can be performed using the vSphere Client, CLI or API. The Virtual Appliance Management Interface (VAMI) and patching APIs can also be used to perform in-place updates and patching of vCenter however this will require a large downtime.
Target vCenter VM network configuration supports an automatic setting to facilitate the transfer of data from the source vCenter. Click to read more…
This network is automatically configured on the target and source vCenter VMs using an RFC3927 Link-Local 169.254.0.0/16 address 169.254.0.0/16. This means that you do not need to specify a static IP or use DHCP for the temporary network.
The switchover phase can be performed manually, automatically or now scheduled for a desired date and time in the future.
Resource Management
Scale Memory Capacity with Lower TCO using Memory Tiering with NVMe
Memory Tiering leverages PCIe-based Flash NVMe devices to act as a second layer of memory, resulting in an increase of available memory within the ESXi host. Memory tiering over NVMe lowers total cost of ownership (TCO) and increases VM consolidation by directing VM memory allocations to either NVMe devices or faster dynamic random-access memory (DRAM) in the host. This allows you to increase your memory footprint and workload capacity, while reducing the total cost of ownership (TCO). Improve CPU core utilization and server consolidation, increasing workload density.
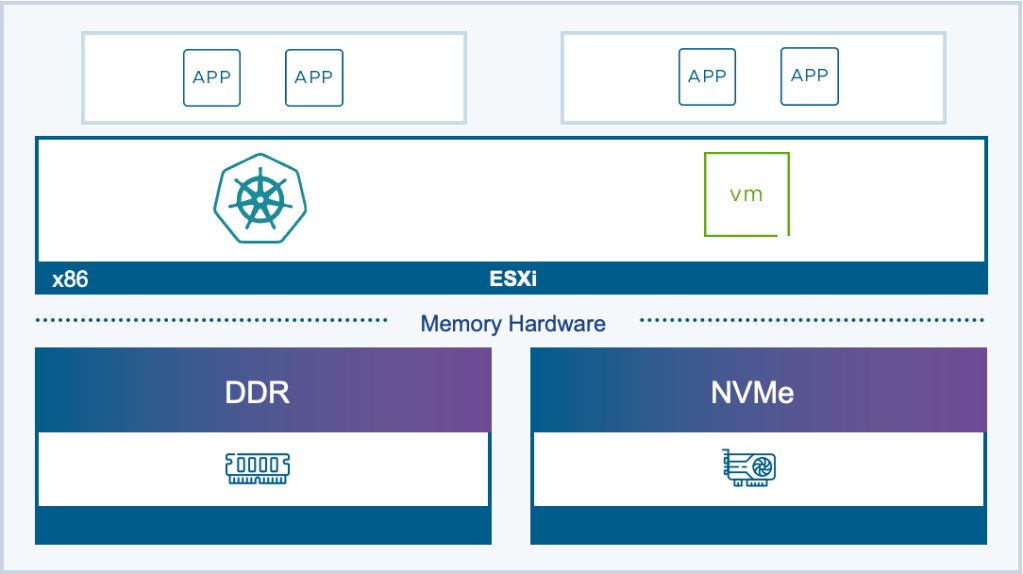
vSphere 8.0 Update 3 launched with a tech preview the Memory Tiering capability and it is now GA with VCF 9.0 which allows you to use NVMe devices that you can add locally to an ESXi host as tiered memory. For more about Memory Tiering in VCF 9.0, see https://blogs.vmware.com/cloud-foundation/2025/06/19/advanced-memory-tiering-now-available/.
Increased Uptime for AI/ML Workloads
Fast-Suspend-Resume (FSR) performs significantly faster for vGPU enabled VMs. Previously FSR for two L40 GPUs each with 48GB memory would take ~42 seconds. Now this takes ~2 seconds. FSR allows for clusters hosting Gen AI workloads to use live patch for non-disruptive patching.
Click to read more…
vGPU data channel streaming is designed to transfer large amounts of data, and architected with multiple, parallel TCP connections and autoscaling to the upper link bandwidth, up to 3x faster ( from 10 Gbps to 30 Gbps). By leveraging the zero copy concept, the number of copies required is reduced by half, removing the bottleneck of copying the data and further improving the bandwidth for the copy. vMotion pre-copy is a technique used to transfer the VM memory to another host with minimal downtime.
It copies both cold and hot memory in multiple passes while the VM is still running, eliminating the need to checkpoint and transfer all memory during the downtime.
The improvement for cold data pre-copy can be workload dependent. For example, for a GenAI workload with lots of static data, the stun-time is expected to be ~1 second for a 24GB GPU workload, ~2 seconds for a 48GB GPU workload, and ~22 seconds for a large 640GB GPU workload.
For more about vMotion enhancements for vGPU VMs, see https://blogs.vmware.com/cloud-foundation/2025/06/19/enhanced-vmotion-for-vgpu-vms-in-vmware-cloud-foundation-9-0/
vGPU Profile Visibility with vSphere DRS
vGPU allows a physical GPU to be shared among multiple VMs and helps with maximizing GPU utilization. Enterprises with a significant GPU footprint often create many vGPUs over time. However, admins are unable to easily view already created vGPUs, requiring manual tracking of vGPUs and their allocation across GPUs. This manual process wastes admin time.
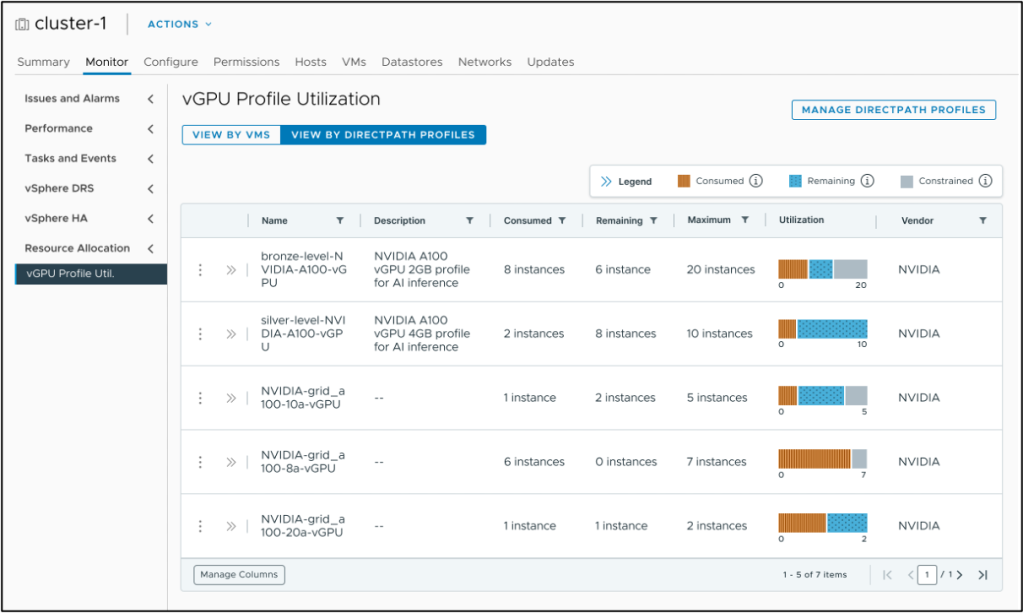
Profile utilization of vGPU profiles allows administrators to view all vGPUs across their GPU footprint via an easy-to-use screen in vCenter and eliminate the manual tracking of the vGPUs and hence will significantly reduce admin time.
For more about vGPU profile usage and capacity, see https://blogs.vmware.com/cloud-foundation/2025/06/19/viewing-usage-capacity-for-virtual-gpus-in-vmware-cloud-foundation-9-0/
Intelligent vSphere DRS GPU Resource Placement
In previous releases, the distribution of vGPU enabled VMs can result in a scenario where no single host can satisfy the vGPU profile of a new VM.
Today, admins can reserve space for vGPUs for future use. This allows them to allocate GPU space for GenAI applications in advance, potentially avoiding performance issues when these applications are deployed. With the launch of this new capability, admins will be able to reserve resource pools for vGPU profiles ahead of time, for better capacity planning, and improving both performance and operational efficiency.
Template and Media Mobility with Content Library Migration
Administrators can migrate existing content libraries to new storage datastores. OVF/OVA, media, and other items will be migrated. Items stored in the VM Template (VMTX) format are not migrated to the content library destination datastore. VM Templates always reside in their assigned datastore and only have pointers stored in the content library. The content library will enter maintenance mode and return to active state after completing the migration. During migration all library content, except for VM templates, will be inaccessible. Content library changes will be deactivated. Synchronization with subscriber libraries will be paused.
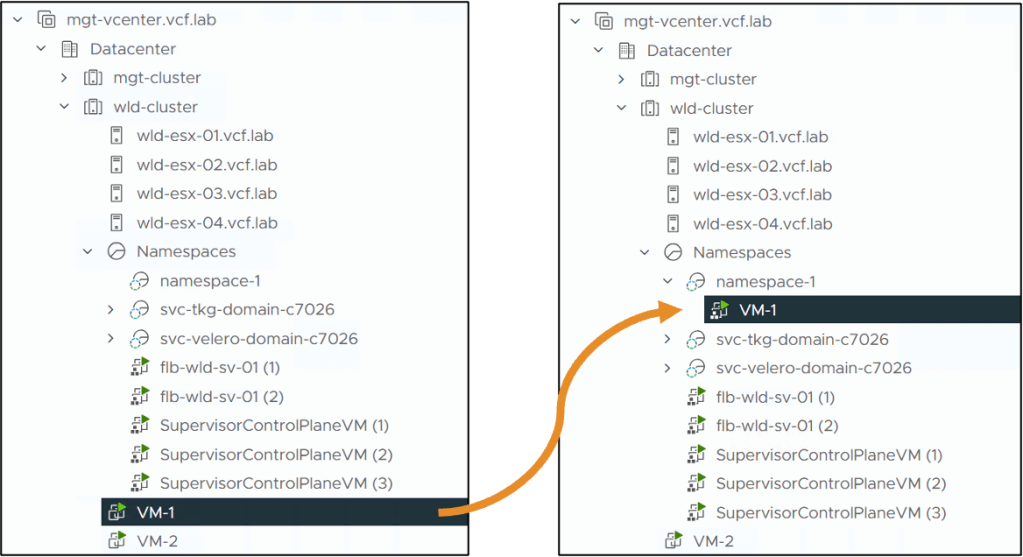
vSphere vMotion between Management Planes
The VM Service can import virtual machines from outside a supervisor cluster and take over management of these virtual machines.
Network I/O Control (NIOC) for vMotion using Unified Data Transport (UDT)
vSphere 8 introduced the Unified Data Transport protocol for cold migration of data disks previously migrated by NFC, which speeds up cold migration but with higher efficiency comes higher network saturation on the provisioning network that today shares a category with critical management traffic. NIOC is needed to ensure that management traffic will not suffer while customers can take advantage of the performance boost UDT provides. vSphere Distributed Switch 9 introduces a system traffic setting for provisioning traffic to allow NIOC to be configured.
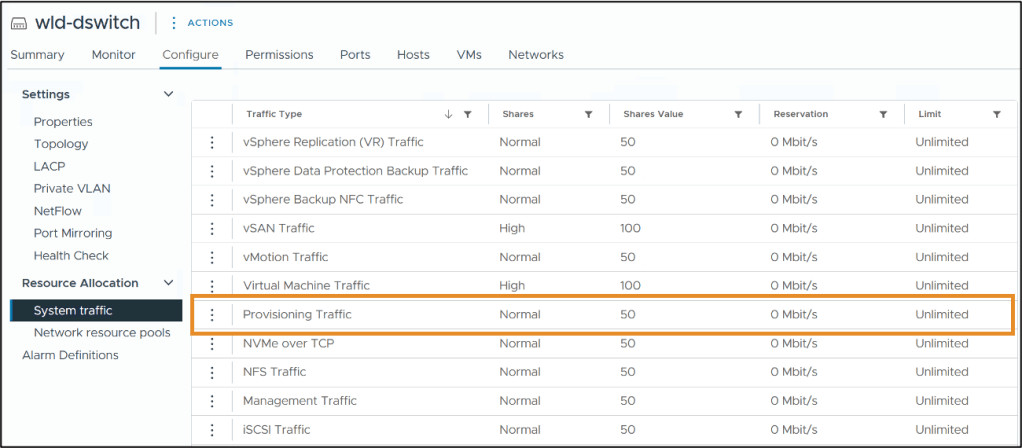
Provisioning/NFC traffic is heavy-weight and low in priority, but shares the same category with management traffic, which is supposed to be light-weight and highly prioritized. Given we have made provisioning/NFC traffic even more aggressive with NFC (Network File Copy – Streaming Over vMotion) SOV, it’s only a matter of time before critical management traffic suffers. We have an agreement with VCF that once NIOC for Provisioning/NFC traffic is in place, NFC SOV can be turned on in VCF deployments. This helps accelerate NFC SOV adoption.
Extending Hot-Add Virtual Devices Capabilities with Enhanced VM DirectPath I/O
Non-stunnable devices support Storage vMotion (not compute vMotion) and hot-add of virtual devices such as vCPU, Memory and NICs. Examples of non-stunnable devices include Intel DLB (Dynamic Load Balancer) and AMD’s MI200 GPU
Guest OS and Workloads
Virtual Machine Hardware Version 22
Increased vCPU (960) limit for a virtual machine. Support for the latest CPU models from AMD and Intel. New Guest OS versions for new VM deployments. (see Guest OS Support in VCF 9.0).
Virtual Trusted Platform Module (vTPM) supports Trusted Platform Module (TPM) Library Specification Family 2.0 Revision 1.59. ESX 9.0 supports TPM 2.0 specification Revision 1.59, aimed to enhance your cyber security protection as you add a vTPM device to a virtual machine with hardware version 22.
New Guest Customization vAPIs. The newly introduced CustomizationLive API interface allows users to apply a customization specification to a VM while it is in a powered-on state. Refer to the latest vSphere Automation API documentation for VCF 9.0. The newly introduced Guest Customization API allows users to determine whether a VM can be customized before applying customization.
vSphere 9 introduces Namespace Write Protection (a read-only disk) and Write Zeroes support for virtual NVMe. Namespace Write Protection allows users to hot-add independent non-persistent disks to a VM without incurring the overhead of delta-disk creation. Workloads needing faster application delivery would benefit from this capability. Write Zeros support provides better performance, improves storage efficiency, and enhances data management capabilities for various workloads.
Virtual Machine Security, Compliance, and Operational Resilience
One thing we’ve been asked about over the past couple years is the ability to use custom VM secure boot certificates. VMs work fine out of the proverbial box with commercial operating systems, but some organizations want to build their own Linux kernels, and have their own PKI infrastructure to sign them. We now have a straightforward way to support that.
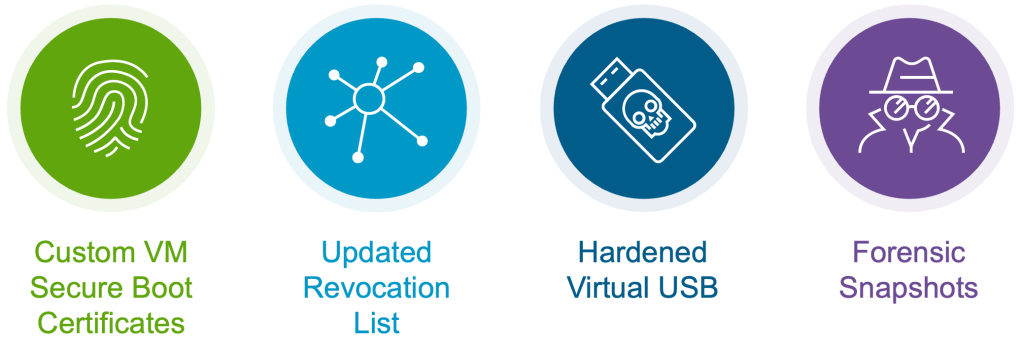
We’ve updated the default Secure Boot certificate revocation list, which means that if you try to install Windows on a newer virtual hardware version VM you’ll need recent Microsoft install media. Not that big of a deal, but something to keep in mind when you wonder why it’s not booting.
Virtual USB is great, but we’ve made a bunch of improvements, based on findings from security researchers. Another huge argument for keeping things up to date, both with VMware Tools drivers and virtual hardware versions.
Last on this list, forensic snapshots. We always want to guarantee that a snapshot of a VM can run the VM again, make it crash-consistent, which just means that it looks like the workload lost power. All OSes, databases, most apps know what to do in that situation. However, digital forensics and incident response teams really don’t need to run the VM again, they just want a snapshot that they can put in their analysis tools.
Custom EVC Brings Better Compatibility Between CPU Revisions
Easily define a custom EVC baseline to create a set of CPU and graphics features common to all hosts selected. More flexible and dynamic than predetermined EVC baselines.
Custom EVC lets the you create a custom EVC mode by specifying a set of hosts and/or clusters. vCenter creates a custom EVC mode that is based on the maximal set of features common to all specified hosts. The custom EVC mode can be applied to clusters or VMs. Custom EVC requires vCenter 9.0 and supports clusters containing ESX 9.0 or ESX 8.0 hosts.
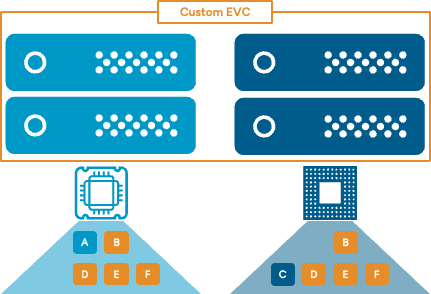
Better utilization of CPU features across variations of CPU SKUs. Example: Take two CPUs of the same generation but are related variants. CPU-1 contains FEATURES A, B, D, E, F. CPU-2 contains FEATURES B, C, D, E, F.
- CPU-1 has FEATURE-A, but CPU-2 does not.
- CPU-2 has FEATURE-B, but CPU-1 does not.
- Custom EVC allows maximal common features.
Flexible Application Licensing Compliance
A new compute policy named “Limit VM placement span plus one host for maintenance” is introduced in vSphere 9. This compute policy removes the complexities associated with license utilization and compliance requirements by enabling Administrators to create tag-based policies which enforce a strict limit on the number of ESXi Hosts allowed to run a group of VMs running a particular license-restricted application in a vSphere cluster. Administrators no longer need to pin VMs to Hosts, or create a pool of dedicated Clusters/Hosts on which to run such VMs.
An Administrator now simply needs to:
- Know how much licenses they have procured
- Know how many Hosts those licenses can be applied to
- Create a policy specifying that number of Hosts (no need to select particular Hosts)
- Apply the policy to the VMs running those applications
vSphere will ensure that any VM which has that tag can run only on one of the Hosts vSphere has included in that Limit. Host span is always N+1 for maintenance capacity. Host span is dynamic and not fixed to specific hosts
For what’s new in core storage see, vSphere and VMware Cloud Foundation 9.0 Core Storage – What’s New
For Introducing a Unified VCF SDK 9.0 for Python and Java see, https://blogs.vmware.com/cloud-foundation/2025/06/24/introducing-a-unified-vcf-sdk-9-0-for-python-and-java/
For the full vSphere with VCF 9.0 release notes see, https://techdocs.broadcom.com/us/en/vmware-cis/vcf/vcf-9-0-and-later/9-0/release-notes/vmware-cloud-foundation-90-release-notes/platform-whats-new/whats-new-vsphere.html
For the list of deprecated and removed features in vSphere with VCF 9.0 see, https://techdocs.broadcom.com/us/en/vmware-cis/vcf/vcf-9-0-and-later/9-0/release-notes/vmware-cloud-foundation-90-release-notes/platform-product-support-notes/product-support-notes-vsphere.html
For the list of known issues in vSphere with VCF 9.0 see, https://techdocs.broadcom.com/us/en/vmware-cis/vcf/vcf-9-0-and-later/9-0/release-notes/vmware-cloud-foundation-90-release-notes/component-specific/vsphere-90-known-issues.html
Discover more from VMware Cloud Foundation (VCF) Blog
Subscribe to get the latest posts sent to your email.



