

One of the features that transformed how virtualization is used is vSphere vMotion. During a vMotion task, one or more VMs are migrated to a different host while still powered on and available to users. The application running in the VM is unaware of this process. The VM goes through a very brief pause, also known as “stun time” in a vMotion. This stun time is necessary to copy the remaining active/hot memory pages and device state for the VM to the destination host. With VMs with assigned GPUs, we need to consider both the VM memory as well as the memory on the GPUs themselves in the copy process, and naturally this stun time would increase as there are now several locations where active memory lives.
In earlier pre 9.0 versions of vSphere, users were conscious of the amount of GPU memory associated with their VMs if they wanted to do a vMotion from one host to another. As one example, in normal IT Operations processes, an automatic vMotion is required to evacuate your VMs from a host, when the host is placed into maintenance mode. The reason for the caution about vMotion with vGPUs was that the GPU’s framebuffer memory contents (either in part or in full) must be copied from the source host to the destination host before the vMotion can succeed. If that memory copy cannot be done within a set time, then the vMotion would time out and no change of host would be done. With GPU devices now commonly used that have 80GB to 140GB or higher framebuffer memory, that data copying could take considerable time. In fact, a timeout of 100 seconds on the vMotion stun time is applied by default in vSphere – though this can be extended using DRS Advanced Settings.
With VCF 9.0, significant engineering work has been done on the vMotion internals to optimize how the memory copy works. We can now confidently use vMotion on 48GB, 80GB or much higher memory vGPU profiles and use vMotion with those VMs. As you will see, this is done well within the 100 second stun time timeout. In fact, for the 640GB collective memory on an eight-way GPU setup (8x80GB), the stun time for vMotion is down to 21 seconds, as we will see later in this article.
How Memory Copying for vGPUs is Done
In vSphere 8.0 U3 and earlier versions, the VM memory and GPU framebuffer memory that are assigned to the VM and actively being used in a GPU workload were copied during the vMotion Stun Time. During that stun time, the activity in the VM is stopped. This meant that for certain configurations the stun time could exceed 100 seconds and the resulting vMotion action would exceed the time out value.
Using Intel processors Sapphire Rapids and later and AMD at Milan and later, the vMotion copying logic can now use the IOMMU D-bits (Intel VT-d) or the AMD equivalent, (AMD-Vi) to inform it on which memory pages are being actively used (i.e. dirty pages) and which are not. The IO Memory Management Unit (IOMMU) is used to map the pages of GPU memory to main memory. IOMMU D bit tracking is fast and can accurately track the VM main memory dirtied by passthrough devices such as vGPU during vMotion. This capability is effective for all types of workloads such as graphics, AI Inferencing and model training. On the server, the Intel VT-d or AMD-Vi functions should be enabled in the BIOS/UEFI.
For large language models executing for inference on a model runtime, such as vLLM, the majority of the data is not changing (i.e. 70% of the overall data is “cold”). That cold data can be copied in vMotion before the VM is stunned. Only the remaining 30% of overall data that is being altered needs to be copied during the stun time.
In vMotion, the “pre-copy” stage precedes the stun time stage. During the pre-copy stage of vMotion, there is still application activity in the VM, whereas at stun time, that is not the case. When a large language model is executing on the GPU, up to 70% of that model’s data is static. This data represents the parameters or weights of the model. The remaining 30% of the model’s data is composed of the key-value or KV cache and the activations area, where a lot of data is changing continuously.
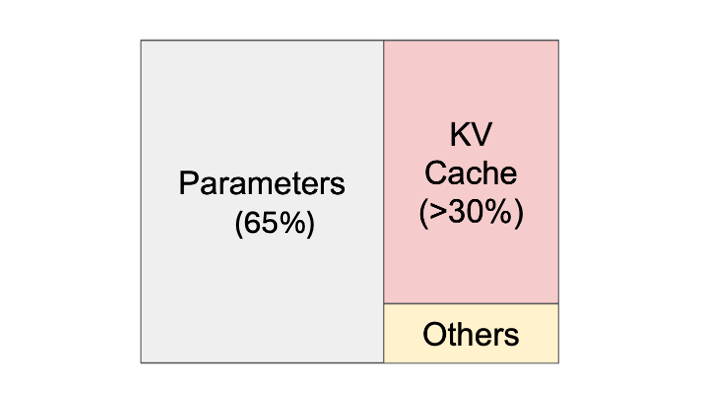
The approach used here is that the vMotion logic is informed about which data is static and that data is copied during the pre-copy phase. This pre-copy phase does not interrupt the progress of the application or model in the VM. The dynamically changing data, on the other hand, is copied during the stun time phase, shown using the title “vGPU Ckpt” or checkpoint below.

There are separate techniques for optimizing the data copying activity in vMotion that involve using the data channel and control channel networks that are used for copying the data. For example, the control channel was single-threaded in earlier versions of vSphere and was used for copying the vGPU checkpoint (i.e. dynamic memory). The data channel is multi-threaded and is used in VCF 9.0 to copy the vGPU checkpoint. Similarly, multiple copies of data buffers were used internally in previous versions of vSphere to 9.0 – and that too has been optimized in 9.0.
VCF 9.0 vMotion Stun Time Improvements
A series of tests was executed by the Broadcom engineers to show the improvements to vMotion stun times. The tests used the Meta Llama 3.1 models of varying sizes with different configurations of L40S and H100 GPUs associated with a VM on the VCF 9.0 platform. The results from this testing show the significant improvements in VCF 9.0 vMotion stun time over the earlier version, where the vSphere 8.0 U3 vMotion times are used as the baseline. These tests were done with varying sizes of Llama 3.1 models and different vGPU profiles assigned to the test VM, shown in the second column.
The models executing in the VM used different amounts of GPU framebuffer memory, as seen in the “vGPU Memory Consumed” column below. The host servers used for this testing had NICs dedicated to vMotion traffic that are capable of 100 Gigabit per second data transfer, but that bandwidth was not saturated and peaked at 69 Gbps during the tests. The key measures to take note of in the table are the comparisons of vMotion Stun time between 8.0 U3 and VCF 9.0. The VCF 9.0 vMotion column shows that stun time now can take three-four times less time than the earlier version. This means that the application and the model runtime are stopped for far less time during a vMotion.
In fact, for a VM configuration with eight H100 GPUs assigned to it, the stun time timeout caused the vMotion to time-out on 8.0 U3 (that is, with none of the advanced settings for stun time applied). Whereas the stun time on VCF 9.0 falls well within the default timeout value of 100 seconds and stun completes in 21 seconds.
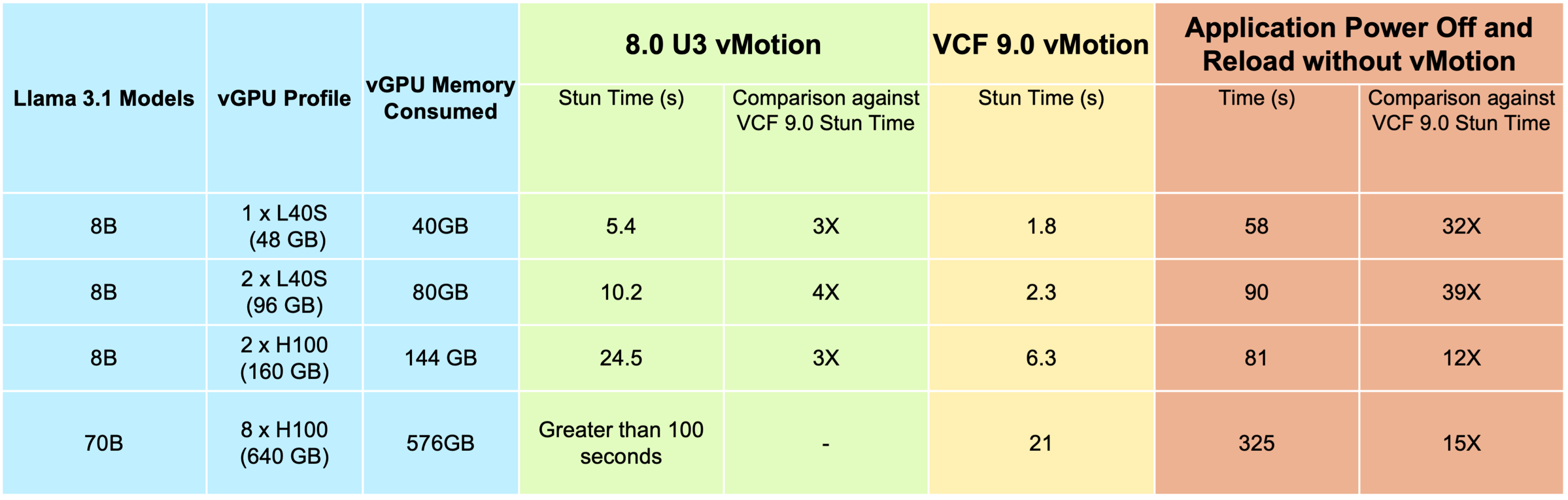
The example of the two H100 GPU test vGPU profile was a “device group” with the “nvidia_h100xm-80c” profile. The host vGPU driver set used in this testing was version 570.95 (vGPU 18 with IOMMU D bit support). The vGPU guest driver was 550.127.06.
Hot-Add of vCPUs, Storage vMotion, Live Patching
During the reconfiguration of a VM to add a new vCPU or other devices, or during live patching of the software within the VM, there is a “suspend” phase of that VM that is similar to the stun time we saw in the vMotion description above. In effect, a vGPU device is handed off from the original VM to a destination VM on the same host during this process, where the destination VM has the newly added device present. Handing off that vGPU device to the destination VM means that a checkpoint of the GPU’s memory is done and that memory is copied from the original VM to the destination VM. This activity is called “Fast Suspend/Resume” (FSR) in VCF. Since both source and destination VM are on the same host, memory copying is much reduced and therefore FSR stun time is reduced significantly. The hot-add of vCPUs, storage vMotion and live patching are commonly used by VCF systems administrators to add more processing power to their VMs.

Zero Downtime Maintenance
With the improvements to the internal working of vMotion stun time for vGPU-aware VMs and a suitable networking setup, users can now confidently migrate their running LLM applications and models running in VMs with vGPU profiles from one host to another within the datacenter both for load balancing and maintenance processes. The hot-add of new vCPUs, storage vMotion and VM live patching also benefit from these improvements.
***
Ready to get hands-on with VMware Cloud Foundation 9.0? Dive into the newest features in a live environment with Hands-on Labs that cover platform fundamentals, automation workflows, operational best practices, and the latest vSphere functionality for VCF 9.0.
Discover more from VMware Cloud Foundation (VCF) Blog
Subscribe to get the latest posts sent to your email.




