

When we assign a full GPU or part of a GPU to a VM in the VMware vSphere Client, we use a “vGPU Profile” to achieve that. The set of vGPU profiles is fixed by the host vGPU driver based on the GPU hardware models in the servers in that cluster. An example of this set is shown in the screen below, where the number before the end of the vGPU profile name gives the GB of framebuffer memory on the GPU to be assigned to the VM.
Many different vGPU profiles can be active across a cluster today and viewing the full picture of their usage can be hard. The new VCF 9.0 feature described here, DirectPath Profiles, enables a more detailed visualization of GPU/vGPU consumption and planning for future use of the remaining GPU capacity. The functionality described here is a general one and can be applied to any DirectPath I/O device. The virtual GPU (vGPU) technology from NVIDIA for using GPUs is our focus in this article. There is also vGPU metric visibility in VCF Operations 9.0 that is described in other articles.
The set of vGPU profiles that is allowed for a particular GPU model, such as an H100, is presented to the vSphere Client user who is configuring the VM. Here is an example of what that choice looks like. The full set of vGPU profiles that can apply for the H100 is not shown here. This example shows a MIG-backed vGPU profile on the first line and a set of Time-Slice backed vGPU profiles in the following lines. This means that at least two GPUs are active on this cluster or on this host. MIG is explicitly turned on, on an individual GPU basis, using the nvidia-smi command. If MIG is not enabled, the default mode for a GPU is time-sliced. This default behavior may change in future releases of the NVIDIA vGPU drivers.
We can assign more than one vGPU profile to one VM. One example of this is assigning multiple full GPUs (using full vGPU profiles) to the VM – most often used for handling large language models (LLMs) that do not fir into the memory of one GPU.
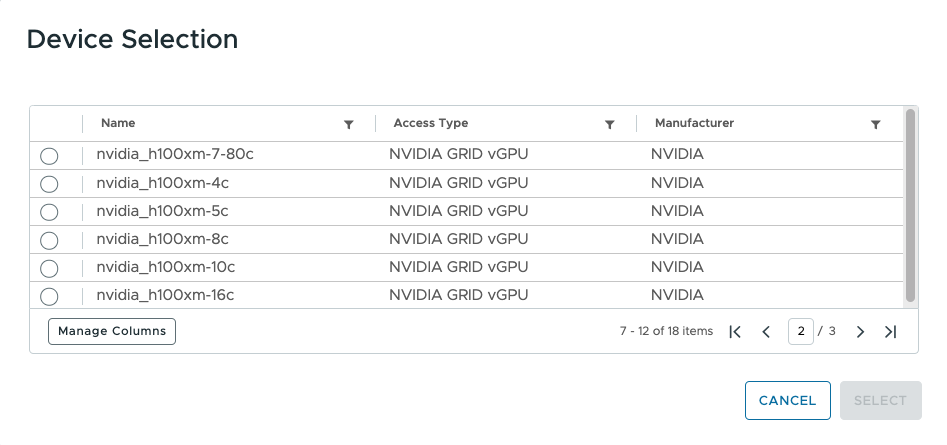
Multiple VMs that run on the same host server can also share one physical GPU. We do this by using specific vGPU profiles that represent parts of one physical GPU device, called “fractional vGPU profiles”. An example of a fractional vGPU profile is “nvidia_h100xm-20c”, as seen first in the list here. This time-sliced vGPU profile uses 20GB or part of the total framebuffer memory on an H100 GPU. One can assign multiple fractional vGPU profiles also to a VM.
Multiple VMs can consume one or more vGPU profiles, so in the past, it has been challenging for the vSphere Client user to keep track of the consumption of the physical GPU by vGPU profiles and to see what capacity is left to be consumed. Imagine a situation of twenty or more hosts in a cluster, with each host providing a limited per-host overview of its GPU consumption.
In VCF 9.0, the vSphere Client solves this capacity estimation issue by giving the administrator better views of the consumption of DirectPath Profiles (DPPs) and the vGPU profiles that are contained within them. You can think of a DPP as a wrapper around a vGPU profile – more detail on DPPs is given later in this article. You can see the consumption of a set of DPPs in the vSphere Client at the cluster level under a new area called “vGPU Profile Utilization” seen below. We can use this view arranged by virtual machine or by DirectPath Profile, as seen in the tabs.
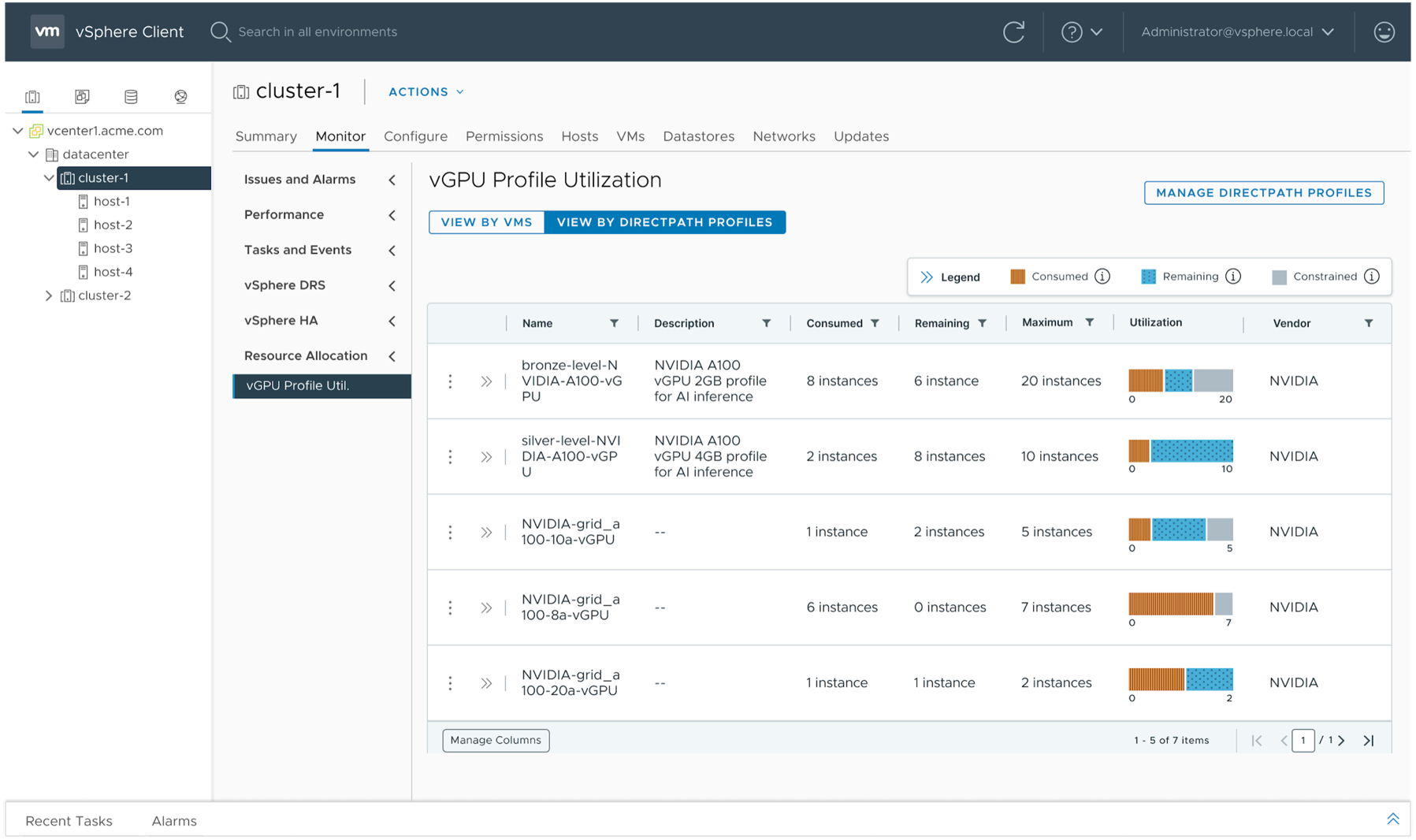
What we are looking at is a comprehensive set of GPU/vGPU consumption details for a cluster in the vSphere Client. Looking at the different columns in the output, we now see:
- The DPP names, descriptions and their associated vGPU profiles that are allocated to VMs currently running across a cluster of hosts. This is shown as “Consumed” capacity against each DPP name. The “Description” field tells us which vGPU profile is contained in that DPP.
- The “Remaining” DPPs (and their associated vGPU profiles) that could be used in further VMs that are not currently running.
- The “Maximum” column indicates the total capacity for a particular DPP in a target cluster if the cluster had no DPPs assigned.
The maximum value means that if there were no VM running in the target host/cluster, then this number of instances of that DPP could be used. What is measured here is the maximum capacity consumable for user workloads, leaving any system requirements to one side.
This new DPP feature in VCF 9.0 gives the administrator the power to see what their used and unused capacity is, in vGPU terms. This is a key benefit for capacity planning or for summarized usage visibility by the system administrator.
We notice that the sum of Consumed and Remaining does not equal the Maximum in the first line above. This is caused by certain constraints that the vGPU profile has, when sharing the same GPU with other VMs and other vGPU profiles. The rules and combinations for the placement of vGPU profiles onto the physical GPU can be complex – and these are laid down by the device vendor. More detailed information on this can be found for vGPU profiles in the NVIDIA AI Enterprise User Guide
Background on DirectPath Profiles
GPU devices that are used through their vGPU profiles are referred to as DirectPath devices because VMs consume these devices via DirectPath I/O (also known as Passthrough). You can think of the vGPU method of addressing a GPU as one technique in a spectrum of options that are forms of DirectPath I/O.
The concept of a “DirectPath Profile” is a new one in VMware Cloud Foundation 9.0. The DPP concept provides a device-independent way of expressing the requirements the user wants to see when using a GPU or another accelerator. For NVIDIA vGPU deployments, we can think of a DPP as a wrapper around a vGPU profile, where the vGPU profile normally has a specific model built into the name, such as “nvidia-a100_3_20c”, but the DPP does not.
DPPs are discovered automatically for any powered-on VM that is operating with a vGPU profile and the generated DPP name is presented by the vSphere Client.
The user may also create their own DPPs to express what they would like to use, as far as GPU resource capability is concerned. Our recommendation is to explicitly identify the vGPU profile being used in the description field when creating a new DPP of your own. DPPs allow you to have a curated list of vGPU profiles that are capable of running your organization’s workload, in advance of deploying the workload. This is one of the significant benefit of using DPPs.
There are two general situations that DPPs can apply to:
- DirectPath device configurations that are in use by powered-on VMs. VCF automatically discovers every DirectPath device configuration that is in use by powered-on VMs and exposes its capacity consumption metrics.
For example, VMs in a vSphere cluster that are consuming Nvidia H100 80 GB SXM5 GPU by using the vGPU profile named nvidia_h100xm-16c. In this description, “nvidia_h100xm-16c” is the device configuration in use.
VCF automatically gives this VM a DPP that has a device-independent name.
- DirectPath device configurations that are not in use by any powered-on VM but are still of interest to the administrator from a capacity perspective.
In the example seen below, there is currently no VM that consumes the vGPU profile “nvidia-a100-40c” . However, since the administrator is interested in the potential for this vGPU profile, they create a DirectPathProfile that uses it. The DPP in this case is named “a100-40c”, the last item in the list shown. This vGPU profile is not viable, since the 4 instances shown under the Maximum column are labeled “Resources prohibited” in the grey area. Why is that so?
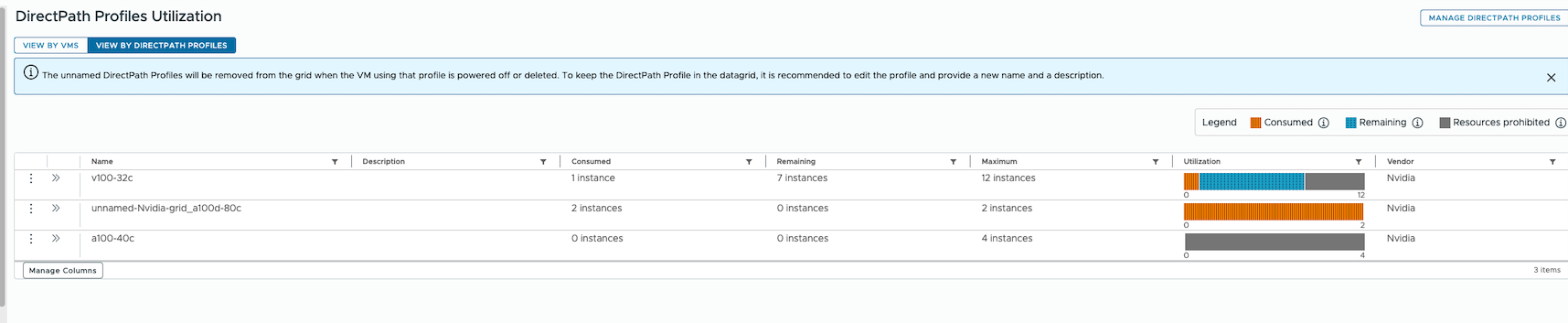
We see exactly why this is so in a screen that examines the cluster-level use of the DirectPath Profiles below.
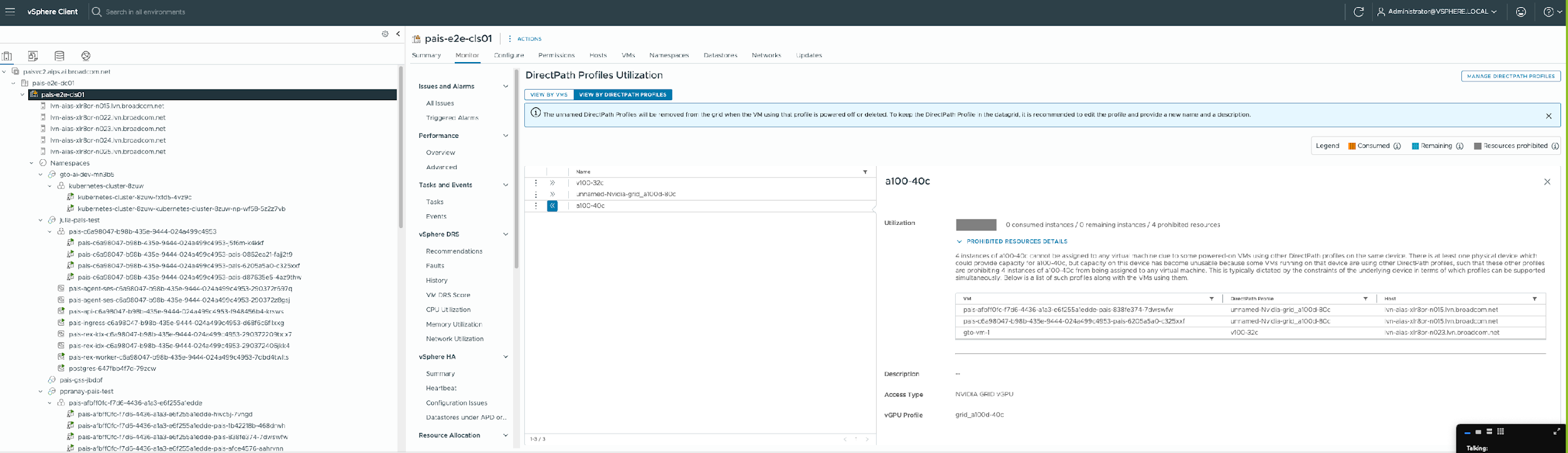
The reason that the “nvidia-a100-40c” profile is not usable, or prohibited, is that the two A100 GPUs are fully occupied on that host server – and this host is the only A100-capable host in our cluster. This is shown in the table on the right-hand pane above. This is one example of the use of DirectPath Profiles for capacity estimation.
The DPP configurations under point 1 above can be discovered by vSphere for the GPUs already in use by the powered-on VMs. The second set of DPPs, those that are not used by any running VM, must be explicitly created by the system administrator. They would do this if they were trying to assess the total capacity that is available for future use, by means of vGPU profiles. Creation of a custom DPP is a simple process, using a vGPU profile, in a new area in the vSphere Client, under Policies and Profiles in the left navigation.
In creating a DPP, we simply select the vGPU profile or Device Group that we want to use within it, as seen here.
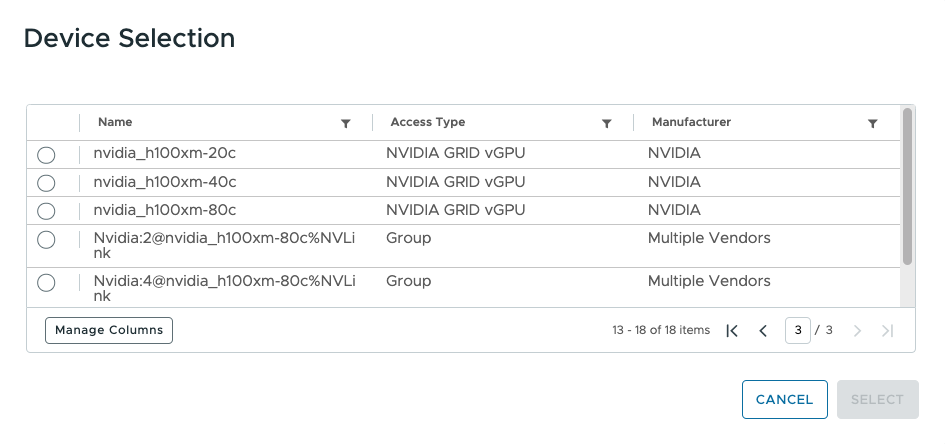
Customers have mentioned to us that they currently keep notes of which vGPU profile configurations are of interest for a given cluster and then manually compute the capacities for those profiles using the nvidia–smi utility at the ESXi host level. As the number of vGPU profiles used in a cluster increases, this method becomes unwieldy. with VCF 9.0, the user can select the vGPU profile they are most interested in and build a DPP around that – saving them all the manual searching they did up to now.
With DPPs, as seen in figure 1 above, the entire capacity estimation exercise becomes a lot easier. We can also carry out “what-if” experiments with DPPs that have no physical deployment yet, so as to see what the effect of using that DPP would be in the GPU consumption. DPPs will also be a key element of reservations of GPUs that is described in other articles.
Summary
With VCF 9.0, we now have a method to create a new DirectPath Profile (DPP), assign it a user-friendly name and then use that DPP to get the consumed and remaining vGPU profile capacity. We can see the available GPU space and perform capacity planning with more detailed data, rather than searching our cluster for available space.
Using a DPP also paves the way for enabling more workflows for DirectPath devices (such as reserving resources or configuring a quota).
Discover more from VMware Cloud Foundation (VCF) Blog
Subscribe to get the latest posts sent to your email.




