


What if Obelix of the Asterix & Obelix fame had to throw ‘512-byte size’ menhirs at the Romans? That would take him a long time , yes, even with the magic portion , to get all the Romans. hmmm..
‘4k size’ giant menhir ? Yes, that’s effective.
Business Critical Oracle databases would benefit from using 4k redo blocksize to drive IO intensive workloads as opposed to using 512byte redo blocksize for all the obvious reasons , yes , it comes at the cost of redo wastage but there are pros and cons to every thing.
This blog addresses the advantages of using Oracle Redo Log with 4k blocksize (default is 512 bytes with blocksize choices 512bytes, 1k and 4k) on VMware platforms and current challenges associated with that with roadmap guidance.
Oracle Redo Log blocksize – Implications and Tradeoffs
The advent of the new Advanced Format drives came with larger capacity and increased sector size (i.e., the minimum-possible I/O size) of these drives from a value of 512 bytes to the more efficient value of 4096 bytes (or 4KB).
By default, database online redo log files have a block size of 512 bytes. From Oracle Database version 11.2 this can be changed with the BLOCKSIZE clause to values of 512, 1024 or 4096.
Linux OS requires kernel version 2.6.32 or later for 4K device support.
I/O requests sent to the redo log files are in increments of the redo block size. This is the blocking factor Oracle uses within redo log files and with the default redo log block set to 512bytes, more redo blocks would have to be written for any given workload as opposed to the same workload using a larger redo log blocksize.
However, with a block size of 4K, there is increased redo wastage. In fact, the amount of redo wastage in 4K blocks versus 512B blocks is significant.
To avoid the additional redo wastage, if you are using emulation-mode disks—4K sector size disk drives that emulate a 512B sector size at the disk interface—you can override the default 4K block size for redo logs by specifying a 512B block size or, for some platforms, a 1K block size. However, you will incur a significant performance degradation when a redo log write is not aligned with the beginning of the 4K physical sector. Because seven out of eight 512B slots in a 4K physical sector are not aligned, performance degradation typically does occur.
Thus, you must evaluate the trade-off between performance and disk wastage when planning the redo log block size on 4K sector size emulation-mode disks.
More information on Oracle Redo Log file with 4k blocksize can be found here.
Oracle Redo Log with 4k blocksize
Beginning with Oracle Database version 11.2, redo log blocksize can be changed with the BLOCKSIZE clause to values of 512, 1024 or 4096. For example:
SQL> ALTER DATABASE ADD LOGFILE GROUP 5 SIZE 100M BLOCKSIZE 4096;
For a 512e emulation device, the logical sector size is 512 bytes, and the physical sector size is 4096 bytes (4K). Hence, the above command will fail unless the sector size check is overridden by setting the underscore parameter _disk_sector_size_override to true in the database instance (do not set this parameter in the ASM instance) using the following command:
ALTER SYSTEM SET “_DISK_SECTOR_SIZE_OVERRIDE”=”TRUE”;
At this point, online redo logs can be created with the desired 4k block size.
VMware vSphere and vSAN support for 512e and 4K Native (4Kn) drives
vSphere/vSAN 6.0 and earlier versions have not been designed to use 4Kn/512e direct attached disk drives. 512e drives are supported only in version 6.5, 6.7, 7.x and later.
vSphere 6.7 released 4kn local storage support. vSphere 6.5/6.7/7.x and vSAN 6.5/6.7/7.x and later support 512e drives as direct attached drives.
Currently, vSphere and vSAN will expose 512n (both logical and physical sector sizes are 512 bytes) to the guest OS as part of this support as per KB 2091600.
Oracle Redo Log 4k blocksize on VMware vSphere / vSAN
As stated above, currently, vSphere and vSAN will expose 512n (both logical and physical sector sizes are 512 bytes) to the guest OS as part of this support.
VMware Engineering is aware of this and end to end 4k sector support is scheduled on the roadmap, stay tuned.
Oracle Redo Log 4k blocksize on Physical Mode RDMs mapped to direct attached 512e drives.
VMware recommends using VMDK (s) for provisioning storage for ALL Oracle environments. In some cases, RDM (Physical / Virtual) can also be used as VM storage for Oracle databases.
Given the current restriction of using redo logs with 4k blocksize on vmdk’s , we ran our tests using 512e RDM’s to showcase the performance benefit of using redo logs with 4k blocksize compared to 512 byte blocksize.
Test Bed
VM ‘Oracle1912-OEL83-Customer’ was created with 20 vCPU’s , 256GB memory with storage on All-Flash Pure array with Oracle SGA & PGA set to 96G and 20G respectively.
A single instance database ‘ORA19C’ with multi-tenant option was provisioned with Oracle Grid Infrastructure (ASM) and Database version 19.12 on O/S OEL 8.3. Oracle ASM was the storage platform with Linux udev for device persistence. ASMLIB and ASMFD also be used instead.
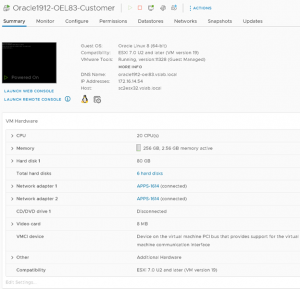
The vmdk’s for the VM ‘Oracle1912-OEL83-Customer’ are on a Pure Storage FC datastore.
The VM ‘Oracle1912-OEL83’ has 3 vmdk’s-
- Hard Disk 1 (SCSI 0:0) – 80G for OS (/)
- Hard Disk 2 (SCSI 0:1) – 80G for Oracle Grid Infrastructure and RDBMS binaries
- Hard Disk 3 (SCSI 1:0) – 500G for Oracle Database
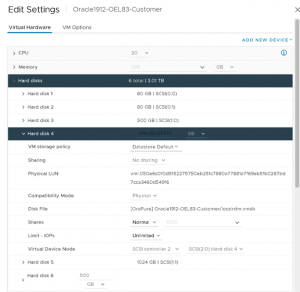
- Hard Disk 4 (SCSI 2:0) – 895G NVMe drive as RDM
- Hard Disk 5 (SCSI 1:1) – 1TB SLOB Tablespace
- Hard Disk 6 (SCSI 3:0) – 500G for 512n Testing (Not used)
Details of Hard Disk 4 (SCSI 2:0) – 895G Local NVMe drive as RDM are shown as below
Test Case
SLOB 2.5.4.0 was chosen as the load generator for this exercise with following SLOB parameters set as below:
- UPDATE_PCT=100
- SCALE=512G
- WORK_UNIT=3
- REDO_STRESS=HEAVY
We deliberately chose the minimum Work Unit size to drive the most amount of IO with heavy stress on redo to study the performance metrics differences between using 512bytes and 4k redo block sizes.
Test Results
Remember, any performance data is a result of the combination of hardware configuration, software configuration, test methodology, test tool, and workload profile used in the testing , so the performance improvement I got with my workload in my lab is in no way representative of any real production workload which means the performance improvements for real world workloads will be better.
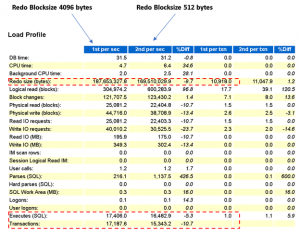
The first test (4k workload) was conducted with redo block size of 4k and second test (512b workload) with redo block size of 512Bytes. The ASM disk group housing the redo logs has their sector size set accordingly.
We can see , by using redo logs with 4k blocksize as compared to 512bytes
- Redo size (bytes) have reduced from 187,653,327.8 to 169,510,029.9
- Executes(SQL) / Transactions have increased by 5.3% / 10.7% respectively
From a wait event perspective :-
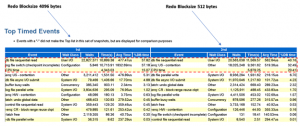

Wait event ‘log file switch (checkpoint incomplete)’ is actually a DBWR related events which is usually indicative of a heavy workload which is a good problem to solve , you want to be able to push as much IO to the database as possible.
From a redo log performance perspective:
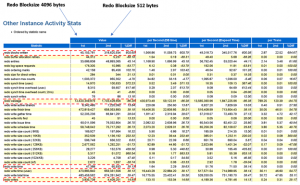

Digging further, for 4k blocksize, the ‘redo writes lower than 4k is 0 as 4k is the blocksize
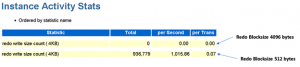
From a physical read/write perspective :


From an OS perspective:
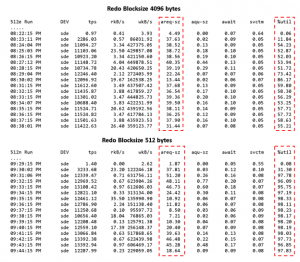
- 4k workload disk utilization lower than 512b workload
- 4k workload ‘average request IO size’ more consistent than 512b workload
Summary
In summary , comparing the redo log 4k blocksize v/s 512b blocksize , we can see
- Redo size (bytes) have reduced from 187,653,327.8 for 4k workload to 169,510,029.9 for 512b workload
- Executes(SQL) / Transactions have increased by 5.3% / 10.7% respectively for 4k workload
- Wait event ‘log file switch (checkpoint incomplete)’ increase indicates that the log writer is waiting for the DBWR to flush faster which is better than waiting for log writer events
- More redo blocks generated for 512b blocksize, redo wastage with 4k redo block as expected, less time to write redo with large 4k blocksize and More redo to write with small 512b blocksize
- Reduction in read and write IOPS with 512b redo blocksize
- From an OS perspective, 4k workload disk utilization is lower than 512b workload and 4k workload ‘average request IO size’ more consistent than 512b workload
Thus, you must evaluate the trade-off between performance and disk wastage when planning the redo log block size on 4K sector size emulation-mode disks.
Conclusion
- This blog is meant to raise awareness of the advantages of using 4k redo block size v/s 512b with pros and cons
- This blog contains results that I got in my lab running a load generator SLOB against my workload, which will be way different than any real-world customer workload, your mileage may vary. Remember, any performance data is a result of the combination of hardware configuration, software configuration, test methodology, test tool, and workload profile used in the testing
All Oracle on vSphere white papers including Oracle licensing on vSphere/vSAN, Oracle best practices, RAC deployment guides, workload characterization guide can be found in the url below
Oracle on VMware Collateral – One Stop Shop
https://blogs.vmware.com/apps/2017/01/oracle-vmware-collateral-one-stop-shop.html
Discover more from VMware Cloud Foundation (VCF) Blog
Subscribe to get the latest posts sent to your email.





