
Virtualizing AI/ML workloads requires only a fraction of the bare-metal resources. This leaves the remaining resources for other workloads while maintaining uncompromising performance and lowering the total cost of ownership at the same time.
Introduction
Generative AI (Gen AI) is rapidly transforming how we create, communicate, and solve problems across industries. Gen AI tools are pushing the boundaries of what’s possible with machine intelligence. As organizations deploy Gen AI models for tasks like text generation, image synthesis, and data analysis; performance, scalability, and resource utilization become critical factors. Choosing the right infrastructure—whether virtualized or bare metal—can significantly impact how effectively these AI workloads run at scale. This blog dives into a performance comparison between virtualized and bare-metal environments for Gen AI workloads.
Broadcom brings the power of virtualized NVIDIA GPUs to the VCF private cloud platform to simplify management of AI-accelerated data centers and enable efficient application development and execution for demanding AI and ML workloads. Broadcom’s VMware software supports various hardware vendors, allowing flexibility and choice while facilitating scalable deployments.
Broadcom and NVIDIA have collaborated to develop a joint Gen AI platform: VMware Private AI Foundation with NVIDIA. This Gen AI platform allows data scientists and others to fine-tune LLM models, deploy RAG workflows, and run inference workloads in their data centers while addressing privacy, choice, cost, performance, and compliance concerns. Built and run on the industry-leading private cloud platform, VMware Cloud Foundation, VMware Private AI Foundation with NVIDIA includes the NVIDIA AI Enterprise, NVIDIA NIM (included with NVIDIA AI Enterprise), NVIDIA LLMs, and other components that provide access to community models (such as Hugging Face models). VMware Cloud Foundation (VCF), VMware’s full-stack private cloud infrastructure solution, offers a secure, comprehensive, and scalable platform for building and operating Gen AI workloads, providing organizations with agility, flexibility, and scalability to meet their evolving business needs.
Summary
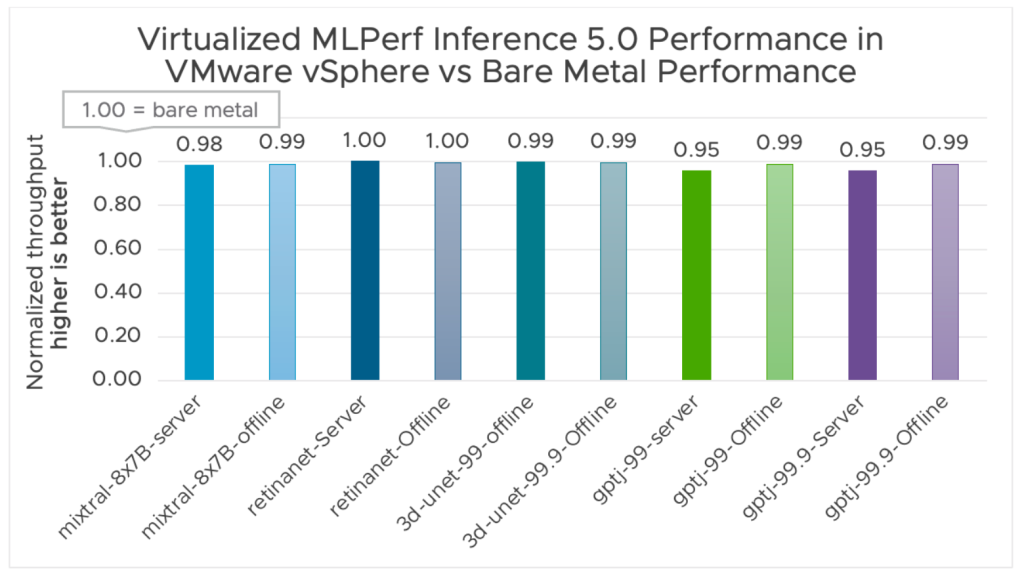
Broadcom partnered with NVIDIA, Supermicro, and Dell to showcase virtualization’s benefits (for example, intelligent pooling and sharing AI infrastructure), achieving impressive MLPerf Inference v5.0 results. We demonstrated near bare-metal performance across diverse AI domains—computer vision, medical imaging, and natural language processing—using a 6-billion parameter GPT-J language model. We also achieved outstanding results with the Mixtral-8x7B 56-billion parameter large language model (LLM). Figure 1 shows normalized virtual performance to be near that of bare metal, ranging from 95%–100% on VMware vSphere 8.0 U3 with NVIDIA virtualized GPUs. Virtualization lowers the total cost of ownership (TCO) of an AI/ML infrastructure by allowing you to share expensive hardware resources among multiple tenants with practically no impact on performance. Refer to the official MLCommons Inference 5.0 results for the raw comparison of queries per second or tokens per second.
Virtualized performance is near that of bare metal, ranging from 95%–100% on VMware vSphere 8.0U3 with NVIDIA virtualized GPUs.
Hardware and Software
We ran MLPerf Inference v5.0 workloads virtualized with VMware vSphere 8.0 U3 on two systems:
- SuperMicro SuperServer SYS-821GE-TNRT with 8x virtualized NVIDIA SXM H100 80GB GPUs
- Dell PowerEdge XE9680 with 8x virtualized NVIDIA SXM H100 80GB GPUs
We only needed to allocate a fraction of the bare metal resources to the virtual machines used in our tests.
Tables 1 and 2 show the hardware configurations used to run the LLM workloads on the bare metal and virtualized systems. In all cases, the physical GPU, which is the primary driver of performance for these workloads, was the same in the virtual configuration as it was in the bare metal configuration to which it was being compared.
The benchmarks were optimized with NVIDIA TensorRT-LLM, which consists of the TensorRT deep learning compiler and includes optimized kernels, pre- and post-processing steps, and multi-GPU/multi-node communication primitives for maximum performance on virtualized NVIDIA GPUs.
| COMPONENT | BARE METAL | VIRTUAL |
|---|---|---|
| System | SuperMicro GPU A+ SuperServer 8125GS-TNHR | SuperMicro GPU SuperServer SYS-821GE-TNRT |
| CPU* | 2x AMD EPYC 9634 84-core processor | 2x Intel® Xeon® Platinum 8568Y+ |
| CPU cores | 168 | 48 (25%) vCPUs allocated to the VM for inferencing (144 available for other VMs/workloads) |
| GPU | 8x H100-SXM-80GB | 8x NVIDIA GRID H100-SXM-80c vGPU (full profile) |
| Accelerator interconnect | 18x 4th Gen NVLink, 900GB/s | 18x 4th Gen NVLink, 900GB/s |
| Memory* | 1.5TB | 2.5TB allocated for inferencing VM out of 3TB (83.3%) |
| Storage* | 7TB NVMe SSD | 4x 3.37TB NVMe SSD |
| OS | Ubuntu 24.04 | Ubuntu 24.04 VM in vSphere 8.0.3 Build#: 24501832 |
| NVIDIA AI Enterprise VIB for VMware ESXi | N/A | vGPU_17.4_GA_AIE_ESXi_Host_Drivers for vGPUs |
| CUDA | 12.8 | 12.8 CUDA and Linux vGPU Driver 550.90 |
| TensorRT | 10.8 | 10.8 |
| Special VM settings | N/A | pciPassthru[0-7].cfg.enable_uvm = "1" |
* CPU, memory, and storage do not have matching specifications due to hardware availability constraints.
| COMPONENT | BARE METAL | VIRTUAL |
|---|---|---|
| System | Dell PowerEdge XE9680 | Dell PowerEdge XE9680 |
| CPU | 2x Intel Xeon Platinum 8468 | 2x Intel Xeon Platinum 8468 |
| CPU cores | 96 | 64 vCPUs (67%) allocated to the VM for inferencing (32 available for other VMs/workloads) |
| GPU | 8x H100-SXM-80GB | 8x NVIDIA GRID H100-SXM-80c vGPU (full profile) |
| Memory | 2TB | 1TB allocated for inferencing VM out of 2TB (50%) (the other 1TB available for other VMs/workloads) |
| Storage | 4x 1.75TB NVMe SSD | 4x 1.75TB NVMe SSD |
| OS | Ubuntu 24.04 | Ubuntu 24.04 running in a vSphere 8.0 U3 VM |
| NVIDIA AI Enterprise VIB for VMware ESXi | N/A | VMware ESXi 8.0.3 2441450 |
| CUDA | 12.8 | 12.8 CUDA and Linux vGPU Driver 550.127.06 |
| TensorRT | 10.8 | 10.8 |
| Special VM settings | N/A | pciPassthru[0-7].cfg.enable_uvm = "1" |
Benchmarks
Each benchmark is defined by a dataset and quality target. The following table summarizes the benchmarks in this version of the suite (the rules remain the official source of truth).
| AREA | TASK | MODEL | DATASET | QSL SIZE | QUALITY | SERVER LATENCY CONTRAINT | LATEST VERSION AVAILABLE |
|---|---|---|---|---|---|---|---|
| Vision | Object detection | Retinanet | OpenImages (800×800) | 64 | 99% of FP32 (0.3755 mAP) | 100ms | v5.0 |
| Vision | Medical image segmentation | 3D UNET | KITS 2019 (602x512x512) | 16 | 99% of FP32 and 99.9% of FP32 (0.86330 mean DICE score) | N/A | v5.0 |
| Language | LLM summarization | GPT-J 6B | CNN-DailyMail News Text Summarization | 13368 | 99.9% or 99% of the original FP32 ROUGE 1 – 42.9865 ROUGE 2 – 20.1235 ROUGE L – 29.9881 | 20s | v5.0 |
| Language | LLM text generation (question answering, math and code generation) | Mixtral 8x7B | OpenOrca GSM8K, MBXP | 15000 | 99% or 99.9% of FP32 (ROUGE 1 – 45.4911, ROUGE 2 – 23.2829, ROUGE L 30.3615, (gsm8k)Accuracy 73.78, (mbxp)Accuracy 60.12) | TTFT: 2s & TPOT: 200ms | v5.0 |
Source: https://mlcommons.org/benchmarks/inference-datacenter/
In an Offline scenario, the workload generator (LoadGen) sends all queries to the system under test at the start of the run. In a Server scenario, LoadGen sends new queries to the system under test according to a Poisson distribution. This is shown in table 4.
| SCENARIO | QUERY GENERATION | DURATION | SAMPLES PER QUERY | LATENCY CONSTRAINT | TAIL LATENCY | PERFORMANCE METRIC |
|---|---|---|---|---|---|---|
| Server | LoadGen sends new queries to the SUT according to a Poisson distribution | 270,336 queries and 60s | 1 | Benchmark-specific | 99% | Maximum Poisson throughput parameter supported |
| Offline | LoadGen sends all queries to the SUT at start | 1 query and 60s | At least 24,576 | None | N/A | Measured throughput |
Performance comparison of virtualized vs bare-metal ML/AI workloads
Featuring a SuperMicro SuperServer SYS-821GE-TNRT and a Dell PowerEdge XE9680 vSphere host/bare metal server with 8 virtualized NVIDIA H100 GPUs
Figure 1 shows the performance results of test scenarios, which compares a bare metal configuration with vSphere on a SuperMicro GPU SuperServer SYS-821GE-TNRT and a Dell PowerEdge XE9680 with virtualized 8x H100 GPU device group linked via NVLinks. The bare metal baseline is set to 1.0, and the virtualized result is presented as a relative percentage of the baseline.
Compared to the bare metal results, vSphere with NVIDIA vGPUs delivers near bare metal performance, ranging from 95%–100% for the Offline and Server scenarios of the MLPerf Inference 5.0 benchmark.
Note that the Mixtral-8x7B performance numbers obtained on Dell PowerEdge XE9686 and all other benchmark numbers were obtained on SuperMicro GPU SuperServer SYS-821GE-TNRT.
Conclusion
The virtualized configurations use only 28.5%–67% of the CPU cores and 50%–83% of the available physical memory to deliver near bare-metal performance—that’s a key benefit of virtualization. This lets you use the remaining CPU and memory capacity on the same systems to run other workloads, save on ML/AI infrastructure costs, and leverage the virtualization benefits of vSphere for managing data centers. Beyond the GPU, virtualization also enables you to pool and share CPU, memory, network and data I/O, which leads to a dramatically lower total cost of ownership (as much as a 3x–5x improvement). The results of our benchmark testing show that vSphere 8.0.3 with NVIDIA virtualized GPUs is in the Goldilocks Zone for AI/ML workloads. vSphere also makes it easy to manage and process workloads quickly using NVIDIA vGPUs, flexible NVLinks to connect devices, and vSphere virtualization technologies to use AI/ML infrastructure for graphics, training, and inference. Virtualization lowers the total cost of ownership (TCO) of an AI/ML infrastructure by allowing you to share expensive hardware resources among multiple tenants with practically no impact on performance.
Want to learn more about VMware Private AI Foundation with NVIDIA?
- Check out the VMware Private AI Foundation with NVIDIA webpage for more resources.
- Contact us using this Interest Request form.
Acknowledgments: We would especially like to thank Jia Dai (NVIDIA), Patrick Geary, Eddie Chao, Dexter Bermudez, Steven Phan (SuperMicro), Frank Han, Jack Tang, Jay Engh, Minesh Patel, Leela Uppuluri (Dell), Juan Garcia-Rovetta, and Julie Brodeur (Broadcom) for their help and support in completing this work. We also thank Chris Wolf, Shobhit Bhutani, and Mark Chuang for their review comments.
Discover more from VMware Cloud Foundation (VCF) Blog
Subscribe to get the latest posts sent to your email.



