
This blog post is based on work by Uday Kurkure, Lan Vu, and Hari Sivaraman.
A technical paper has been published. In it, we give AI/ML training workload performance test results for the VMware vSphere virtualization platform using multiple NVIDIA A100-80GB GPUs with NVIDIA NVLink; the results fall into the “Goldilocks zone,” which refers to the area of good performance with virtualization benefits.
Our results show that several virtualized MLPerf v3.0 Training1 benchmarks’ training times perform within 1.06% to 1.08% of the same workloads run on a comparable bare metal system. Note that lower is better.
In addition, we show the MLPerf Inference v3.0 test results for the vSphere virtualization platform with NVIDIA H100 and A100 Tensor Core GPUs. Our tests show that when NVIDIA vGPUs are used in vSphere, the workload performance measured as queries served per second (qps) is 94% to 105% of the performance on the bare metal system. Note that higher is better.
This is exciting because you can get all the benefits of vSphere virtualization, and AI/ML training and inference workloads will perform almost as well as or even better than bare metal.
vSphere 8 gives you the power of performant virtualization with NVIDIA GPUs and NVLink
The partnership between VMware and NVIDIA brings virtualized GPUs to vSphere with NVIDIA AI Enterprise. This lets you not only achieve quicker processing times for virtualized machine learning and artificial intelligence workloads—it also lets you leverage the many benefits of vSphere, such as cloning, vMotion, distributed resource scheduling, and suspending and resuming VMs.
VMware, Dell, and NVIDIA achieved performance close to or higher than the corresponding bare metal configuration with the following setup:
- Dell PowerEdge XE8545 server with 4x virtualized NVIDIA SXM A100-80GB GPUs
- Dell PowerEdge R750xa with 2x virtualized NVIDIA H100-PCIE-80GB GPUs
Only 16 of the total 128 logical CPU cores were needed for inference in both configurations, leaving the other 112 logical CPU cores in the data center accessible for other work.
Achieving the best performance for the VMs during training required 88 logical CPU cores out of 128. The data center’s remaining 40 logical CPU cores can be used for other activities.
AI/ML Training performance in vSphere 8 with NVIDIA vGPU
Figure 1 compares the training times of MLPerf v3.0 Training benchmarks using vSphere 8.0.1 with NVIDIA vGPU 4x A100-80c against the bare metal 4x A100-80GB GPU configuration. The bare metal baseline is set to 1.00, and the virtualized result is presented as a relative percentage of the baseline. vSphere with NVIDIA vGPUs delivers near bare metal performance ranging from 1.06% to 1.08% for training when using BERT and RNN-T. Note that lower is better.
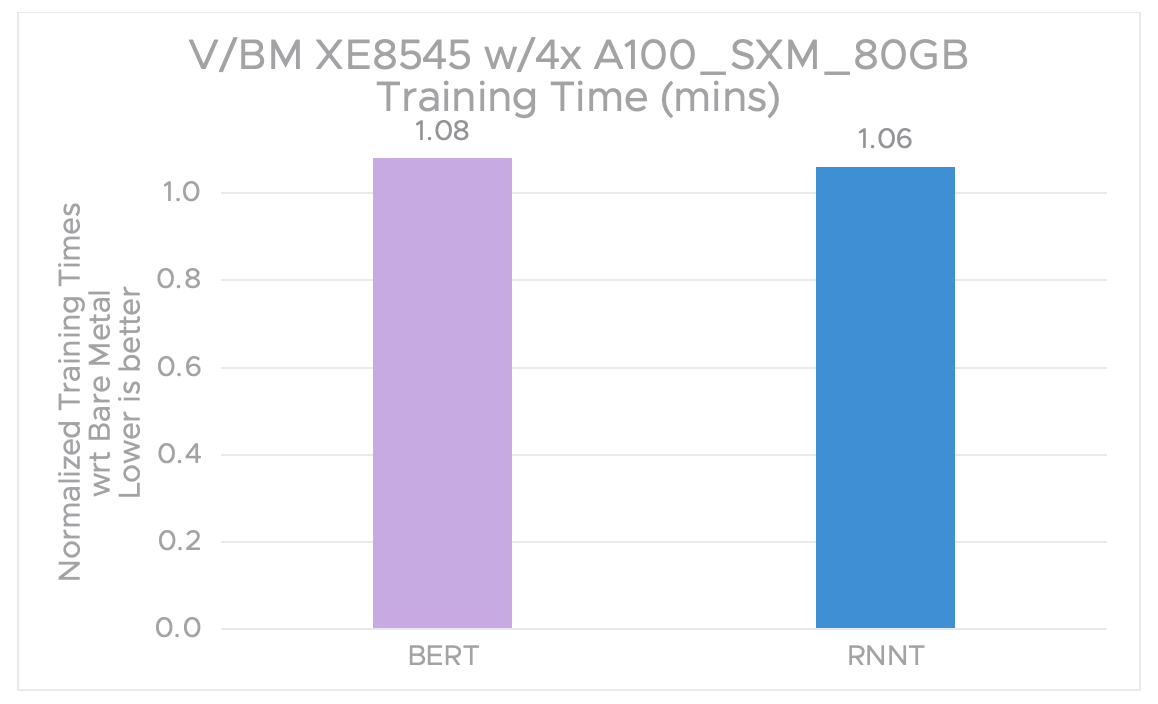
Figure 1. Normalized training times: vGPU 4x A100-80c vs bare metal 4x A100-80GB
Table 1 shows training times in minutes for MLPerf v3.0 Training benchmarks.
| Benchmark | Bare Metal 4x A100 Training Times (mins) |
vGPU 4x A100-80c Training Times (mins) |
vGPU/BM |
| BERT-large | 32.792 | 35.28 | 1.08 |
| RNNT | 55.086 | 58.447 | 1.06 |
Table 1. vGPU4x A100-80C vs. Bare Metal 4x A100-80GB Training Times (mins)
The bare metal results were obtained by Dell and are published in the MLPerf v3.0 Training closed division with the submitter id of 3.0-2050.2
Takeaways from the paper
- VMware vSphere with NVIDIA vGPU and AI technology performs within the “Goldilocks zone”—the area of performance for good virtualization of AI/ML workloads.
- vSphere with NVIDIA AI Enterprise using NVIDIA vGPUs and NVIDIA AI software delivers from 106% to 108% of the bare metal performance measured as training times for MLPerf v3.0 Training benchmarks.
- vSphere achieved inference performance with only 88 logical CPU cores out of 128 available CPU cores, thus leaving 40 logical CPU cores for other jobs in the data center.
- VMware leveraged NVIDIA NVLinks and flexible device groups to leverage the same hardware setup for ML training and ML inference.
- vSphere with NVIDIA AI Enterprise using NVIDIA vGPUs and NVIDIA AI software delivers from 94% to 105% of the bare metal performance measured as queries served per second for MLPerf Inference v3.0 benchmarks.
- vSphere achieved inference performance with only 16 logical CPU cores out of 128 available CPU cores, thus leaving 112 logical CPU cores for other jobs in the data center.
- vSphere combines the power of NVIDIA vGPUs and NVIDIA AI software with the data center management benefits of virtualization.
Read the paper for more details
For more information and for ML Inference performance test results, read the paper.
Endnotes
1 Unverified MLPerf™ v3.0 Training Closed BERT-large and RNN-T results were not verified by the MLCommons Association. The MLPerf™ name and logo are trademarks of the MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use is strictly prohibited. See www.mlcommons.org for more information.
2 The virtualized results by VMware were not verified by the MLCommons Association. The MLPerf™ name and logo are trademarks of the MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use is strictly prohibited. See www.mlcommons.org for more information.
Discover more from VMware Cloud Foundation (VCF) Blog
Subscribe to get the latest posts sent to your email.




