
Introduction
While virtualization technologies have proven themselves in the enterprise with cost effective, scalable and reliable IT computing, High Performance Computing (HPC) however has not evolved and is still bound to dedicating physical resources to obtain explicit runtimes and maximum performance. VMWare has developed technologies to effectively share accelerators for compute and networking.
VMWare, NVIDIA and Mellanox have collaborated on NVIDIA GPU integration with VMware vSphere that enables sharing of GPU across multiple virtual machines, while preserving critical vSphere features like vMotion. It is also possible to provision multiple GPUs to a single VM, enabling maximum GPU acceleration and utilization.
vSphere enables RDMA based high performance network sharing using Paravirtualized RDMA. PVRDMA also supports vSphere features like HA & vMotion.
Artificial Intelligence and Deep Learning
Artificial Intelligence is any technique that mimics human-like intelligence. In the field of machine learning mathematical techniques and data are used to build predictive models without explicit programming.
Deep learning is a subset of machine learning and is essentially a neural network that has three or more layers. Deep Learning neural networks try to simulate the behavior of the human brain by iterating and learning from large amounts of data. Deep Neural Networks leverages hidden layers to optimize, refine and improve accuracy of machine learning models.
Deep learning is a big driver of many modern AI applications and services. It is used for improving automation and the performance of many analytical and physical tasks without any need human interaction. Some examples of these applications include digital assistants, self-driving cars, fraud detection, image and voice recognition.
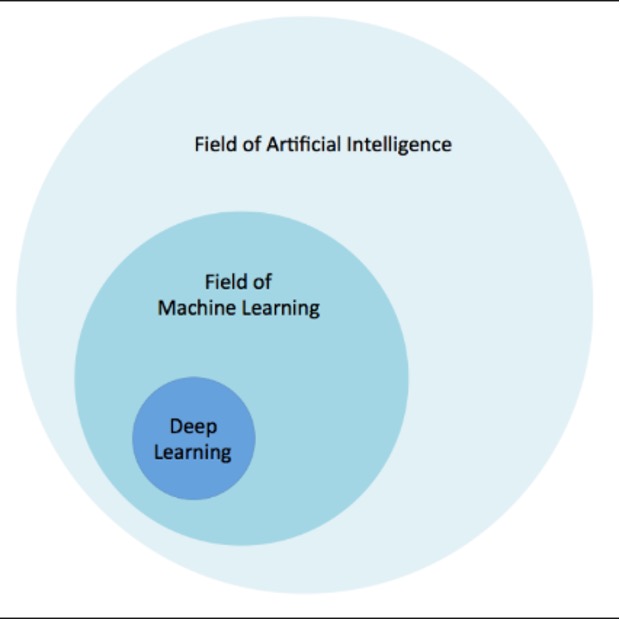
Figure 1: Artificial Intelligence and its relationship to Machine and Deep Learning
Why use GPUs for Deep Learning?
Deep Learning training requires a lot of computational power to run on. Deep Learning models can be trained faster by simply running all operations in parallel instead of sequentially. A GPU (Graphics Processing Unit) is a specialized processor with dedicated memory that conventionally perform floating point operations in a massively parallel fashion. GPUs have thousands of cores, that facilitates computation of multiple parallel processes. GPUs are well suited for training artificial intelligence and deep learning models as they can process multiple computations simultaneously.
GPUs with their massive thread parallelism and easily programmable registers are many times faster than a CPU for deep learning training operations. Additionally, computations in deep learning need to handle huge amounts of data and makes a GPU’s memory bandwidth most suitable.
Need for Distributed Machine Learning:
Normal Datacenter Servers can host only one or two GPUs each due to limitations in PCI slots and special power requirements. Large jobs with millions of layers of deep learning cannot fit in one or two GPUs and training could take a lot of time.
There is a lot of time pressure to reduce the time develop a new machine learning model even as the datasets grow in size. There is an increasing need to have distributed machine learning to reduce training time and model development. Horovod is an open source distributed training framework that supports popular machine learning frameworks such as TensorFlow, Keras, PyTorch and MXNet. Horovod distributed deep learning leverages a technique called ring-allreduce, while requiring minimal modification to the user code to run in a distributed fashion.
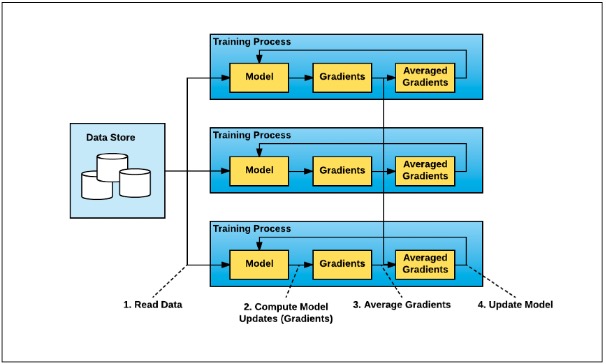
Figure 2: Distributed Training mechanism
High Speed Networking with PVRDMA & RoCE
Remote Direct Memory Access (RDMA) provides direct memory access from the memory between hosts bypassing the Operating System and CPU. This can boost network and host performance with reduced latency & CPU load while providing higher bandwidth. RDMA compares favorably to TCP/IP, which adds latency and consume significant CPU and memory resources.
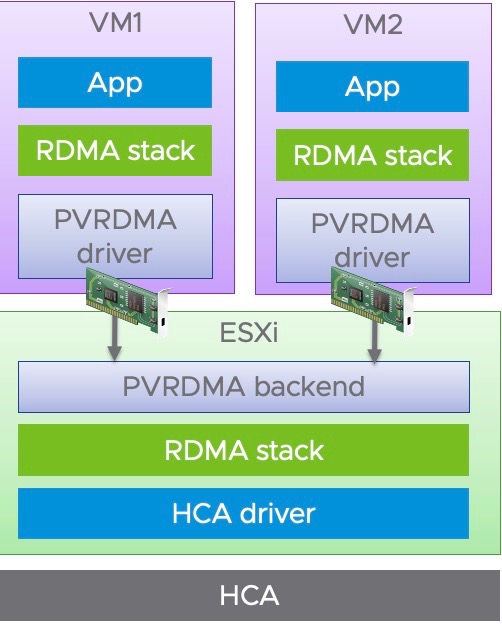
Figure 3: The PVRDMA stack
RDMA between VMs is known as PVRDMA when it uses a special paravirtualized driver from VMware. Introduced from vSphere 6.5, VMs with a PCIe virtual NIC that supports standard RDMA API can leverage PVRDMA technology. VMs must be connected to the same distributed virtual switch to leverage Paravirtual RDMA. PVRDMA can reduce overhead in networking for high performance computing and distributed machine learning workloads.
The Solution
The goal of this solution is to showcase the use of distributed machine learning to leverage HW distributed across multiple servers in the datacenter. Horovod with PyTorch is used as the machine learning platform. vSphere 7 based virtualized infrastructure is used as the base for the solution. A large image dataset is trained across many epochs (iterations) to create a robust generalized image recognition model. The solution leverages GPU based acceleration for training and uses 100 Gbps RoCE networking for PVRDMA. The scalability of the training from.1 to 4 nodes is measured with comparisons between TCPIP and PVRDMA performance.
The NVIDIA A100 GPU
NVIDIA A100 Tensor Core GPU delivers unprecedented acceleration at every scale to power the world’s highest-performing elastic data centers for AI, data analytics, and HPC. Powered by the NVIDIA Ampere Architecture, A100 is the engine of the NVIDIA data center platform. A100 provides up to 20X higher performance over the prior generation and can be partitioned into seven GPU instances called MIG to dynamically adjust to shifting demands.

Figure 4: The NVIDIA A100 GPU
NVIDIA A100 Tensor Core technology supports a broad range of math precisions, providing a single accelerator for every workload. The latest generation A100 80GB doubles GPU memory
and debuts the world’s fastest memory bandwidth at 2 terabytes per second (TB/s), speeding time to solution for the largest models and most massive datasets. (Source: NVIDIA )
Mellanox ConnectX®-6
NVIDIA® ConnectX®-6 Dx is a highly secure and advanced smart network interface card (SmartNIC) to accelerate mission-critical data center applications, such as security, virtualization, SDN/NFV, big data, machine learning, and storage. It provides up to two ports of 100Gb/s or a single-port of 200Gb/s Ethernet connectivity and the highest ROI of any SmartNIC. (Source: NVIDIA)

Figure 5: NVIDIA Connect X-6 DX for high-speed networking
In part 2 of the solution, we will look at the testing of the solution with training the large dataset and compare the performance of distributed training with PVRDMA versus TCPIP.
Discover more from VMware Cloud Foundation (VCF) Blog
Subscribe to get the latest posts sent to your email.



