Persistent Memory (PMEM) is modern technology that provides us with a new storage tier that will be beneficial for Enterprise Applications that need reduced latency and flexible data access. Examples are (in-memory) database platforms for log acceleration by caching, data writes and reduced recovery times. High Performance Computing (HPC) workloads can also greatly benefit from PMEM for example using it for in-memory check-pointing.
PMEM converges memory and storage. We now have the possibility to store data at unprecedented speed as PMEM its average latency is less than 0.5 microseconds. PMEM is persistent, like storage. That means that it holds its content through power cycles. The beauty of PMEM is that it has characteristics like typical DDR memory; It is byte-addressable allowing for random access to data. Applications can access PMEM directly for load and store instructions without the need to communicate with the storage stack.
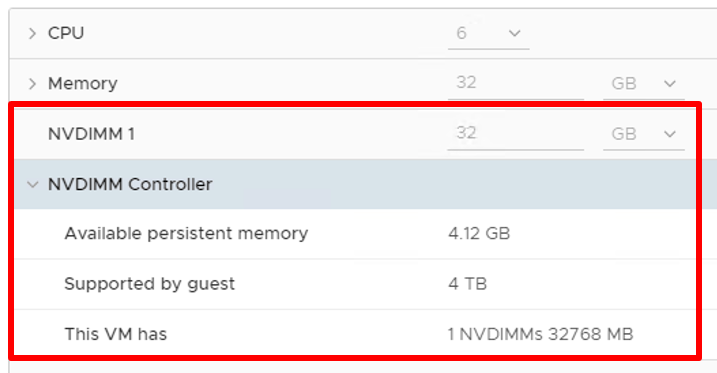
Today, we have several options to expose PMEM to a virtual machine as of VMware vSphere 6.7. We can configure a virtual machine with a Virtual PMEM Disk (vPMemDisk). Under the hood, it will use a virtual SCSI (vSCSI) device that maps to a PMEM device. As such, the virtual machine can use it like it does when using a ‘regular’ datastore. However, to fully benefit from all the PMEM goodness and its memory characteristics like byte addressable random access, we can expose the memory to the Guest OS as NVDIMM using Virtual PMEM (vPMem). This option is available when the virtual machine is running VM hardware version 14 and the guest OS supports NVM technology.