

To leverage the benefits of Overlay network topologies, the NSX Bare Metal (BM) Edge Node is used as the entry and exit point from the virtual to the physical domain. To achieve independence from the underlying physical network, GENEVE encapsulation is used. For more details about the NSX BM Edge and Edge Pod, see the latest Telco Cloud – 5G Reference Architecture.
The Edge Pod is expected to process all data traffic, so it is essential to choose a high-end server for this function. As a best practice, choose servers with fast CPU with large number of CPU cores and high-speed Network Interface Cards (pNICs). The latest NSX documentation provides a definite list of servers, pNICs, and CPU families supported by the NSX Bare Metal Edge.
From an operational perspective, the NSX Bare Metal Edge could be seen as a black box with limited options for tuning. The operator can configure services, IP addresses, and other operational aspects, but cannot make changes to hardware configurations such as CPU core allocation. For this reason, the hardware used for the NSX Bare Metal Edge is important.
Some key aspects that influence the data plane performance of the NSX Bare Metal Edge are:
- RSS and Flow Cache: The NSX Bare Metal Edge uses DPDK to accelerate its data path (or fast path). It leverages Receive Side Scaling (RSS) and Flow Cache technologies to maximize the throughput performance. By design, the NSX Bare Metal Edge expects large number of active flows to distribute the traffic across the fast path cores.
- RX/TX Buffer Ring: The default pNIC ring descriptor size for both TX and RX is 512 in the NSX Bare Metal Edge. A different configuration might be required for some use cases such as long flows (elephant flows) or bursty traffic.
Performance Scaling in the NSX Bare Metal Edge
As more data plane intensive workloads are added to the data plane cluster facing the Edge Pod, the Edge Pod must support high aggregate throughput. A straightforward approach is to proportionally add more NSX Bare Metal Edge Nodes in the Edge Cluster. Adding more NSX Bare Metal Edge servers to the Edge cluster enables higher data plane rates for the workloads. Currently this is limited to 10 nodes on the cluster with 8 active edge nodes for the same Tier-0 gateway.
The ratio between the NSX Bare Metal Edge nodes and resource hosts is highly dependent on traffic patterns. As a rule, the NSX Bare Metal Edge nodes should use as many high-speed pNICs as their hardware can support.
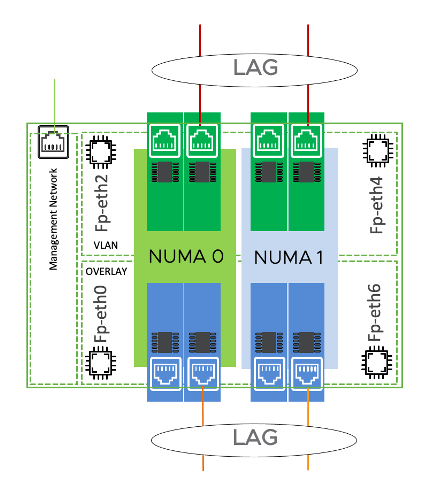
In this blog, we discuss the best practices for scaling the performance of the NSX Bare Metal Edge nodes themselves. The goal is to maximize the throughput of each node. NSX Bare Metal Edge throughput can be scaled by adding more pNICs to the NSX BM Edge host. It is important that all pNICs used for the data plane are installed in a single NUMA.
Note that with current dual socket architecture, by design NSX Bare Metal Edge use a mechanism that choose cores on NUMA 0 for data-path, always trying to look for an exit port on NUMA 0. While scale up and density of pNICs is growing, the above mechanism can impact the existing CPU cycles available to use on NUMA0.
Base on current dual socket hardware architecture (PCIe Bus topology) while you scale the pNICs there will be inevitable crossing NUMA topology. As data-path is not NUMA–aware, while scaling using LAG/LACP bond on North (towards the Provider network) and South (towards the ESXi hosts) with two slaves, one on each NUMA, there is no guarantee that all input traffic will always have a local slave on the NUMA to output.
Following this document’s guidance on pNIC NUMA alignment will help you minimize the performance impact while data will have to cross-NUMA. For more details please refer to QuickPath Interconnect (QPI).
The NSX BM Edge Node must have enough PCIe slots to install new pNICs. Those PCIe slots should have enough bandwidth to support the maximum throughput of the NICs. We recommend using high capacity pNICs in high-bandwidth PCIe slots as most servers have limited number of PCIe slots in a NUMA node.
When you add pNICs, you can configure more fast path ports in the NSX Bare Metal Edge. This will help scale the NSX BM Edge throughput only if these design considerations are followed:
- Think of the NSX BM Edge uplink ports (towards the Provider network) and downlink ports (towards the ESXi hosts) as comprising a single channel in a NUMA. To scale the capacity of an NSX BM Edge, you must increase the capacity of this channel at both ends. So, if you configure additional fast path ports in the uplink, you must also configure similar capacity with additional ports in the downlink direction. The current release of NSX BM Edge can support such scaling of the channel with more pNICs in a single NUMA only.

- When you configure more fast path cores in the NSX BM Edge, you must use link bonding (LACP) between the downlinks and the Top of the Rack switch. For example, if two pNIC ports are used for uplink, two pNIC ports should be used for downlink. These four pNICs must NUMA aligned. Lastly, the two pNIC ports in the downlink direction must use LACP link bonding.
It is important to achieve a vertical NUMA (Uplink and Downlink) alignment between pNICs LAG members.
NSX Bare Metal Edge Tuning
In this section we will describe some key components (flow cache, RSS, rx/tx ring size, software queue size) that determine BM Edge performance.
Disclaimer: The below instructions are meant as examples and the values exposed are not reflecting our direct recommendations.
Flow Cache
The NSX Edge node uses flow cache to achieve high packet throughput. Flow cache is enabled by default. This feature records actions required to be applied on each flow when the first packet in that flow is processed so that subsequent packets can be processed using a match-and-action procedure. This procedure avoids the full processing pipeline which is expensive to traverse.
It is recommended that you allocate a large capacity for flow cache if the system resources allow. The default size for both micro flow cache and mega flow cache is 256K, and the minimum is 8. The default flow cache memory allocation is 115MB per core.
Procedure
1. Open a command prompt.
2. Check the flow cache stats.
nsx-edge-1> get dataplane flow-cache stats
Micro
Core : 0
Active : 0/262144
Dont cache : 0
Hit rate : 0%
Hits : 0
Insertions : 0
Misses : 1602651
Skipped : 1018653
Bucket collisions : 0
Key collisions : 0
Mega
Core : 0
Active : 0/262144
Dont cache : 2693444
Hit rate : 0%
Hits : 0
Insertions : 0
Misses : 1602651
Skipped : 1018653
Bucket collisions : 0
Key collisions : 0
Increasing the flow cache size when the key collisions rates in the stats are high will help processing the packets most efficiently. General rule is that the higher the hit rates the better the performance, for example, with close to 100% hit rate Edge will be able to process packets most efficiently. But hit rates are determined by both flow cache size and traffic (i.e., traffic consists of short-lived flows will not have high hit rates).
Note that increasing the cache size will impact memory consumption.
3. Check the flow cache configuration.
nsx-edge-1> get dataplane flow-cache config
Enabled : true
Mega_hard_timeout_ms: 4985
Mega_size : 262144
Mega_soft_timeout_ms: 4937
Micro_size : 262144
4. Change the flow cache size.
nsx-edge-1> set dataplane flow-cache-size 524288
5. Restart the dataplane service.
nsx-edge-1> restart service dataplane
Receive Side Scaling (RSS)
RSS allows network packets from a pNIC to be processed in parallel on multiple CPUs by creating multiple hardware queues.
RSS is configured if multiple fast-path cores are used. For each packet, a hash value is generated based on 5-tuple to distribute that packet to a specific core, with sufficient entropy 5-tuple variations in the traffic. With this feature, the hashing is based on IP address source, IP address destination, IP protocol, layer-4 port source, layer-4 port destination. This allows a better distribution of the traffic across all processing cores, scaling up and maximizing system throughput.
For Bare Metal Edge, RSS is configured automatically by using all cores from one NUMA node as fast-path cores and configuring each of them to poll from all physical pNICs.
Note that RSS is a receiver side configuration, and for packets transmission, each core has a dedicated tx queue from each pNIC.
RX/TX Ring Size
The default ring size for both Tx and Rx is 512 for Bare Metal Edge.
Sometimes traffic can be bursty so using a small ring size might result in significant packet loss. On the other hand, using bigger ring size will potentially increase the memory footprint which also potentially incur performance penalty on latency. Our recommendation is to use a properly small ring size with which packet loss is minimized.
The following CLI command will change the ring size globally for all pNICs.
Procedure
1. Open a command prompt.
2. Configure the RX/TX ring size.
nsx-edge-1> set dataplane ring-size rx 1024
nsx-edge-1> set dataplane ring-size tx 1024
3. Restart the dataplane service.
nsx-edge-1> restart service dataplane
Software Queue Size
Sometimes increasing only the hardware queue size is not enough to avoid the packet drop. You might have to enable the software Rx queue, which is disabled by default. Large queues can have negative impact on performance, especially for latency sensitive applications.
For bare metal NSX Edge such restrictions do not apply. Larger queue size helps prevent packet drop especially in the Rx queue when traffic is jittery.
When you set a larger queue size for software Rx queue, you can mitigate packet drop during extremely jittery traffic.
Procedure:
1. Open a command prompt.
2. Set the software queue size.
nsx-edge-1> set dataplane packet-queue-limit 2048
3. Restart the dataplane service.
nsx-edge-1> restart service dataplane
The range for pkt_queue_limit is from 0 to 16384. Setting the range to 0 disables the software queue.
NOTE: Be aware of the potential impact in your services by invoking the above NSX CLI command to restart data-plane service.
Summary of Recommendations:
- Set up the hardware BIOS on server for optimal performance
- Run the latest version of the BIOS available for your system.
- BIOS must enable all populated processor sockets and all the cores in each socket.
- Enable the Turbo Boost in the BIOS if your processors support it.
- Select High Performance Profile in the BIOS setting for CPU to allow maximum CPU performance. Note that this might increase power consumption.
- Some NUMA-capable systems provide an option in the BIOS to disable NUMA by enabling node interleaving. In most cases, disabling the node interleaving and leaving NUMA enabled is better for performance.
- Enable hardware-assisted virtualization features such as, VT-x, AMD-V, EPT, RVI in the BIOS.
- As a best practice disable Hyper-threading (HT) on the host so we can achieve exactly one thread per core.
- Use the pNICs and CPUs that are supported by the NSX-T BM Edge as listed in the latest NSX-T Data Center documentation.
- Choose a host for BM Edge Server with good density of cores per NUMA and maximum number of pNICs in NUMA0. This ensures that all resources on the same NUMA node are used to maximize the utilization of the system locally.
- Network cards must be installed in PCIe slots with enough bandwidth to support their maximum throughput.
- To maximize the throughput, avoid the condition where BM Edge uses a single pNIC with two ports one port is used for Downlink and the other for Uplink. Instead, separate Downlink and Uplink across separate pNICs (PCIe).
- Within dual core socket servers consider the NSX BM Edge uplink and downlink ports as a channel in a NUMA. Scaling the NSX BM Edge throughput should be considered as scaling the capacity of this channel, by adding more fast path ports to it at both ends.
- Use the LACP link bonding for scaling the bandwidth between downlink and TOR.
- Configure enough number of multiple flows for entropy of the packets in the traffic to utilize more cores for packet processing in the data path of the BM Edge.
- Firewall rules on the NSX BM Edge data path can have a negative impact on performance and hence they should be carefully implemented or avoided.
References:
Telco Cloud Platform 5G Reference Architecture Guide
Telco Cloud Platform 5G Edition Performance Tuning Guide
Discover more from VMware Telco Cloud Blog
Subscribe to get the latest posts sent to your email.






