
Is there a performance tax for real-time RAN workloads on VMware vSphere? The answer is no. VMware ran industry-standard real-time micro-benchmarks, namely cyclictest and oslat, to compare the performance of RAN workloads on VMware vSphere and bare metal and found that performance is equivalent.
The tests show that there is no performance penalty or latency tax with VMware vSphere 7.0 Update 3 RC. The performance of radio access network workloads on VMware vSphere 7.0U3 RC vs. bare metal, as measured by the real-time micro-benchmarks cyclictest and oslat, is equivalent.
Cyclictest, which uses a hardware-based timer to measure platform latency and jitter, demonstrated that the latency on both vSphere 7.0U3 RC and on bare metal was less than 10 microseconds. A 10-microsecond latency is well within the latency requirements of RAN workloads.
The oslat performance test is an open-source micro-benchmark that measures jitter in a busy loop. Instead of using hardware-based timers, this benchmark uses a CPU bound loop as its measurement—which emulates a virtualized RAN workload in a real-world scenario, such as a polling thread using the Data Plane Development Kit (DPDK).
The following charts show the test results on bare metal and on vSphere 7.0U3 RC for the two tests. The results are equivalent (in the error range). Photon RT was used for both the bare metal and vSphere tests, with the same configurations, to create a fair comparison.
Equivalent Cyclictest Results
Here are the results for the cyclictest. The gap measured by cyclictest is the x-axis latency for this graph, and the y-axis is the number of samples at that latency.
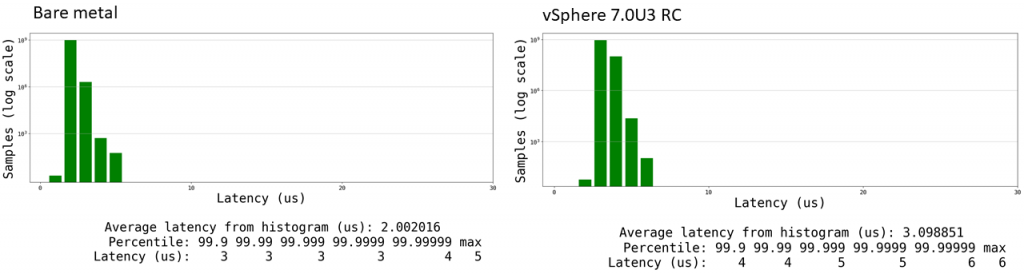
Since cyclictest is just measuring the virtualization overhead of a timer at this point, we wanted to use a tool that would more accurately measure the amount of time that guest execution is interrupted.
Equivalent Oslat Test Results
Short for operating system latency, oslat comes with cyclictest as part of the Linux real-time tests package. The oslat micro-benchmark runs a busy loop that continuously reads the real time. Anything that interrupts guest execution pauses the busy loop and shows up as a gap in real time. Since the oslat test doesn’t use timers, there is no timer virtualization overhead.
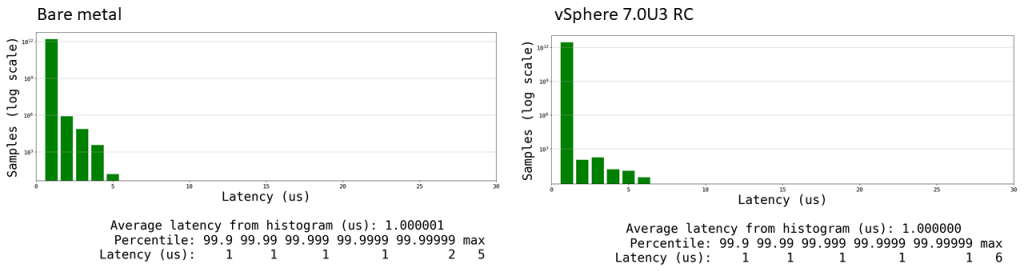
In the chart, the real-time gap measured by oslat is the x-axis latency for this graph, and the y-axis is the number of samples at that latency. The graph shows the latency distribution of the oslat test run on bare metal and on vSphere 7.0U3 RC, both with Photon 3.0 RT.
The oslat benchmark is a better representation of a real-world virtualized RAN workload because the tests use a poll mode driver to read and write packets to the NIC that connects to the cell tower.
Test Configuration
Here are the configurations that were used to run the cyclic and oslat tests at VMware.
The tests used the following server models:
- Dell R640/R740
- Dell VEP4600
The PTP NICs for virtualized RAN are Intel 710 and 810.
Here are the configurations for the firmware and BIOS:
- CPU Power and Performance: Performance
- Configurable TDP: Nominal
- Turbo Boost: Enabled
VMware ESXi 7.0U3 RC is required. This version of the VMware hypervisor is optimized for virtualized RAN workloads. It includes an enhanced tail latency profile for cyclictest and support for PTP SR-IOV.
Virtual Machine Configuration
Optimizations in the vSphere CPU scheduler for NUMA architectures ensure that RAN workloads run on VMs with high performance. To optimize vSphere for RAN workloads, we configured some advanced options for the virtual machines. (Information on setting advanced options for virtual machines is in the vSphere 7 documentation).
Some of the following values and settings depend on the virtual hardware version in use, and these values and settings are shown with variables.
First, we configured manual VM exclusive pinning:
- sched.vcpu0.affinity=x # where x is the pcpu number
- sched.vcpu1.affinity=y # where y is the pcpu number
- sched.vcpu2.affinity=z # where y is the pcpu number
- …
- # repeat for all vCPUs of the VMs
- sched.cpu.affinity.exclusive=TRUE # mark the above CPU affinity as exclusive
- sched.cpu.affinity.exclusiveType=loose # set this if you are pinning two vcpus to a pair of physical HT twins
Second, we configured manual VM memory optimization:
- sched.mem.min=MEM_SIZE # where MEM_SIZE is the configured memory size of the VM, or via GUI
- sched.mem.pin=TRUE
- sched.mem.prealloc=TRUE
- sched.mem.prealloc.pinnedMainMem=TRUE
- …
- sched.mem.lpage.enable1GPage = TRUE # this enables huge page
Third, we applied the following advanced settings for an enhanced tail latency profile. Note that these settings are not virtual-hardware-version dependent.
- sched.cpu.affinity.exclusiveNoStats = “TRUE”
- monitor.forceEnableMPTI = “TRUE”
- timeTracker.lowLatency = “TRUE”
These settings ensure that among other things, vSphere optimizes high-performance workloads by scheduling processes into the same NUMA domain. To ensure high performance, there is no cross-domain context switching or memory access.
Important: With ESXi 7.0U3 RC, the setting sched.cpu.affinity.exclusiveNoStats = “TRUE” makes a VM’s usage appear to be fully busy at 100 percent per vCPU. It is therefore important to use in-guest stats for CPU utilization and usage evaluation.
Photon RT Configuration for Both vSphere and Bare Metal
Photon RT 3.0 was used on the bare metal server and on ESXi for both the cyclictest and oslat micro-benchmarks. Photon RT was configured the same on the bare metal and the ESXi hosts.
Photon OS provides a secure Linux runtime environment for running containers, including CNFs, and a real-time kernel flavor called ‘linux-rt’ to support low-latency RAN workloads.
linux-rt is based on the Linux kernel PREEMPT_RT patch set that turns Linux into a real-time operating system. In addition to the real-time kernel, Photon OS 3.0 supports several userspace packages such as tuned, tuna, and stalld. These userspace packages are useful to configure the operating system for real-time workloads. The linux-rt kernel and the associated userspace packages together are referred to as Photon Real Time (RT).
Install Photon RT by downloading the latest version of the real-time ISO at, for example, the following URL: https://packages.vmware.com/photon/3.0/Rev3/iso/photon-rt-3.0-a383732.iso
The landing page for downloading Photon OS, including Photon RT, is on GitHub.
We tuned Photon RT on both the bare metal machines and the virtual machines to isolate the CPUs that are running the cyclictest and oslat measurement threads. The following is what is minimally needed to obtain the cyclictest and oslat benchmark numbers. More information on setting the following configuration changes is in the Photon documentation.
- We ran the following command to update Photon RT to the latest kernel:
- $ tdnf update
- We set up the tuned realtime profile.
- We edited /etc/tuned/realtime-variables.conf to set the range of the isolated CPUs:
- Example:
- isolated_cores=2-29
- After setting the isolated cores, we turned on the tuned realtime profile:
- $ tuned-adm profile realtime
- Once these settings were applied, we needed to reboot twice for the isolcpus=2-29 to appear on the Linux kernel command line. It can be verified by running the following command:
- cat /proc/cmdline
- We set up additional Linux kernel boot parameters:
- We edited /boot/grub2/grub.cfg and added “nohz=on nohz_full=2-29” to the end of the Linux boot command line.
- Then we rebooted again, and then we ran the tests using the parameters shown below for cyclictest and oslat.
Keep in mind that the number of CPUs might be different, but the same number of test threads (one per CPU) on the same physical CPUs on the same physical socket were used on both bare metal and in the VM to make the comparison as equivalent as possible.
More information about configuring the Photon real-time operating system for real-time, low-latency workloads is in the Photon documentation.
Parameters for Running the Cyclictest and Oslat Micro-Benchmarks
Here are the cyclictest and oslat parameters that VMware used to run the tests:
- $ taskset -c 1-29 rt-tests-2.1/cyclictest -m -p99 -D 1h -i 100 -h 100 -a 2-29 -t 28 –mainaffinity=1
- $ taskset -c 2-29 rt-tests-2.1/oslat -c 2-29 -f 99 -D 3600
Virtual Machines and Performance Management for CNFs in VMware Telco Cloud Platform RAN
VMware Telco Cloud Platform RAN is a RAN-optimized platform that runs virtualized baseband functions, virtualized distributed units (vDUs), and virtualized centralized units (vCUs) in accordance with RAN performance and latency requirements. The platform uses a telco-grade Kubernetes distribution to orchestrate containers on virtual machines in a telco cloud. Simply put, running containers on virtual machines helps CSPs speed up the transition from 4G to 5G and ease the management of CNFs and 5G services.
With VMware Telco Cloud Platform RAN, the Topology Manager optimally allocates CPU, memory, and device resources on the same NUMA node to support performance-sensitive workloads. VMware Telco Cloud Platform RAN also optimizes the performance of large Kubernetes clusters and mixed workloads.
Elasticity to Balance Cost and Performance
With virtualization, you can use vSphere’s built-in elasticity of scale to balance cost and performance when you need to.
- Workloads can be migrated to maximize performance.
- Workloads can be consolidated to minimize resource costs.
The outcome is cost-effective performance: Workloads that need high performance get it, and workloads that don’t need high performance can be run at a lower cost.
Centralized performance management with automation
Through dynamic resource allocation and late binding, VMware Telco Cloud Platform RAN optimizes workload placements. When the system instantiates a workload, it optimizes a Kubernetes cluster or creates a new one to match the CNF requirements through late binding. Here are some of the things late binding does to optimize worker nodes and their resources:
- Enable Huge-Pages
- Install the Photon OS real-time kernel
- Isolate Cores
- Configure TuneD
- Allocate vGPU
As for the components of a virtualized RAN, programmable resource provisioning optimizes where to locate DUs and CUs. When you onboard a virtualized RAN function, you can programmatically adjust the underpinning availability and resource configuration based on the function’s requirements.
To meet high-performance, low-latency requirements, DUs can be placed at the far edge near users. CUs, meanwhile, can be automatically placed or dynamically moved closer to the core to maximize resource utilization. These late-binding capabilities let you dynamically move DU and CU resources on demand to improve resource utilization or to add more resources when necessary.
And you can do it at scale, from a centralized location, with automation. VMware Telco Cloud Platform RAN automates performance configurations and management for your RAN workloads.
Conclusion
There is no performance tax for real-time RAN workloads on VMware vSphere. VMware tests show that the performance of benchmarks that mimic real-world RAN workloads on bare metal and vSphere 7.0U3 RC is equivalent.
In addition to performance, operating CNFs in production requires security, lifecycle management, high availability, resource management, data persistence, networking, and automation ─ all of which are an integral part of VMware vSphere and the VMware Telco Cloud.
Here’s a sampling of white papers and blog posts that explain the benefits of virtualization over bare metal for 5G:
- E-Book for Telco Executives: The Benefits of Running CNFs on VMs: Optimizing Mixed Workloads on Shared Infrastructure with Kubernetes on VMware Telco Cloud Platform
- White Paper: Containerized Network Functions on Virtual Machines or Bare Metal? Securing, Managing, and Optimizing CNFs and 5G Services at Scale
- Solution Brief: Run CNFs on Virtual Machines To Optimize 5G Networks
- Blog Post: Running CNFs on Bare Metal—Merit or Mirage? The Abstraction of Virtualization Yields Concrete Benefits
- Blog Post: Why Choose VMware Virtualization for Kubernetes and Containers
- Blog Post: vSphere with Tanzu Supports 6.3 Times More Container Pods than Bare Metal
- Product Information: VMware Telco Cloud Platform RAN Datasheet
- E-Book: Modernize to Monetize: Reimagine the Telco Cloud to Capitalize on 5G
Discover more from VMware Telco Cloud Blog
Subscribe to get the latest posts sent to your email.






