

The fifth generation (5G) wireless network technology is designed to meet the challenging system and services requirements of the existing and emerging applications. The main goals of 5G are to improve capacity, reliability, and energy efficiency, while reducing latency and massively increasing connection density.
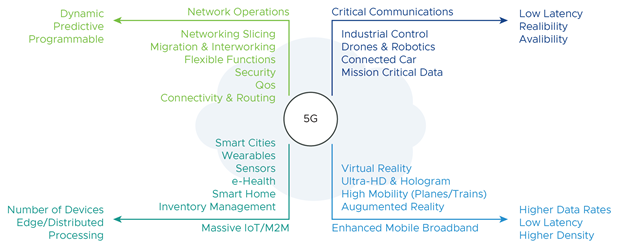
Modern applications such as tele-medicine, smart cities, augmented and virtual reality, and so on, mandate new specifications for throughput, reliability, end-to-end (E2E) latency, network density, and network robustness.
With these modern applications and the ever-increasing data traffic in the Communications Service Providers networks, there is an even greater need for reliability, throughput, latency, and jitter when it comes to 5G networks.
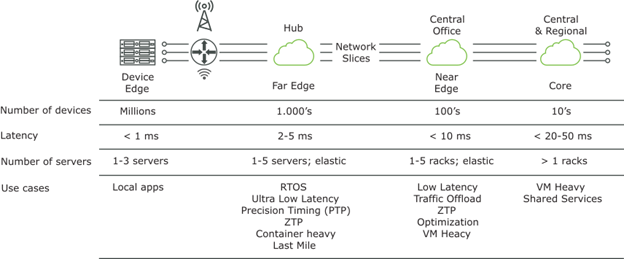
In this blog, we discuss the configuration practices for the data plane CNFs focusing on the compute and network components in the following logical layers of VMware Telco Cloud Platform to meet 5G network requirements.
- Infrastructure Layer which includes the physical compute, physical network, and the virtual compute provided by VMware vSphere®.
- CaaS Layer which includes the Container-as-a-Service (CaaS) layer built on top of the infrastructure layer using VMware Tanzu™ Standard for Telco.
The compute and network capacity requirements of the data plane intensive CNFs can vary based on the type of CNF. The performance of the data plane intensive CNF in a host depends on the compute and network capacity allocated to the CNF.
We have identified two type of CNFs (Network-bound & CPU-bound)
- Some data plane intensive CNFs do simple packet forwarding. These CNFs are Network- Bound and their throughput is limited by the allocated network capacity in the host.
- In addition to packet forwarding, other data plane CNFs perform Deep Packet Inspection (DPI), filtering, heuristics, and so on. These data plane CNFs are CPU-Bound, and their throughput is limited by the allocated compute capacity in the host.
This blog accompanies a new white paper we just released on the subject. The white paper can be found here.
Infrastructure Layer
Physical Compute

- CPUs with a high count of cores per NUMA
The infrastructure layer must be set up correctly to support high data throughput and low latency for the data plane intensive CNFs.
There are a lot of reasons to ensure that your NFV environment is ready to host data plane intensive workloads.
You then need to make sure that the actual server itself is set up to support data plane performance.
- BIOS tuned for performance
All the BIOS configurations that are designed to save CPU power and bring down the server’s heat so you can save on cooling will interfere with your ability to really reach high throughput for data plane workloads.
Every BIOS is different but in essence you want to ensure that your BIOS is set for performance
- Turbo Boost On & Hyper Threads Active
One thing we recommend is to make sure that your Turbo Boost is set to on and that you have hyper thread support in the BIOS.
Physical Network
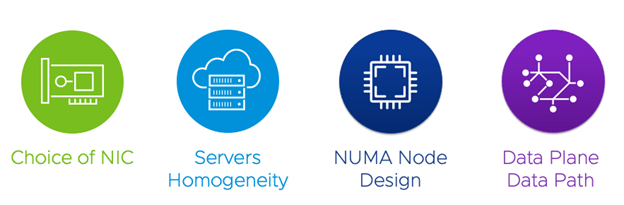
- Choice of NIC
The underlying physical network infrastructure must support high network throughput and low network latencies on the data path of the data plane intensive CNFs.
You need to make sure that your NICs have the latest poll mode drivers and the latest firmware. For now, Intel and Mellanox NICs are supported as well as many of their derivatives (such as Dell for example).
- Server Homogeneity
The server model and configurations used for data plane CNFs must be identical. For example, the same NIC and NIC firmware must be used in all hosts used for data plane CNF.
- NUMA Node Design
If multi-socket servers are used for data plane intensive CNFs, design all the Non-Uniform Memory Access (NUMA) nodes identically. For example, if the data plane in a single NUMA uses two NICs, other NUMA nodes must also use two NICs for the data plane applications.
This guideline applies to other components that have NUMA locality such as memory and CPU. It does not apply when using single-socket servers.
- Data Plane Traffic Path
The speed of any network is determined by its slowest link. To drive the maximum performance out of VMware Telco Cloud Platform that runs the data plane intensive CNFs, the NICs, Top-of-Rack (ToR) switches, and End-of-Row (EoR) devices must support high data plane performance.
CaaS Layer
- Virtual Compute
Virtual compute is a virtual machine (VM) or virtual computer that runs an operating system and applications, like a physical computer. VMware ESXi, the hypervisor within the vSphere environment, serves as a platform for running VMs and allows the consolidation of computing resources. VMs are the building blocks of the CaaS layer within VMware Telco Cloud Platform, so the VMs that host the data plane intensive CNFs must be tuned correctly for high throughput and low latencies.
- Secondary Network
Each CNF consists of multiple pods. The default network interface on the Pods is called Primary Network. The Primary Network can serve all types of communication including management, Pod-to-Pod, Pod-to-Service, and External-to-Service communications.
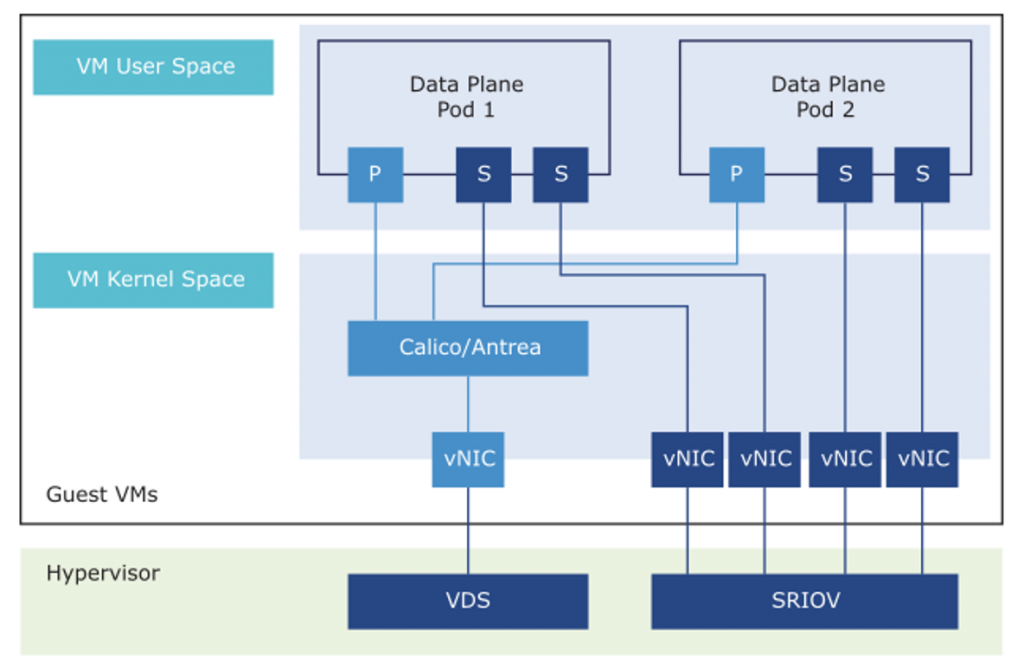
For Data Plane Intensive CNF pods, it is recommended to have one or more dedicated secondary interfaces for fast-data path. The secondary CNI can meet the data plane requirements such as low latency and high throughput.
- Worker Node
Two types of worker profile have been emerging:
- HighPerf Profile – for Kubernetes nodes that host high throughput, low latency, or real-time CNF pods (DU, CU-UP, CU-CP, UPF).
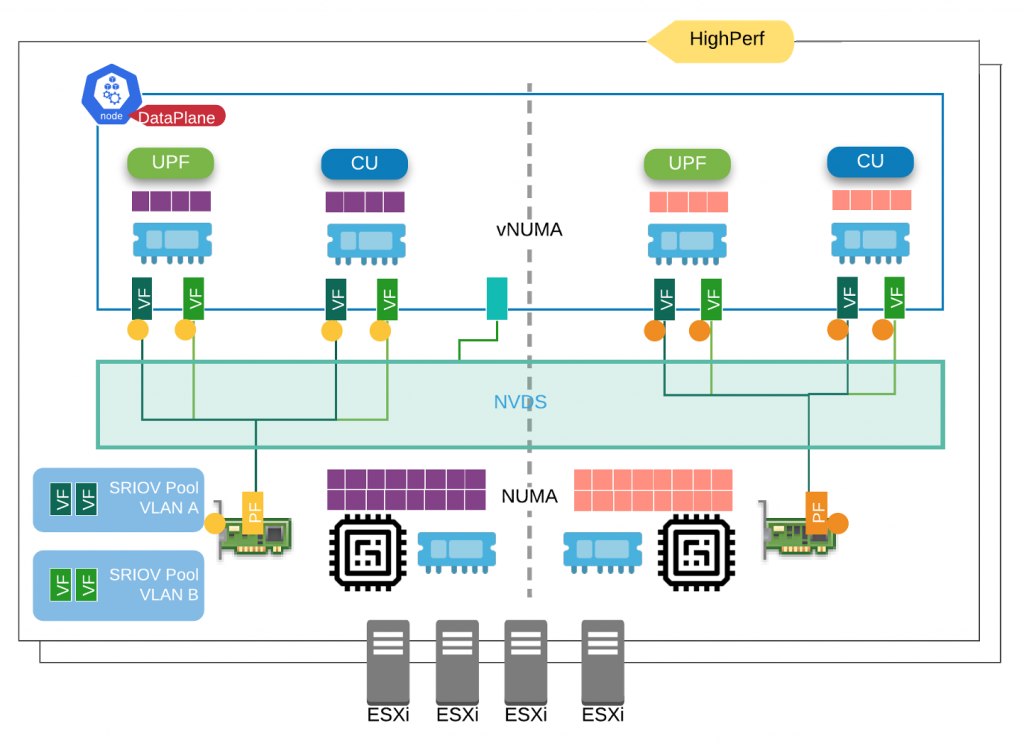
Will require node configuration such it: real-time kernel, real-time profile, SRIOV/EDP, NUMA alignment, CPU pining and isolation, HugePage, etc.
- Optimal Profile (General Purpose Profile) – for Kubernetes nodes that host standard CNF pods (AMF, SMF, AUSF, UPF, NRF, Prometheus, Elasticsearch, Harbor)
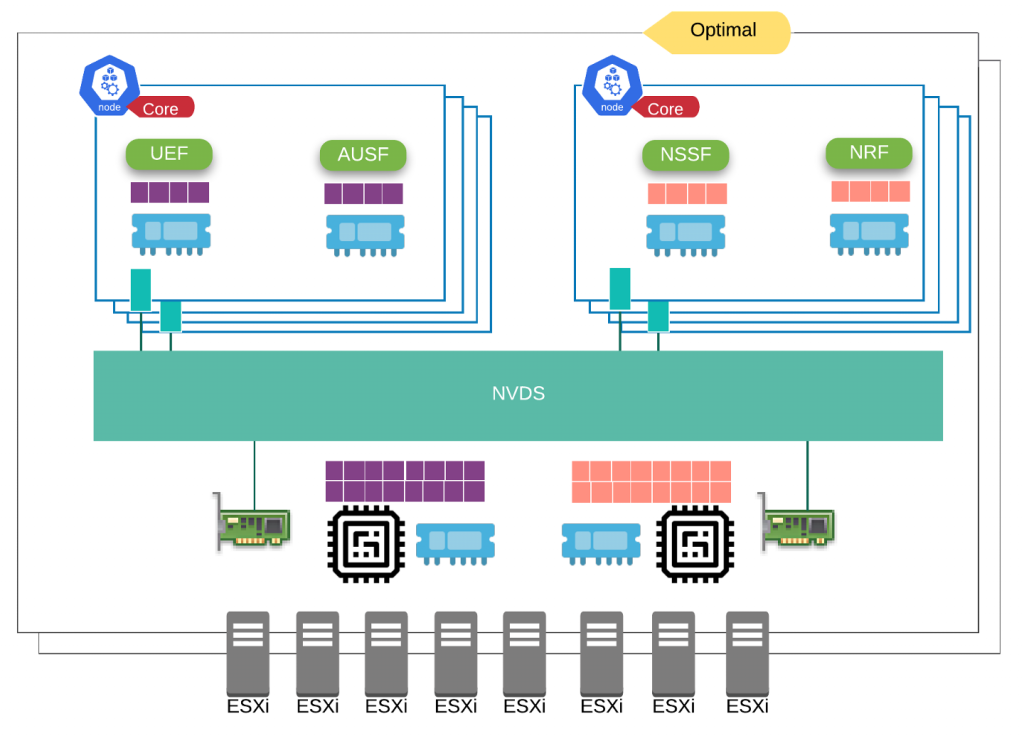
Will use smaller worker nodes with User-defined Over-subscription Ratio, say 1:8 as example. No node configuration required.
At the end the work node profile is a matter of choice base on application requirements.
By having multiple workers that are equal or small than the NUMA, you get optimal placement without pinning workloads to specific core complexity. Within smaller nodes you archive NUMA alignment, leverage ESX NUMA balancing, avoid Linux kernel resource contention (buffers, apps competing for sockets). By segmenting into smaller workers, you also can get better pod density, avoiding OS overruns.
Conclusion
It is critical to understand the capabilities and performance of the NIC and its features are a key factor for a successful implementation:
- Throughput performance
- PCIe Speed
- CPU offload capacity
- Multi-queue support
- DPDK supported
- SR-IOV passthrough
Through this blog we have provided a holistic approach to both the physical and virtual domains that help you achieve accelerated performance for the data plane CNFs.
VMware collaborates with several Network Equipment Providers (NEPs) to ensure that the data plane CNFs benefit from VMware Telco Cloud Platform.
References:
- Tuning Telco Cloud Platform for Data Plane Intensive Workloads.
Run CNFs on Virtual Machines to Optimize your 5G Networks - Performance Best Practices for VMware vSphere 7.0.
VMworld Sessions
- Exceeding the Speed Limit in Network Performance [TLCG2645]
- 60 Minutes of Non-Uniform Memory Access (NUMA) 3rd Edition [MCL1853]
- Extreme Performance Series: Performance Best Practices [MCL1635]
If you’re interested in hearing more about VMware Telco Cloud Platform, please joins us on November 11th at Telecom TV’s Telco Innovation Summit: Strategies for 5G, RAN & the Edge.
Discover more from VMware Telco Cloud Blog
Subscribe to get the latest posts sent to your email.







