

Part two of a two-part series.
In part one of the series, we discussed the role of the service assurance capabilities from VMware by Broadcom in enabling a Communication Service Provider (CSP) to gain insights into the design and deployment phase of its network. In the case covered in part one of the blog, the network is composed of, at a minimum, VMware Telco Cloud Platform hosting the network functions. The insights came from using its pipeline monitoring and discovery and topology mapping features. Once the logical topology of the network has been discovered and mapped, real-time monitoring of its performance and operations is crucial so you can continuously optimize your day-to-day operations.

This blog post covers the following key topics:
- Fault and performance management with root-cause analysis for cross-domain analytics
- Baseline configuration and anomaly detection
- Closed-loop service assurance for effective remediation
Fault and Performance Management with Root-Cause Analysis
The service assurance capabilities from VMware monitor the health of the network through seamless integration with various in-built and third-party collectors. The monitoring is comprehensive — it covers different components, from the transport layer to physical hardware, virtual infrastructure, containers-as-a-service (CaaS) infrastructure, and network functions. The service assurance capabilities collect critical metrics for fault and performance management, triggering alarms to notify Network Operations Center (NOC) or Service Operations Center (SOC) operators about faults or performance degradation. This proactive approach enables swift issue resolution, ensuring the overall health and efficiency of the network and minimizing downtime.
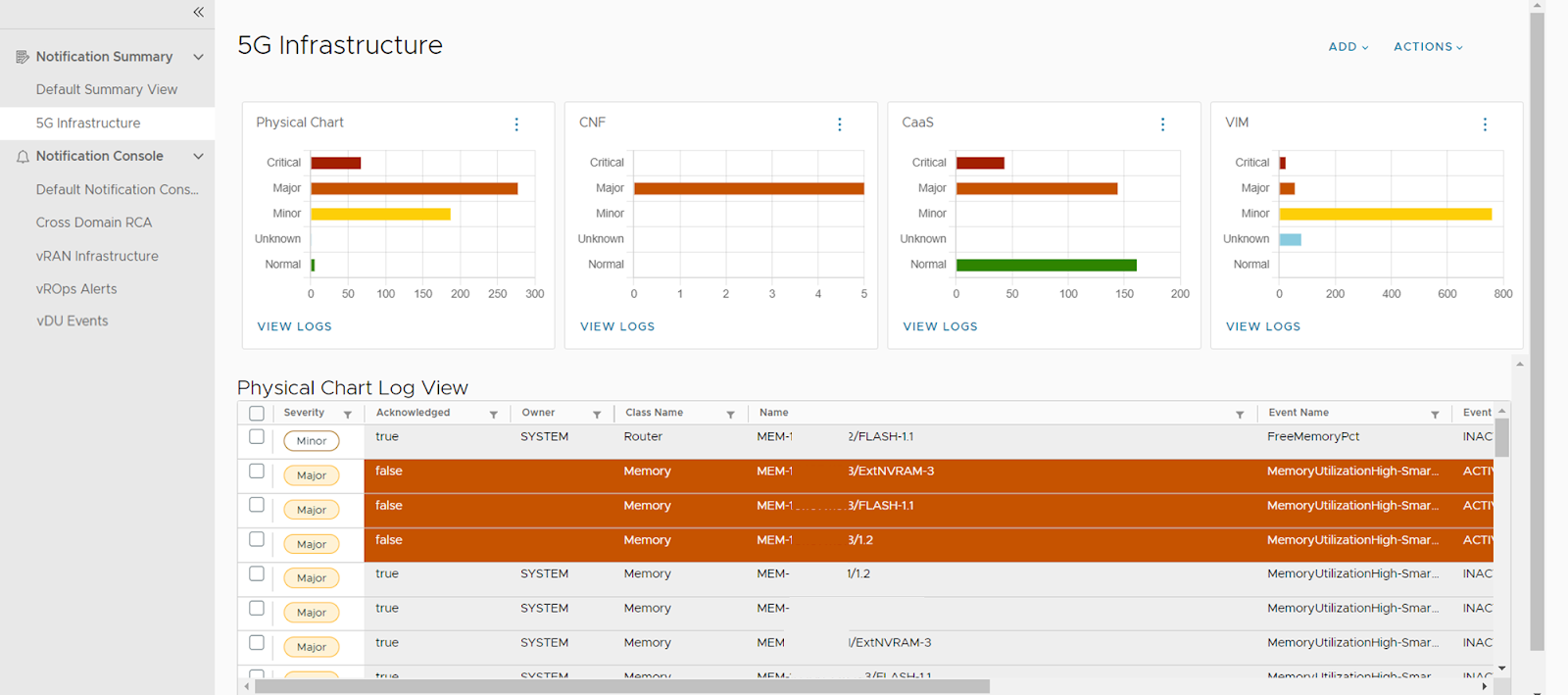
The service assurance capabilities integrate with the Element Management Systems (EMS) of various network equipment providers (NEPs) to collect and monitor events and faults related to the network functions to give you granular visibility into the health and performance of these critical components. When any impairments or faults are detected, the system generates alerts, enabling focused troubleshooting and remediation efforts. Additionally, it continuously monitors key performance metrics, such as throughput and latency, to identify potential performance degradation. In the event of performance issues, alerts are generated with detailed actionable information about issues, including fault type, affected component, severity, and a clear description.
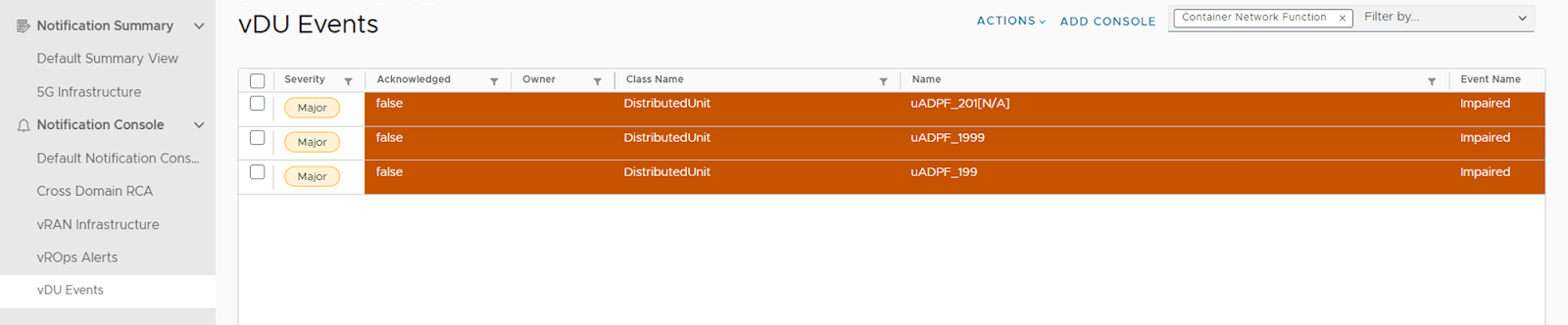
This detailed insight enables you to quickly identify and address the problems in the network, facilitating prompt resolution and minimal impact on network operations.
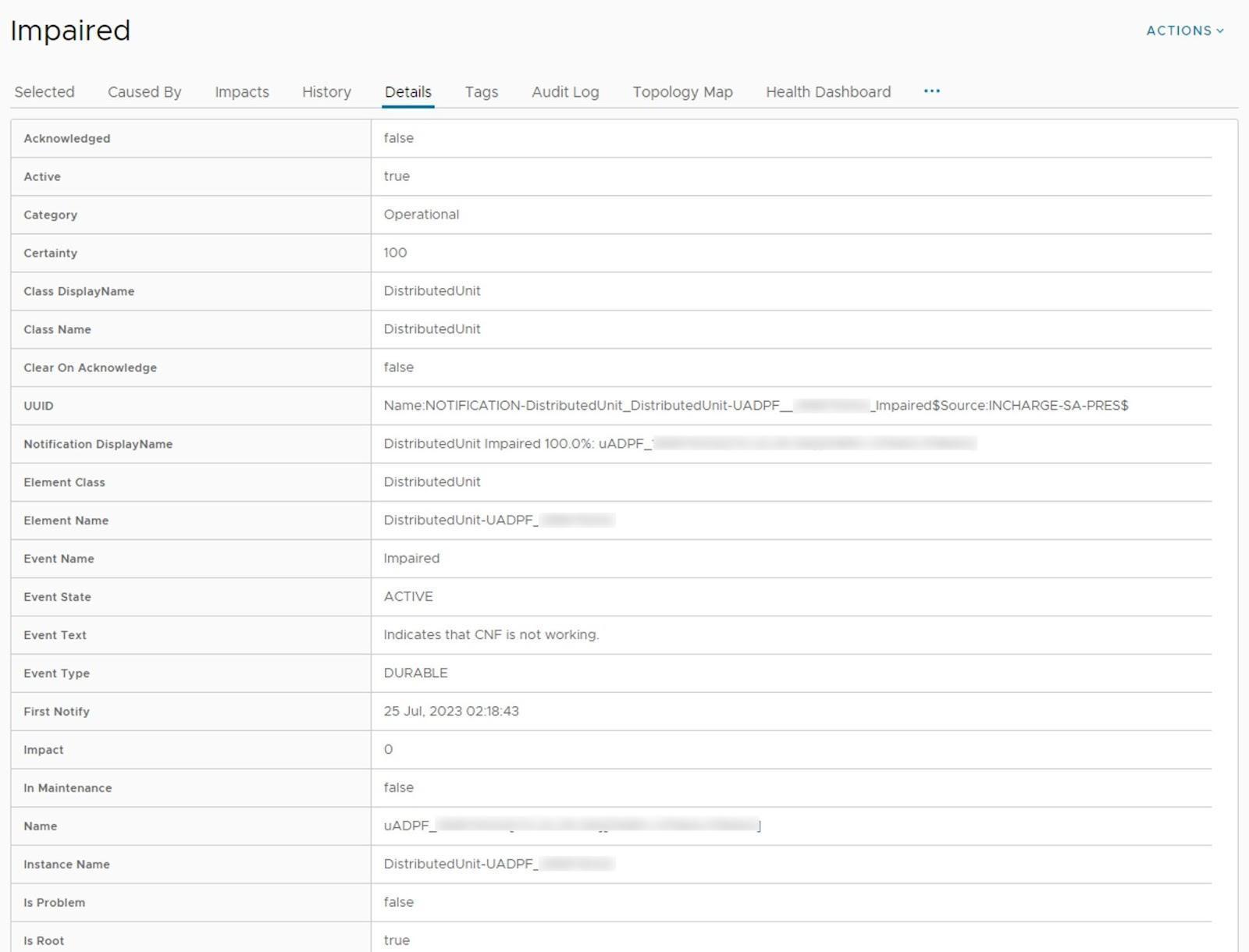
Baseline Configuration and Anomaly Detection
In addition to generating alerts for faults, the service assurance capabilities also feature anomaly detection. You can set custom baseline thresholds for key performance metrics such as memory, processor, file system, and network interface usage. It continuously monitors device performance, triggering alerts when utilization exceeds pre-set baseline thresholds. Moreover, you can generate detailed historical reports for each device, providing valuable insights for in-depth analysis and optimization.
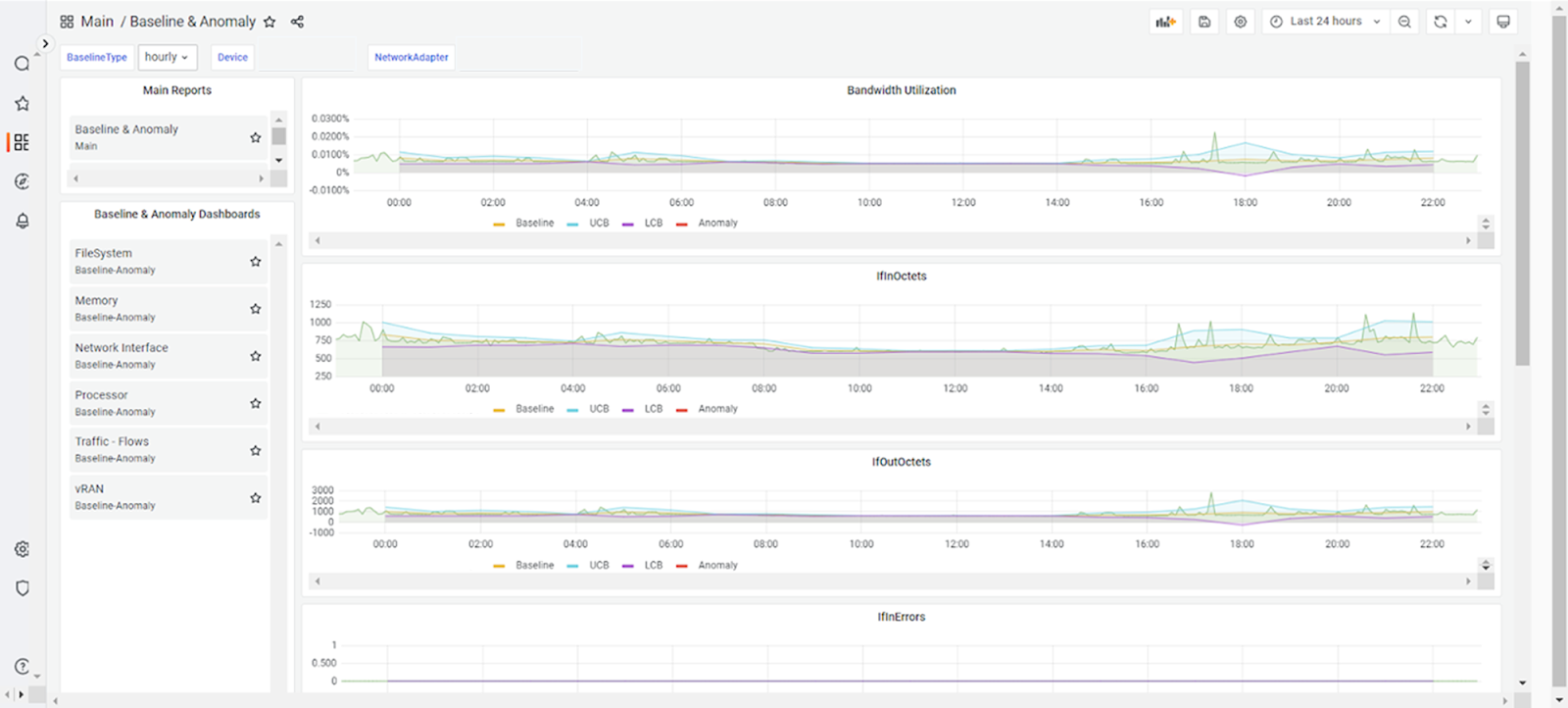
Going a step further, the service assurance capabilities employ advanced correlation techniques to analyze multiple alarms gathered from various data collectors to pinpoint the root cause of faults, filtering out false positives and noise to provide a clear and actionable view of the issue. For instance, imagine a scenario where multiple alerts are triggered, indicating that a container network function, Kubernetes pod, and network slice are all experiencing issues. Additionally, a fault is reported that the physical interfaces on a VMware ESXi host are down. By applying advanced correlation techniques, the service assurance capabilities associate the root cause of these errors with interfaces on the ESXi host being down. It then links this root cause to the other alerts, presenting a simplified view of the issue. You can also drill down into individual fault details to understand the relationships between faults and their underlying causes, streamlining the troubleshooting process and enabling faster resolution.
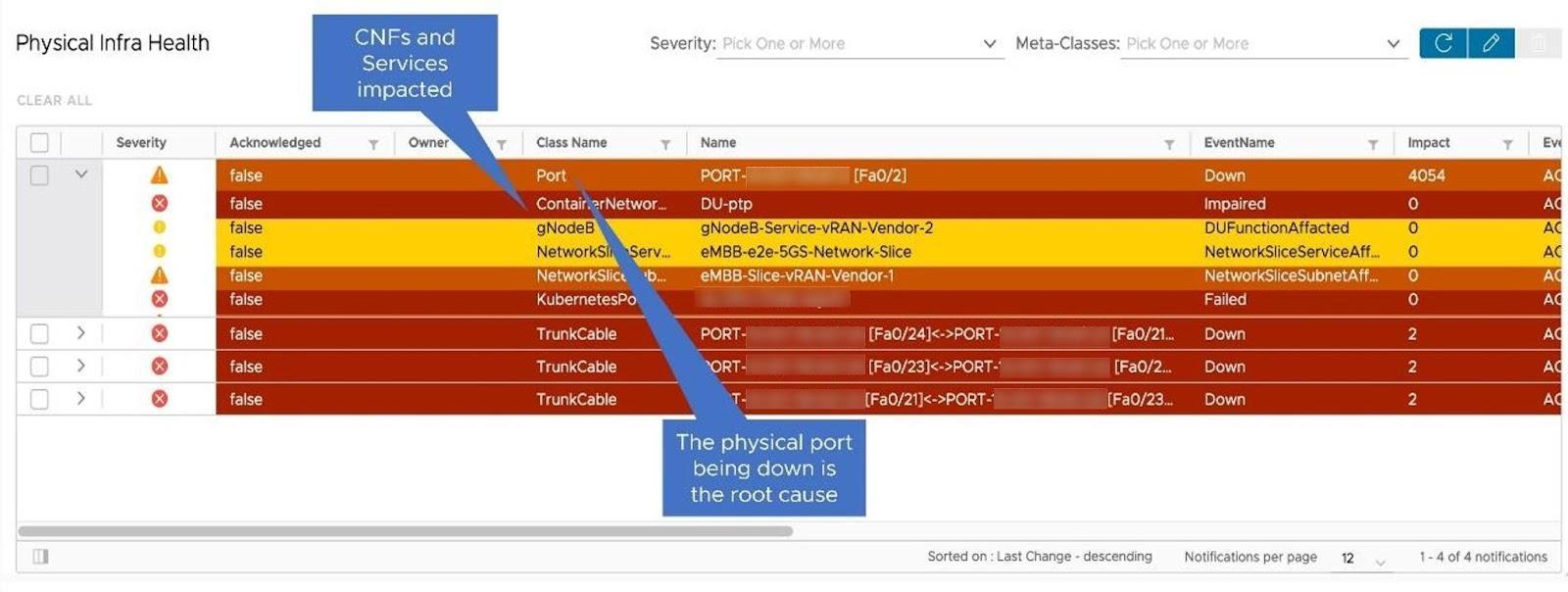
Closed-Loop Service Assurance
We have explored the service assurance capabilities in effectively discovering, monitoring, and reporting faults and anomalies in the network. To ensure reliable connectivity, CSPs require swift and closed-loop remediation to resolve issues in the network.
The service assurance capabilities allow you to define custom remediation policies that can be applied to resolve faults and anomalies in the network. You can configure remediation rules for virtual infrastructure, CaaS infrastructure, network functions, and the transport layer and choose whether to trigger them manually or automatically through its seamless integration with telco automation capabilities from VMware. When set to manual, the rule notifies NOC and SOC operators of the fault or anomaly, requiring manual intervention. In automated mode, the remediation action is triggered when the corresponding alarm is generated.
Summary
By combining the service assurance capabilities and telco automation capabilities from VMware with Telco Cloud Platform, you can unlock seamless, multi-layer, and multi-vendor cross-domain assurance from the start, ensuring comprehensive coverage across your initial deployment and day-to-day operations. Leveraging the topology discovery, advanced fault and performance management, and automated root cause analysis, the service assurance capabilities enable you to optimize network performance, streamline day-to-day operations, and deliver exceptional user experiences.
To learn more about the assurance and automation capabilities of VMware Telco Cloud Platform, visit the VMware Telco Cloud website.
Discover more from VMware Telco Cloud Blog
Subscribe to get the latest posts sent to your email.






