

Picture this: Your application teams pushed 30 updates last quarter. Your agents are reasoning in milliseconds. Your on-call rotation has never been quieter. And somewhere, a platform engineer is still manually configuring connection strings and writing a wall of YAML for a Postgres instance in Region X.
That last part is the problem. The application layer has gotten faster. But the service layer in many environments has not kept up. When you manage data messaging services foundation by foundation, every new region added to your estate adds a proportional slice of operational toil. You don’t notice it at first. By the time you do, that toil has quietly become a ceiling on how fast your organization can move.
The service gap hiding behind your golden path
When we announced the release of VMware Tanzu Platform 10.4, we described the goal as collapsing the distance between idea and production. One of the most direct ways we’re doing that in this release is by treating service fleet management as a first-class operational discipline, not an afterthought for platform teams to solve on their own.
With Tanzu Platform, platform engineers can now manage massive fleets of data and messaging services with centralized lifecycle operations—backup, restore, and automated updates and upgrades—directly from the Tanzu Hub interface. The practical implication: what used to require per-instance work across dozens of foundations can now be handled as a unified operational gesture. You define the policy once, and the platform enforces it.
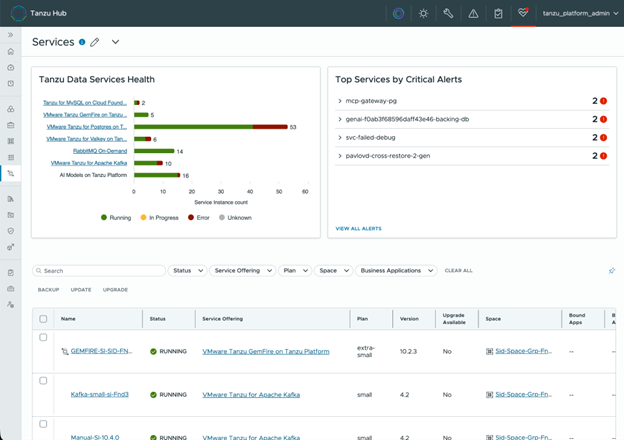
The new services dashboard in Tanzu Hub as part of Tanzu Platform 10.4 shown here enables platform teams to get a more complete view of services deployed across the fleet and manage backup, update, and upgrade operations at scale.
If you’ve been operating at three or four foundations, this might feel incremental. At 30 foundations spanning global regions, it isn’t. The difference is the contrast between a platform team that spends its time governing and one that spends its time surviving.
Services without borders: VKS joins the platform
One of the quieter but more consequential additions in the Tanzu Platform 10.4 release is the extension of Tanzu Platform’s service binding model to applications running on VMware vSphere Kubernetes Service (VKS).
Previously, if you had an application running on VKS and wanted to connect it to a database managed by Tanzu Platform, you were doing the manual plumbing: connection strings and secrets management, all handled by platform teams. That friction didn’t disappear just because you chose VKS. It just moved to a different team’s ticketing.
With Tanzu Platform 10.4, VKS-hosted applications are treated as first-class consumers of platform services. A developer can browse the Tanzu Hub marketplace, instantiate the service they need, and initiate a bind. The platform injects credentials and configuration directly into the VKS namespace, establishing a secure encrypted channel between the app and the data. No manual steps. No hand-rolled secrets. No ticket necessary. The same governed path that Tanzu Platform application teams have relied on since Day 1 is now available across the broader VMware Cloud Foundation estate.
The practical message for platform engineers: Regardless of where an application lives on your private cloud, the path to data is now the same. Discover, create, and bind.
Governing the service estate at scale
In Tanzu Platform 10.4, service management capabilities aren’t just about convenience. They’re about closing the operation gap between how organizations govern their applications and how they govern the services those applications depend on.
For application workloads, Tanzu Platform has long supported the “three R’s” of platform security—repave, repair/restage, and patching—as an automated, continuous security practice. CVE in a buildpack? The platform can force a fleetwide restage across the organization in minutes.
The same programmatic discipline now extends to the service layer. When a critical vulnerability surfaces in your database fleet, platform engineers aren’t triaging instance by instance. They’re applying updates from a centralized plane and letting the platform do the heavy lifting. The window between detection and remediation shrinks, not because the team worked faster, but because the work itself was already automated.
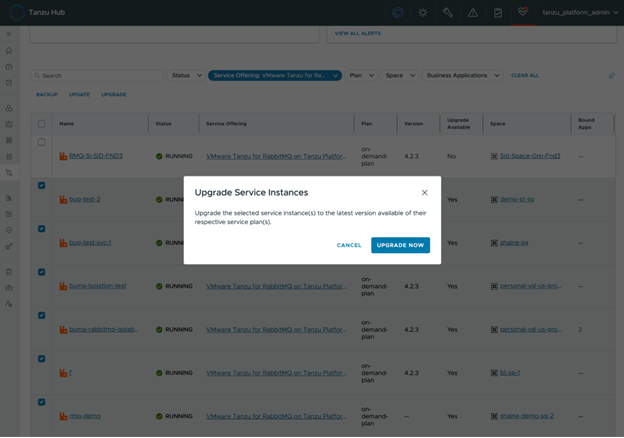
This screenshot of Tanzu Hub shows a fleet of upgrade-eligible RabbitMQ instances, with this operation to be performed at scale.
For enterprises managing AI-centric workloads alongside traditional applications, this matters in a specific way. The same rigorous governance that protects a mission-critical Postgres instance can now be applied to the high-performance caching and messaging services that agents depend on. The platform doesn’t have to distinguish between traditional and AI infrastructure; it governs the estate.
This lifecycle management is critical for AI success, as agents rely on consistent, reliable data to make accurate decisions. By automating underlying service operations, we ensure that the data layer is as dependable and performant as the models themselves.
The service layer, fully accounted for
The shift in Tanzu Platform 10.4 is ultimately about accountability. It enables teams to make sure that every part of your private cloud estate, not just the application layer, operates under the same governance standards you’ve built for the rest of your platform.
When your application can scale globally in seconds but your data services are still managed foundation by foundation, you haven’t built a platform. You’ve built a faster approximation of one. Enterprise-scale service management in Tanzu Platform 10.4 closes this gap.
To explore the full release, start with the Tanzu Platform 10.4 release notes and documentation, or visit the Tanzu Platform product page to learn more and connect with our team.






