

For the better part of a decade, the enterprise technology mantra was simple and absolute: “Cloud first.” IT leaders were incentivized to migrate everything to the public cloud. However, as the dust settles on this initial rush, a massive pendulum swing is underway. Instead of defaulting to public infrastructure, enterprises are driving a significant wave of workload repatriation directly back to the private cloud and bare-metal environments.
An article from IDC[1] mentioned that “as the cloud landscape matures, many organizations are finding that the reality of cloud adoption does not always align with their expectations. This in turn has led to a growing trend of repatriating workloads back to on-premises or private cloud environments.”
Why the sudden shift? This strategy we feel is driven by three unavoidable realities.
Unpredictable economics at scale: The variable, egress-heavy billing models of public hyperscalers have strained IT budgets. For persistent, data-heavy workloads—especially those running 24×7—the predictable, fixed-cost nature of private clouds has become highly attractive.
Strict sovereign control and compliance: With tightening global regulations (like GDPR and DORA in the EU, HIPAA in healthcare, and localized data residency laws worldwide), housing critical intellectual property and customer data on third-party multitenant infrastructure can carry immense compliance risk.
Data gravity and sovereign AI: The most valuable enterprise data, decades of transaction logs, customer behavior, and proprietary IP is already sitting on premises. As organizations rush to build agentic, generative AI and retrieval-augmented generation (RAG) applications, they are realizing a hard truth. Moving petabytes of data across the wire to the public cloud to feed an AI model is prohibitively slow, expensive, and a security non-starter.
The new enterprise mandate is clear: Stop moving data! Instead of exporting massive, sensitive datasets to external AI engines, enterprises must run their AI models directly on top of their secure data. In an era of strict regulations and intellectual property risks, establishing robust data intelligence entirely within the private cloud is less of a technical upgrade and more of a strategic necessity.
The demand for a private cloud data lakehouse
To outpace agile, modern-day competitors, enterprises need the agility, self-service capabilities, and unified governance typically associated with public cloud data platforms. But they need it executed strictly behind their own corporate firewalls.
This requires a paradigm shift toward a unified data lakehouse architecture. A private cloud lakehouse blends the massive scale, flexibility, and low-cost storage of a data lake (capable of holding unstructured text, images, and logs) with the high performance, ACID compliance, and advanced querying capabilities of a traditional data warehouse.
More importantly, it provides a unified federated layer where structured, semi-structured, and unstructured data can be queried in place, minimizing the ETL needs and eliminating the need to constantly move data around to make sense of it.
A unified data intelligence platform for the private cloud
Confronting unpredictable economics, strict compliance mandates, and data fragmentation requires a new approach and that’s where the private cloud data strategy fundamentally changes. That’s where VMware Tanzu Data Intelligence can help.
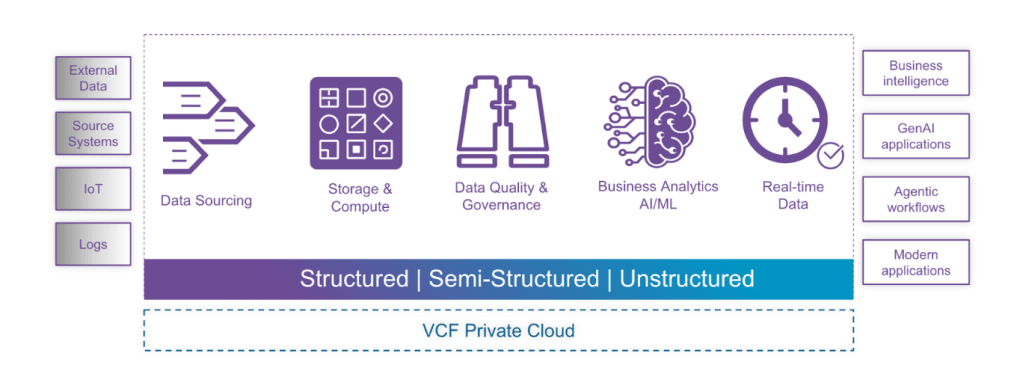
Tanzu Data Intelligence is based on a modern lakehouse architecture
Engineered to work hand in glove on VMware Cloud Foundation (VCF), Tanzu Data Intelligence seamlessly ingests and processes all types of data, whether structured, semi-structured, or unstructured. It works across operational silos by bringing together critical capabilities such as data sourcing, scalable storage, and high-performance compute, along with rigorous data quality and governance. By bridging the gap between real-time data streams and advanced business analytics and AI/ML, Tanzu Data Intelligence serves as the data engine for even the most demanding workloads. Whether you are driving traditional BI, deploying cutting-edge GenAI apps, orchestrating complex agentic workflows, or scaling fast-paced modern apps, Tanzu Data Intelligence delivers the platform required to innovate more securely.
Tanzu Data Intelligence creates the right foundational tools for a unified data intelligence platform. Here are its core components:
- VMware Tanzu Greenplum – More than just a traditional data warehouse, Tanzu Greenplum is a massively parallel processing (MPP) powerhouse. As the foundation of Tanzu Data Intelligence, it serves as the advanced analytics engine, capable of querying massive datasets and handling complex vector embeddings. Through powerful federated querying, it transforms isolated databases into a single, unified data storage. Your teams can now query data seamlessly across your existing systems without ever having to move it, creating a centralized intelligence layer over your entire fragmented estate.
- VMware Tanzu GemFire – An ultra-low-latency, in-memory data grid. In the age of AI, Tanzu GemFire acts as the high-speed feature store, serving data to machine learning models in sub-milliseconds. This extreme speed significantly improves the performance of mission-critical applications, enabling business-critical processes such as real-time credit card fraud detection to execute instantly, and helping high-throughput transactional apps keep customers waiting less.
- VMware Tanzu RabbitMQ and VMware Tanzu Data Flow – The central nervous system for data in motion. Beyond standard messaging, Tanzu RabbitMQ and Tanzu Data Flow together orchestrate complex, real-time streaming pipelines to reduce the latency between operational events and analytical insights. The moment an event occurs, be it a financial transaction or an IoT sensor spike, it is more securely, reliably, and quickly routed to analytics engines and AI models/apps for immediate action.
- VMware Tanzu for Postgres/VMware Tanzu for MySQL – The rock-solid, enterprise-hardened transactional backbone for mission-critical applications. Under Tanzu Data Intelligence, Tanzu for Postgres and Tanzu for MySQL deliver automated lifecycle management, built-in high availability, and robust disaster recovery. They handle rigorous, high-throughput operational workloads while seamlessly feeding that transactional data upstream into the broader analytical layer.
- VMware Tanzu Data Lake – The foundational, highly scalable object storage layer designed to capture an enterprise’s entire data footprint. By leveraging open table formats like Apache Iceberg and separating compute from storage, Tanzu Data Lake works across rigid data silos. It acts as the single source of truth, natively accessible by Tanzu Greenplum to train next-generation AI models without relying on fragile, complex ETL pipelines.
Tanzu Data Intelligence can provide the federated query services, security, and governance required to operate multiple data engines as a single system so organizations can make better business decisions.
Driving strategic use cases in the private cloud
When organizations unify their fragmented analytical engines under Tanzu Data Intelligence, the resulting business outcomes can be entirely transformative. For organizations balancing rapid innovation with strict compliance, this unified approach can unlock unprecedented capabilities.
With built-in compute services for vector analysis, developers can gain immediate access to the unified data required for next-generation AI use cases and applications. A financial institution, for instance, can securely feed highly sensitive trading histories into a localized LLM to generate instant market insights. Because the platform delivers public-cloud agility while maintaining total sovereign control on VMware Cloud Foundation infrastructure or bare metal, critical intellectual property remains secure with you.
This strategic agility extends directly to the transactional frontline. By combining Tanzu Data Intelligence’s powerful engines, a credit card processor can stream live transaction data, instantly cross-reference massive historical fraud patterns, and execute an authoritative approve-or-deny decision entirely in memory, all before the retail terminal registers the swipe.
Crucially, achieving this sub-millisecond execution does not require ballooning IT budgets. By rationalizing disjointed database sprawl into a single platform, organizations can realize a sizeable reduction in total cost of ownership by slashing third-party licensing costs, minimizing infrastructure overhead, and greatly reducing the administrative toil of custom ETL pipelines.
The path forward
The era of simply managing databases in the data center is over. To escape unpredictable cloud economics, the future belongs to enterprises that can harness true, unified data intelligence behind their own firewalls.
Tanzu Data Intelligence provides the architectural blueprint to modernize your private cloud and bring compute directly to your data’s center of gravity. By uniting trusted, enterprise data engines under one strategic umbrella, Tanzu Data Intelligence can break down decades of data silos and build the foundation for secure, cost-effective, and powerful AI outcomes – on your terms.
Sources:[1] IDC Blog, Storm Clouds Ahead: Missed Expectations in Cloud Computing, October 28, 2024





