

As enterprises strive to become AI-driven, one major challenge remains: the complexity of building, training, and deploying machine learning (ML) models. Traditional ML workflows require specialized data science expertise, significant time investment, and deep technical knowledge. Yet, many organizations hold vast amounts of valuable data within their databases, ready to be transformed into insights, if only the process were simpler.
Bringing machine learning closer to the data
Instead of moving data to external ML environments, modern enterprises are increasingly turning to in-database machine learning, in which the computation happens where the data lives. This approach accelerates model training, enhances security, and reduces data movement overhead. VMware Tanzu Greenplum, with its integrated analytics and AI capabilities, has been at the forefront of this evolution.
Introducing the Greenplum automated machine learning agent, gpMLBot
Enter gpMLBot, Tanzu Greenplum’s automated machine learning agent. Designed to simplify and automate the end-to-end ML lifecycle, gpMLBot enables teams to perform data processing, hyperparameter tuning, and model deployment, all within Greenplum. Acting as a “data scientist” for non-scientists, it makes advanced machine learning accessible, efficient, and seamlessly integrated into your existing data ecosystem.
Apache MADlib is an open source library for scalable in-database analytics. The Greenplum MADlib extension provides the ability to run machine learning and deep learning workloads in Tanzu Greenplum.
PostgresML is an open source Postgres extension that works with Tanzu Greenplum. Both offer deep learning and machine learning algorithms and capabilities. gpMLBot demystifies these extensions to help you leverage the most out of your data.
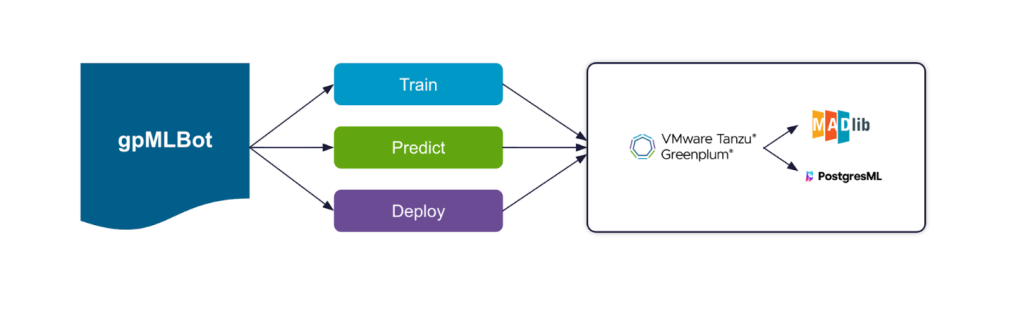
gpMLBot’s model life cycle
gpMLBot comprises three main commands or phases to walk you through the natural life cycle of machine learning models: Train, Predict, Deploy.
| Train | Predict | Deploy |
| Train a model by running multiple algorithms at once Leverage hyperparameter search to uncover the best parameters for your datasetTrain using classification or regression algorithmsRank algorithms based on accuracy and precisionSave the best algorithm as a trained model | Test and verify the model against a new dataset Use the trained model to predict forecasted values | Deploy a trained model to a production data pipelineTrained models can be exported to:Tanzu GreenplumTanzu for PostgresFuture export modes may include:Java applications (e.g., Gemfire)Python applications |
In-database analysis: Stop moving data and start moving forward
- Zero data movement – Work with your data where it already lives, and train models directly inside the database.
- The ability to use what you know – Your existing SQL skills are all you need to build and deploy advanced machine learning models.
- Real-time insights – Train and predict on fresh data to gain real-time insights, avoiding stale data.
- Instant deployments – Skip complex ETL pipelines, saving you time and resources.
- Strong security – Tanzu Greenplum is built on PostgreSQL’s trusted security, proven ACID compliance, and concurrent access controls.
Automated model tuning: Expert-level optimization on autopilot
- Hyperparameter search – This pinpoints the optimal settings for your unique data and goals by automatically sweeping through multiple parameters for each algorithm. Built-in hyperparameter search for critical parameters like n_estimators, learning_rate, and max_depth.
- Automatic tuning – Automatically tune a model’s accuracy, precision, and performance.
- Set-it-and-forget-it capability – No manual tweaking required.
- Shortened time requirements from weeks to hours: What takes a specialized data scientist weeks automatically turns into just hours.
Analyze multiple algorithms and datasets at once: Optimal results without the guesswork
- Automated algorithm selection – Let the database automatically find the perfect algorithm for your data. No trial and error.
- Parallel processing – Speed things up by simultaneously running multiple algorithms in-parallel, including xgboost, decision tree, random forest, and many more.
- Multi-dataset analysis – Easily analyze and compare multiple datasets at once to uncover hidden correlations and opportunities. Easily scale your analysis.
Example use case: Real-time credit card fraud detection
Financial institutions process millions of transactions every day, and each one carries the potential for fraud. Traditional fraud detection systems often rely on static rules or legacy models that struggle to adapt to new fraud patterns. Building and maintaining advanced, real-time detection models typically demands skilled data scientists, complex infrastructure, and long development cycles.
With gpMLBot, this process becomes dramatically simpler. The automated machine learning agent in VMware Tanzu Greenplum can automatically build, train, and optimize a machine learning model to detect fraudulent credit card transactions in real time. You can see a detailed video here:
Dataset
Load a sample dataset with two days of credit card transactions containing about 500 fraudulent transactions out of 280,000. Due to confidentiality, the features or input variables have been transformed into V1, V2,…V28, which could be things like merchant, purchase_category, purchase_date, location, etc. The column “is_fraud” is a Boolean indicating whether the transaction was fraudulent or not.
Train
To train a model to detect fraudulent transactions, select the database and table containing the training dataset. Next, select the id column, the “is_fraud” column to predict on, and the feature columns V1, V2,…V28. gpMLBot will automatically identify and remove correlated features to simplify and speed up the algorithms. The below screenshot shows how we went from an input of V1…V28 features to just 15, eliminating the correlated columns.
Next, choose which type of algorithms to run — classification or regression. Classification algorithms are used to predict Boolean or categorical values, and regression algorithms predict numerical values. Since the prediction column “is_fraud” is a Boolean, we run the classification algorithms. We can then choose which MADlib or PostgresML algorithms to run or use the default to run them all at once.
Finding an algorithm’s optimal parameters maximizes performance, improves the model’s generalization, increases its predictive accuracy, and reduces computational costs. We are given the option to run the PostgresML algorithms with hyperparameters or the default parameters. Hyperparameter search finds the best configuration parameter for tuning a model. For example, we can run postgresml lightgbm with the default hyperparameters { “num_leaves”: [20, 31, 50, 100, 150] }. This runs lightgbm with the list of num_leaves hyperparameters to find the optimal parameter. Full hyperparameter customization can be done using the gpMLBot configuration file.
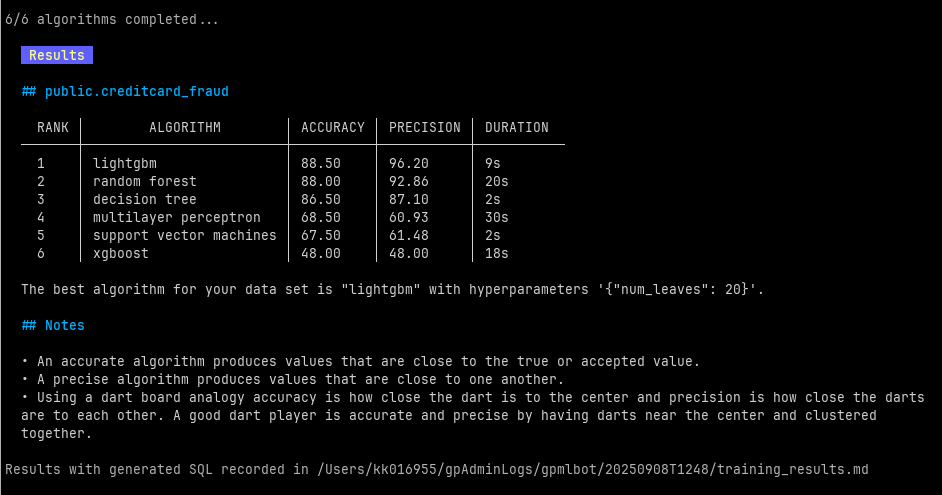
The training results rank the algorithms’ accuracy and precision and saves the best algorithm as our trained model. The best hyperparameter for our run was postgresml lightgbm with ‘{“num_leaves”: 20}’.
Predict
Predict helps verify and test the trained model before deploying. We run predict on a new dataset to forecast new “is_fraud” values and ensure the model is catching fraudulent credit card transactions as expected.
Deploy
Deploy exports a trained model for use in production environments. Exporting as SQL allows the deployed model to be imported into a production Greenplum or PostgreSQL server consuming realtime streaming credit card transaction data.
Planned for the future is the ability to export as PMML, an XML-based model interchange format. This would allow models to be easily imported into Python and Java services, such as Gemfire.
The Greenplum automated machine learning agent (gpMLBot) simplifies and automates the end-to-end machine learning life cycle within the VMware Tanzu Greenplum ecosystem. By handling tasks such as data preparation, model training, hyperparameter optimization, and deployment, it empowers users without deep data science expertise to build and operationalize machine learning models efficiently. gpMLBot represents a major step toward democratizing AI and enabling faster, more intelligent decision-making directly where enterprise data resides.
By combining Tanzu Greenplum’s powerful analytics engine with Tanzu Data Lake, enterprises can establish a unified data lakehouse that supports both structured and unstructured data at scale. This lakehouse architecture forms the core of Tanzu Data Intelligence, and the ecosystem transforms raw enterprise data into AI-ready intelligence, accelerating insights, improving decision-making, and enabling organizations to operationalize AI with confidence.
Learn more about Tanzu Data Intelligence in this blog. If you have any other questions, please reach out to us.





