

In today’s data driven world, scalable and flexible data infrastructure holds prior importance. Greenplum being a powerful and analytical MPP database has become a popular choice when it comes to large scale data processing. In the contemporary data-driven landscape, the establishment of scalable and flexible data infrastructure is of paramount importance. Greenplum, recognized as a robust and analytical Massively Parallel Processing (MPP) database, has emerged as a favored option for the processing of large-scale data.
Currently, the installation and operation of a Greenplum cluster mandate the creation of multiple virtual machines, each pre-loaded with the necessary Greenplum prerequisites and configurations. This results in a longer turnaround time for deploying a usable Greenplum Cluster. Furthermore, there is no established method for users to provision a Greenplum Cluster on an existing Kubernetes cluster. The Greenplum Operator for Kubernetes addresses this issue by enabling users to provision and utilize Greenplum features with significantly reduced turnaround time and resource consumption. This makes users focus more on the Greenplum functionalities and worry less about the cluster management.
Along with addressing this major use case, the greenplum operator for kubernetes comes up with the following features:
- Lifecycle management management of clusters
- Inbuilt h3 and postgis extension support
- Support over variety of Kubernetes platforms (even over minikube)
- Minimal resource requirements
- Backup and Restore
- GPCC for monitoring the provisioned Greenplum Cluster
- Autorecovery of pods in case of failures
Why Greenplum On Kubernetes?
More Speed Less Turn Around Time
The deployment time for Greenplum Clusters has been significantly reduced. This automated process ensures error-free provisioning of clusters, which is particularly beneficial for short-lived projects, Proof of Concepts (POCs), and experimental endeavors. Teams are now empowered with the capability to launch greenplum cluster environments rapidly, whether for prototypes or larger workloads.
Optimal Resource Consumption
The Greenplum on Kubernetes offers significant advantages for data management and analytics. This integration empowers users to deploy new Greenplum clusters with remarkable efficiency, requiring only minimal resource allocation. This is particularly beneficial for organizations looking to scale their data warehousing capabilities on demand without incurring substantial upfront infrastructure costs.
Beyond new deployments, a key strength of this synergy lies in its ability to leverage existing Kubernetes environments for Greenplum Database (GPDB) provisioning. This optimizes resource utilization by allowing GPDB instances to share the underlying infrastructure with other applications and services already running within Kubernetes. The result is a substantial reduction in hardware and operational requirements, leading to cost savings and improved environmental sustainability.
Security and Segregation
The advent of Kubernetes introduces enhanced Role-Based Access Control (RBAC), enabling diverse deployments within a single cluster through distinct namespaces. The implementation of robust access controls mitigates the “blast radius” of security incidents, thereby streamlining compliance by establishing clearly defined and auditable environments. Extensive Kubernetes features such as Security Context, Node Affinity, and Pod Antiaffinity can facilitate the implementation of best practices during Greenplum deployment.
Stability
In Kubernetes-based Greenplum environments, stability extends far beyond simple uptime. The platform ensures complete automated recovery, as failed pods are seamlessly restarted and reattached to their existing persistent volumes—eliminating manual intervention and preserving data integrity. Resources can be pre-allocated, so Greenplum always operates with the compute and memory necessary for peak analytics performance, guaranteeing there’s no degradation even as workloads scale. The use of robust, predefined upgrade and patching procedures further enhances platform reliability, ensuring that improvements or security fixes are applied safely and predictably.
Scalability
Depending on the cluster’s requirements, allocated resources can be scaled to ensure uptime and automated expansion, as deploying pods in stateful sets performs rolling updates. The segregation of compute and storage is highly beneficial in ensuring that pods are scaled only as required, depending on performance or data volume.
Get Started
Architecture Overview
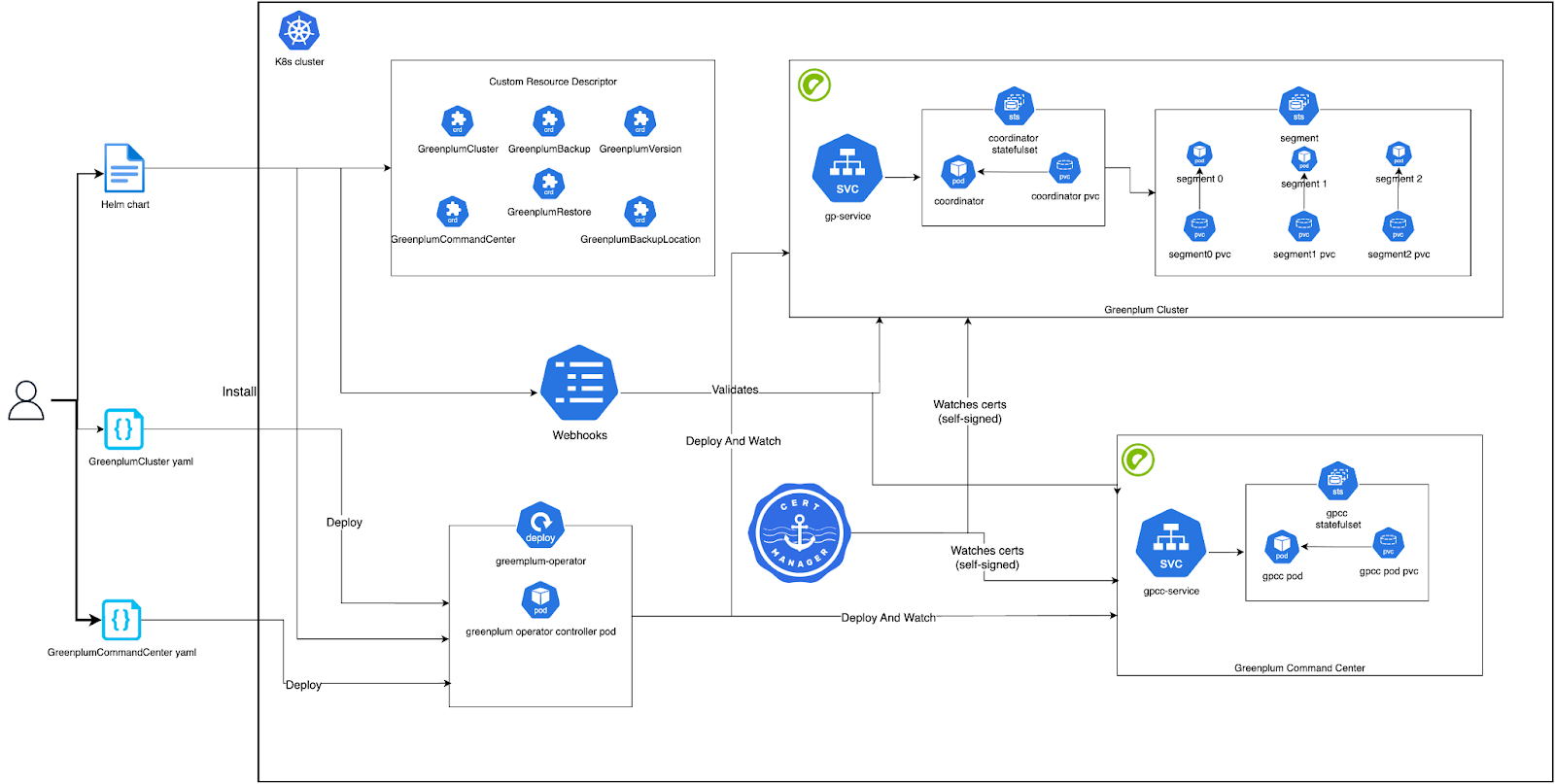
Key Architectural Components:
- Greenplum Operator: Greenplum operator is the key controller which is responsible for managing the Greenplum cluster on Kubernetes, including deployment, lifecycle management, etc. It interacts with Kubernetes resources to configure and manage the cluster.
- Greenplum Cluster: This is a fully provisioned and manageable GPDB cluster over kubernetes represented by a GreenplumCluster Custom Resource(CR). The CR is a combination of coordinator and segment deployments along with an exposing service to interact with the cluster.
- Greenplum Version: This is a Custom Resource which defines the GPDB version and its image details. This is used in the GreenplumCluster CR to define the GPDB Cluster Version.
- Greenplum Command Center: This is a Custom Resource which will provision a Greenplum Command Center Instance associated with a Greenplum Cluster
- Cert Manager: It is required and used for watching self signed certs used by the operator and webhooks
- Webhooks: These are deployed to validate the gp-operator provisioned resources like greenplumclusters, greenplumcommandcenters, etc.
Working
- User first installs cert-manager if not present. This watches over self signed certificates and webhooks used by the operator.
- Upon the installation of cert-manager, the user proceeds to deploy the GP operator helm chart. Helm chart consists of various CRDs and deployment of the operator.
- Upon the deployment of the operator, the user subsequently creates the Greenplum version resource, which encapsulates details regarding the Greenplum and Command Center instances slated for provisioning.
- Once the greenplum version is created, users then create greenplum cluster and greenplum command center resources based on their requirements which are then validated by webhooks.
- The operator creates the required resources and spins up the clusters. Operator also watches and reconciles the failed instances and brings them to appropriate state
- Upon cluster activation, users can access it through the pods or services deployed as a part of the cluster.
Create your own Greenplum Cluster
The deployment of Greenplum Clusters on Kubernetes has been significantly simplified with the introduction of the operator. Users can provision GPDB clusters from the following minimal steps:
A step by step detailed video for the provisioning of GPDB cluster is mentioned in this video. Greenplum On Kubernetes Demo
- Install the helm chart
# Install cert manager (if not installed already). Sample
kubectl apply -f
https://github.com/cert-manager/cert-manager/releases/download/v1.18.2/cert-manager.yaml
# Download the helm chart and install the operator
# Login to the helm registry and pull the chart. Example
helm registry login <URL> -u ${USER} -p ${PASSWORD}
helm pull oci://<CHART_PATH>/gp-operator --version 1.0.0
# Untar the chart and change the directory
tar -xvzf gp-operator-1.0.0.tgz
cd gp-operator
# Edit the secret in values.yaml file
imagePullSecrets:
- name: <YOUR_SECRET_NAME>
# Make sure you are in the gp-operator directory
helm install gp-operator . -n ${NAMESPACE}- Create Greenplum Version using greenplumversion custom resource. This will provide the details needed to provision a greenplum cluster. Sample file for the greenplumversion is shown below
# Sample for Greenplum Version 7.5.2
# vi gpversion7.5.2.yaml
apiVersion: greenplum.data.tanzu.vmware.com/v1
kind: GreenplumVersion
metadata:
labels:
app.kubernetes.io/name: gp-operator
app.kubernetes.io/managed-by: kustomize
name: greenplumversion-7.5.2
spec:
dbVersion: 7.5.2
image: repository.example.com/greenplum/gp-operator/gp-instance:7.5.2
operatorVersion: 1.0.0
extensions:
- name: postgis
version: 3.3.2
- name: greenplum_backup_restore
version: 1.31.0
gpcc:
version: 7.5.0
image: repository.example.com/greenplum/gp-operator/gp-command-center:7.5.0
# Create greenplum version
kubectl apply -f gpversion7.5.2.yaml - Once the greenplumversions are created, we can create greenplumclusters. Sample file to create greenplumcluster is shown below.
# vi gp-minimal.yaml
apiVersion: greenplum.data.tanzu.vmware.com/v1
kind: GreenplumCluster
metadata:
labels:
app.kubernetes.io/name: greenplum-cluster-operator
app.kubernetes.io/component: greenplum-operator
app.kubernetes.io/part-of: gp-operator
name: gp-minimal
spec:
version: greenplumversion-7.4.1
imagePullSecrets:
- mds-gar-secret # optional
coordinator:
storageClassName: standard
service:
type: NodePort
storage: 1Gi
global:
gucSettings:
- key: wal_level
value: logical
segments:
count: 1
storageClassName: standard # Update this to use your storageClass
storage: 10Gi # Storage per segment
# Create greenplum cluster
kubectl apply -f gp-minimal.yaml
# Check greenplum cluster status
kubectl get greenplumclusters
# OR
kubectl get gp
NAME STATUS AGE
gp-minimal Running 3d20h- Once the Greenplum Cluster is deployed you can also deploy Greenplum Command Center as a monitoring tool for this cluster. Sample for GPCC deployment is shown below
# vi gpcc-minimal.yaml
apiVersion: greenplum.data.tanzu.vmware.com/v1
kind: GreenplumCommandCenter
metadata:
labels:
app.kubernetes.io/name: gp-operator
app.kubernetes.io/managed-by: kustomize
name: gpcc
spec:
storageClassName: standard
greenplumClusterName: gp-minimal
storage: "2Gi"
# Create your Greenplum Command Center Instance
kubectl apply -f gpcc-minimal.yaml -n <NAMESPACE>
# Check GPCC Status
kubectl get gpccAccessing GPDB and GPCC Clusters
Accessing Greenplum Cluster
We can access the greenplum cluster in one of the following ways
- If greenplum service is provisioned with serviceType as LoadBalancer, then we can directly access it using the LoadBalancerIP. This is the recommended approach.
- We can port-forward greenplum-coordinator pod and access it locally using psql or any other client
- We can port-forward greenplum svc and access it locally using psql or any other client.
This approach can be used for demo and local testing. - We can exec into greenplum-coordinator pod and access it locally using psql or any other client
Once the cluster is accessible you can use psql to perform DB Operations or any other tool.
You can get the cluster credentials by following the below step:
# make sure tha the cluster is in RUNNING state
kubectl get gp -n ${NAMESPACE}
# kubectl get gp -n gpdb
# NAME STATUS AGE
# gp-minimal Running 3d20h
# Fetch User Password
# Fetch User Credential Secret of gp
kubectl get secret -n ${NAMESPACE} GP_INSTANCE_NAME-creds -o yaml
# Example
kubectl get secret -n ${NAMESPACE} gp-minimal-creds -o yaml
# Sample Data
# you will get gpadmin as key and base64 encoded password as value
gpadmin:QWRtaW4xMjMK
# Take the value and perform base64 decode to get the user password
echo 'QWRtaW4xMjMK' | base64 -d
# Port forward greenplum svc
kubectl port-forward -n ${NAMESPACE} svc/<CLUSTER_NAME>-svc 8080:5432
# Port forward greenplum coordinator pod
kubectl port-forward -n ${NAMESPACE} pod/<CLUSTER_NAME>-coordinator-0 8080:5432
# Exec into greenplum coordinator pod
kubectl exec -it <CLUSTER_NAME>-coordinator-0 -n ${NAMESPACE} --/bin/bash
# Use psql to connect to the instance
# Sample
psql -U gpadmin -d postgres -H HOSTNAME -p PORT -w PASSWORD
# When you Port forward greenplum svc
psql -U gpadmin -d postgres -H localhost -p 8080 -w PASSWORDAccessing GPCC Instance
There are many ways to access the provisioned GPCC:
- If the service is provisioned using the LoadBalancer service type, we can directly hit the LoadBalancer IP to access the instance.
- Port forward the GPCC pod
- Port forward the GPCC service
# Sample Port forward GPCC pod
kubectl port-forward pod/gpcc-cc-app-0 -n ${NAMESPACE} 8080:8080
# Sample Port forward GPCC service
kubectl port-forward svc/gpcc-cc-svc -n ${NAMESPACE} 8080:8080Fetching Username and Password for GPCC
Once we are able to access the GPCC instance, we would be required to perform login on that instance. While deploying GPCC, we create a user ‘gpmon’ for performing GPCC related operations on DB and to use GPCC. To fetch the username and password perform the following:
# Fetch User Credential Secret of gpcc
kubectl get secret -n ${NAMESPACE} GPCC_INSTANCE_NAME-cc-creds -o yaml
# Example
kubectl get secret -n ${NAMESPACE} gpcc-cc-creds -o yaml
# Sample Data
# you will get gpmon as key and base64 encoded password as value
gpmon:QWRtaW4xMjMK
# Take the value and perform base64 decode to get the user password
echo 'QWRtaW4xMjMK' | base64 -d
# To change the user password, edit the secret and change the value of gpmon key
# note that value should be in base64 encoded format
# gpmon password will be altered in DB too
kubectl edit secret -n ${NAMESPACE} gpcc-cc-creds
# Sample
gpmon:QWRtaW4xMjM0NQo=Use Cases
Customer Onboarding
A significant challenge encountered during Greenplum customer onboarding is the initial learning curve, along with the requisite configurations and operations, that must be completed before the full features and capabilities of Greenplum can be leveraged. This extended setup period can prolong the database evaluation process, thereby increasing the time required for customer onboarding, particularly for those migrating from alternative database systems.
The integration of Greenplum on Kubernetes significantly reduces this timeframe, providing customers with access to Greenplum through a minimal set of steps and limited prerequisites, thereby facilitating a smooth and hassle-free onboarding process. For individuals demonstrating Greenplum features, deployment is achievable even on a local system utilizing a minikube cluster. This capability is a crucial step in customer onboarding and for field personnel, as it enables minimal and streamlined deployments.
Agile Development and Testing Environments
The advent of Greenplum on Kubernetes facilitates data teams in expeditiously establishing isolated Greenplum clusters, meticulously configured for developmental, testing, and proof-of-concept initiatives. This functionality guarantees that each team can operate within a pristine, standardized environment on demand, thereby accelerating innovation cycles and mitigating the potential for disruptions to production systems.
CICD Workload And Automation
For users seeking to deploy a Greenplum Database (GPDB) cluster for testing and analytical endeavors, and to leverage Greenplum within their operational pipelines, the implementation of Greenplum on Kubernetes offers substantial advantages in deployment. This approach also mitigates the risks associated with manual lifecycle operations, thereby enhancing system stability.
Strong Isolation on Clusters on Minimal Resource
With the enforcement of best Kubernetes practices and the GP on Kubernetes introduction, we can leverage a single kubernetes cluster to run different kinds of Greenplum instances isolated from each other. We can organize Greenplum instances into various namespaces and can enforce things like resource quota to ensure optimal resource utilization and segregation.







