
Greenplum Upgrade (gpupgrade) is a utility that allows in-place upgrades from Greenplum Database (GPDB) 5.x version to 6.x version. Version 1.7.0 boasts a significant performance improvement compared to earlier releases. These resulted from several key optimizations that were implemented while performance testing on large reference databases.
In this article we provide an overview of the methods used to obtain this performance increase using a reference database.
Cluster Stats
The size of the cluster metadata totaled near 200GB and contained the following objects:
| Type | Count |
|---|---|
| AO Tables | 263,059 |
| Heap Tables | 329,640 |
| Indexes | 592,731 |
| Views | 9,125 |
Upgrade duration comparison
| Step | 1.6.0 | 1.7.0 | Speedup |
|---|---|---|---|
| Initialize | 13h30m | 1h30m | 8.66x |
| Execute | 58h | 27h | 2.15x |
| Finalize | 96h | 1h | 96x |
| Total | 168h | 30h | 5.6x |
Result
Originally it took 168 hours to upgrade the cluster from GPDB5 to GPDB6. After various optimizations were applied it took under 30 hours, an improvement of over 5x. Ongoing performance improvements are expected to further increase performance.
Performance Improvements
Upgrade AO auxilliary tables in pg_upgrade using copy/link relfilenode transfer
AO and AOCO tables rely on auxilliary tables (aux) to function correctly. AO aux tables (pg_aoseg, pg_aovisimap, pg_aoblkdir) were upgraded by logically copying the tables from the source to the target cluster. This involved querying each of these tables in the old cluster, then manually rebuilding the tables on the new cluster using TRUNCATES and INSERTS. It was originally done this way because on-disk changes in these tables between GPDB4 and GPDB5 prevented direct relfilenode transfer because they were incompatible. There were no on-disk changes for aux tables from GPDB5 to GPDB6. Now, gpupgrade saves a significant amount of time by upgrading them like any other user table via copy or link mode, whichever was specified by the user.
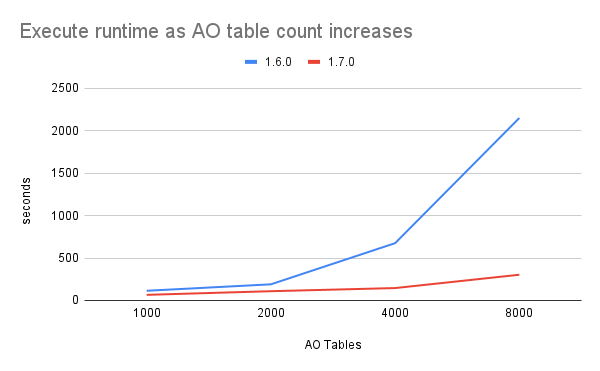
This change represents a significant speedup in the execute step and continues to scale well as AO table count increases.
Generate data migration scripts in parallel
As new major versions of GPDB are released, some objects may be deprecated or removed. Schemas containing deprecated or removed objects can’t be upgraded across major versions. Partition tables are a prime example of this. Partitions tables still exist from GPDB5 to GPDB6, but there are now more restrictions on them to prevent states such as child partition tables with dropped columns or incorrect constraints. To help users upgrade their data, gpupgrade has a number of data migration scripts that will automatically convert or fix objects so they are in compliance with restrictions on the new cluster. All data migration scripts for all databases are generated concurrently in parallel. To speed up gpupgrade initalize step, the number of threads running in parallel is the number of databases times the number of data migrations scripts to be generated.
Parallelize pre upgrade checks
Before an upgrade is attempted there are a series of checks performed to help ensure the upgrade will succeed. These checks are run on the coordinator and some can take up to 2 hours each. These checks were being done sequentially on the coordinator and then again sequentially on the segments. We made changes so that these checks run in parallel and only runs on the coordinator. Now the checks are bottlenecked by the slowest individual check. Running the checks on the segments was also wasted time since if the checks pass on coordinator they would also pass on segments. This makes it so that only the slowest check bottlenecks the initialize step.
Dump and restore database schemas in parallel
gpupgrade leverages pg_dump to dump schemas from the source cluster and restore them on the target. The pg_dump --jobs flag was disabled during upgrade because it was not supported. Work was done to enable the --jobs flag to dump databases in parallel. This allows pg_upgrade to leverage more of the available CPU resources by dumping and restoring databases in parallel. This can significantly increase upgrade time if there are a lot of databases to be dumped and improves performance of the execute step.
Lock all tables to be dumped in a single statement.
Prior to dumping the database schemas, pg_dump must obtain a lock on every table that will be dumped. Previously, these locks were acquired one at a time by issuing a LOCK statement for each table. Now we acquire all the locks in a single statement, eliminating the repeated query overhead and essentially turning the lock table step into a constant time operation.
Refactor pg_dump metadata queries required for binary upgrade
Upgrades require us to preassign the OIDs of tables, indexes, and types so that they match in the old and new clusters. Previously, pg_dump executed multiple queries for each object to gather the necessary info to record in the pg_dump archive file. Now, we gather all of the info required up front in a single query and use hash table lookups on the gpupgrade side to set and dump the correct OIDs.
Previously, a database with 100,000 AO tables could result in pg_dump executing well over 1 million queries just to gather the required metadata from the old cluster. We have eliminated those queries and the resulting communication overhead. These changes result in a significant performance improvement in all cases, but particularly when handling AO tables.
A pg_dump of the regression database shows a performance increase of over 20x and continues to scale well as object count increases.
Before:
time pg_dump --schema-only --quote-all-identifiers -s regression --binary-upgrade
0.82s user 0.21s system 1% cpu 1:27.17 totalAfter:
time pg_dump --schema-only --quote-all-identifiers -s regression --binary-upgrade
0.43s user 0.06s system 12% cpu 3.966 totalSet next free OID before restoring database schemas during execute
When creating new objects on the target cluster via pg_restore, objects that do not have a preassigned OID will try to get a new OID from the OID counter. This works in upstream Postgres but can be slow in GPDB because the new OID is checked against a reserved OID list. If a generated OID is in the reserved list, a new OID is generated until an unreserved oid is found.
The logic for this can be found in GetNewOid, where we see oids being constantly generated. The oid is then checked against all reserved oids.
Oid
GetNewOid(Relation relation) {
...
do {
newOid = GetNewOidWithIndex(relation, oidIndex, ObjectIdAttributeNumber);
} while(!IsOidAcceptable(newOid));
...
}Since GPDB requires oids of relations to be consistent across segments, in production scenarios, it would be very common to have a very, very large reserved oid list that is as large as the number of relations in the database. Starting the OID counter from FirstNormalObjectId (16384) would make object creation slower than usual near the beginning of pg_restore due to traversing the reserved oid list. To prevent pg_restore performance degradation from so many invalid OIDs produced by the counter, bump the counter to the next free OID from the source cluster using pg_resetxlog. This can significantly reduce the time required to restore a database schema in the target cluster.
Avoid generation of new Free Space Maps (FSM) during finalize
The gpupgrade finalize step was executing the analyze_new_cluster.sh script that was being output by pg_upgrade to regenerate stats. This script contained a vacuumdb call that would vacuum the entire database. As a result, new Free Space Maps (FSM) were created for each table because FSM’s do not exist on GPDB5. This was an enormously expensive operation requiring heavy disk I/O and essentially extended the cluster downtime by many hours. While FSM’s are great for optimizing disk space usage, in the end it is an optimization. Avoiding the FSM generation will still result in a functional cluster and provides flexibility to the user. Now gpupgrade will simply call vacuumdb --all --analyze-only to regenerate stats. Since users are expected to regularly vacuum their tables as part of standard cluster maintenance, FSM’s will be regenerated as those tables are vacuumed. By skipping FSM generation, finalize now only runs in 1 hour as opposed to the 96 hours by including this step.
Future optimization work
Upgrading coordinator and segments in parallel in GPDB6+ source clusters
There is potential here to speed up upgrade since segments cannot be directly upgraded due to the lack of partition table schema info on the segments. Currently GPDB cluster upgrade is done by upgrading the coordinator and then copying the coordinator data directory to segments, truncating the tables then restoring data to segments. If the coordinators and the segments can be upgraded independently, segments will not have to wait for the coordinator to upgrade before starting their own upgrade.
Uncovering more bottlenecks
There is still significant room for improvement when inspecting the upgrade process at a more granular level, from increasing parallelism to reducing redundancies and tuning queries. With ongoing testing using real-world database schemas we are continuing to tune gpupgrade and improve performance.






