




As targeting data centers, which mainly run workloads on Linux, has proven to be a very lucrative target for cyber criminals, Linux malware has become increasingly prevalent. Although still an emerging threat that’s somewhat less complex than its Windows counterpart, analysis of Linux malware remains challenging due to lack of analysis tools in the Linux world.
Luckily, both the Linux kernel and the Linux ecosystem provide a set of capabilities and tools that, when combined, potentially allow for the creation of malware analysis frameworks as powerful as those available on Windows.
This blog details what can be achieved by leveraging tools and an analysis pipeline specifically tailored for Linux, and introduces our Distributed Analysis for Research and Threat Hunting
(DARTH) framework. We provide a high-level overview of the framework, including core components and modules, as well as the design requirements that have led our research efforts in this area. We then discuss Tracer, a dynamic analysis module used in DARTH to collect various behaviors during malware execution in a controlled environment.
High Level Overview: Where DARTH Began
As part of our research, we often find ourselves running new types of analysis on large collections of malicious samples; building a scalable and easy to extend infrastructure is therefore a functional requirement. We decided to adopt (and extend) an analysis framework developed by researchers from Eurecom. Research software provides reference implementations of novel approaches to security, but, at the same time, it is notorious for its lack of support, lack of documentation, and general fragility.
The DARTH Framework
The first challenge was to redesign the infrastructure to allow analysis modules to scale as necessary. To achieve this goal, we split the framework into four different logical components so that each could run as a different Docker container:
- Commander: Interface where the user can submit samples and decide which analyses must be performed, and where the user can see the results of previous analyses.
- Scheduler: Responsible for scheduling worker tasks. It is also responsible for copying the sample to the chosen worker and returning the result to the commander once the analysis is complete.
- Worker: Responsible for the analysis of the sample.
- Database: Stores the samples’ metadata and the results of the various analyses.
These components are further orchestrated using Docker swarm.
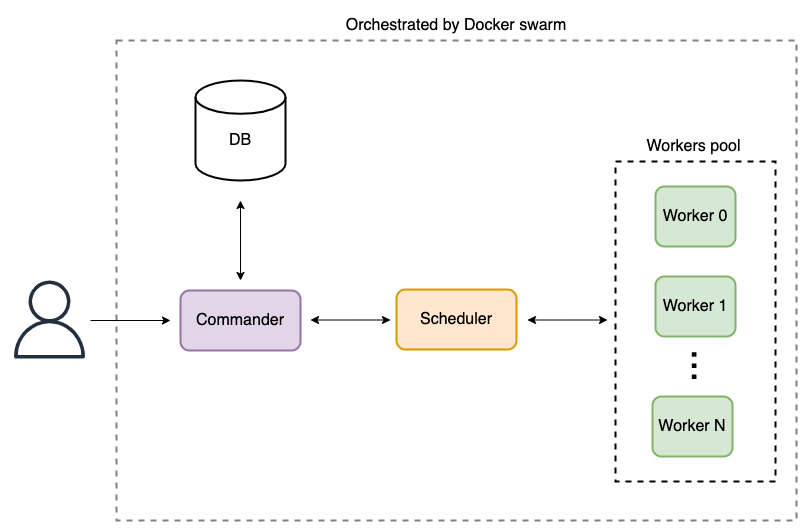
Without further modifications, this pipeline would have been suitable for running analyses in which malware does not need to be executed (i.e., static analysis), but not ideal otherwise i.e., when, as in this case, dynamic analysis must be performed and the sample must be executed in a sandbox environment. This is a direct consequence of using Docker containers as our workers, since containers are well-suited to isolate resources and reproduce a particular environment, but they do not guarantee the same security level provided by virtual machines.
Although one possible way to resolve this issue would be to use virtual machines directly when executing a dynamic analysis, this solution presents several scalability problems. In a scenario in which a fixed number of virtual machines is deployed, restoring to a clean state each time the analysis terminates leads to substantial overhead in terms of analysis time. Moreover, the only way to scale this solution is to create a new virtual machine manually. Another option that provides better scalability would be to delegate to the worker the ability to create and delete virtual machines as needed, but unfortunately that would also lead to even greater overhead.
The best-case scenario would then be having a system that is fast, easy to manage, and as easy to scale as containers, but which included the same security guarantees as VMs. After some research, we found our candidate: Amazon’s Firecracker micro-vm.
Quoting the tool’s website, “Firecracker is an open-source virtualization technology that is purpose-built for creating and managing secure, multi-tenant container and function-based services.” Thanks to the fast-booting time of micro-vms, we were able to delegate the creation and destruction of the analysis environment to the workers with minimal overhead. This also fixes the scalability issue, because the orchestrator automatically deploys more workers, and, since workers themselves are responsible for creating micro-vms, this automatically results in having more of them.
A Look at the Analysis Modules
The final piece of the puzzle was to implement the various analysis modules (and port the pre-existing one to the new framework). At the time of writing, the following modules had been implemented (including within parentheses the open-source tools used by each module):
- Bytes stats: Computes entropy, bytes distributions, and other bytes statistics.
- Code explorer: Explores the binary being examined to extract functions, code complexity, basic blocks, and other code metrics (nucleus).
- Data explorer: Explores data to extract meaningful information such as paths, URLs, domains, and IP addresses.
- Diaphora: Generates Diaphora metadata for binary diffing analysis (diaphora).
- ELF: Parses and examines an ELF file (pyelftools, gdb).
- File type: Performs file type recognition (python-magic).
- Hash: Computes various hash signatures (hashlib, python-ssdeep).
- Tracer: Extracts various behaviors dynamically using eBPF (Tracee, eBPF, pwntools).
- Unpacker: Detects binaries that may be packed and automatically unpacks UPX-packed samples (pyelftools, unicorn).
- VirusTotal: Queries VirusTotal and parses the report (vt-py).
Each of the modules can be configured with various options. Moreover, a variety of execution hooks can be specified to further specialize the analysis for a particular sample or a particular malware family. For example, the hook that runs before the analysis starts (pre-execution hook) can be used to install a particular library needed by the sample inside the micro-vm.
Deep Dive: Tracer module
The most powerful module we have developed so far is Tracer. This module leverages the Tracee tool developed by Aqua Security, which uses Linux eBPF to collect dynamic events such as executed system calls, file operations, and network activities. In a nutshell, eBPF is a technology directly integrated into the Linux kernel that allows one to implement programs to extend the capability of the kernel (specifically, in our use case, execution observability).
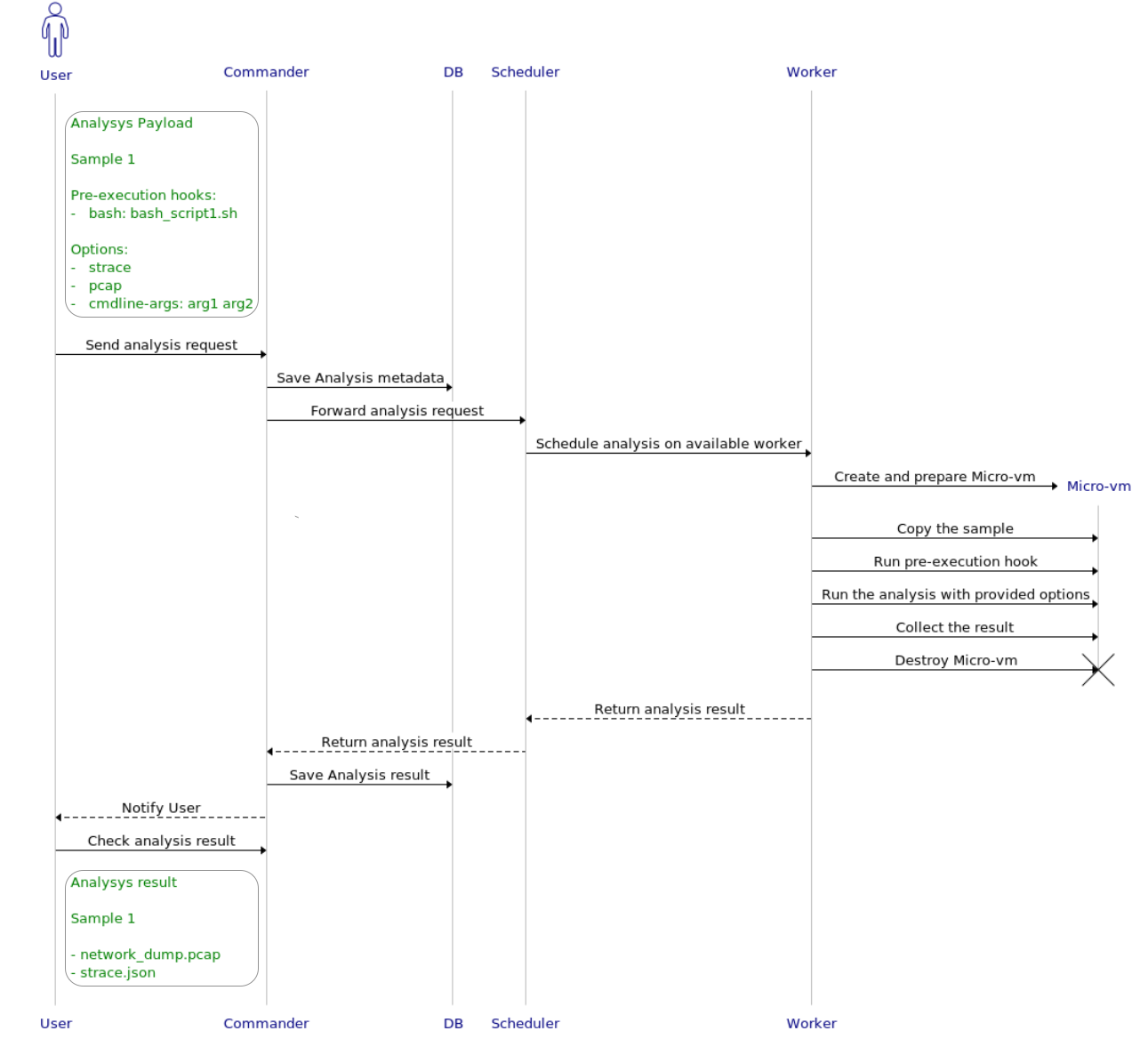
As discussed in the previous section, since this is a dynamic analysis module the workers need to setup a controlled sandbox environment to execute malware. This is done by performing the following steps:
- Create a Firecracker micro-vm using a custom image with Tracee pre-installed;
- Copy the sample inside the micro-vm;
- Run the pre-execution hook, if any;
- Run the analysis with the provided options;
- Run the post-execution hook, if any;
- Delete the micro-vm;
- Return the result to the scheduler.
The module allows for specifying the following pre-execution hooks:
- Bash: Allows the user to submit a Bash script that can be run inside the micro-vm.
- Ansible: Allows the user to submit an Ansible playbook that can be run inside the micro-vm.
with the following options:
- Pcap: Tell Tracee to install the eBPF program to capture network activities.
- Strace: Tell Tracee to install the eBPF program to capture the execution of any kind of system call.
- Fileless: Tell Tracee to install the eBPF program to detect fileless executions during the analysis and, if any, dump the executed memory regions.
- Unpacker: Tell Tracee to install the eBPF program to detect possible unpacked code during the analysis and, if any, create a memory dump of the unpacked sample.
- Heuristics: Tell Tracee to post-process the extracted data and extract high-level behavior via a series of heuristics.
- Cmdline-args: Pass specified arguments to the sample as command line arguments during execution.
- Timeout: Set the maximum time that the analysis is allowed to run.
Having the capability to pass command line arguments and invoke scripts before execution is crucial to performing a meaningful analysis. For example, a sample might only run correctly if a particular library is installed, or if a particular command line argument is specified.
After the analysis terminates, or the timeout expires, the worker collects the results in two different formats: a list of JSON files that store various registered events in given analysis categories (e.g., a list of executed system calls), and an archive ZIP file which contains a series of collected artifacts (e.g., network dumps, memory dumps, etc.). The results are then finally returned to the scheduler and stored in the database.
Conclusion and future work
It’s challenging to develop a framework that enables us to quickly prototype and test new analyses. We attempt to meet this challenge with DARTH, a distributed analysis framework for research and threat hunting, as discussed in this blog.
The lesson learned from implementing DARTH is that there are many available open-source tools that can be combined to achieve an effective and scalable analysis framework. While each tool provides a single facet of the overall analysis, advances in container technology, micro-virtualization, and orchestration provide new opportunities for the creation of sophisticated analysis pipelines.


