

By Uday Kurkure, Lan Vu, and Hari Sivaraman
As a leader in virtualization technologies, VMware by Broadcom has empowered global enterprises by providing innovative infrastructure solutions for data center management that help customers build, run, and manage applications efficiently, securely, and flexibly. For machine learning (ML) and artificial intelligence (AI) workloads, our software solutions work with most hardware vendors to enable these workloads at scale.
Broadcom, Dell, and NVIDIA have collaborated to bring the magic of virtualization to accelerator data centers. We prove our top wizardry by presenting the latest benchmark results using the MLPerf Inference v4.0 data center benchmark suite. In addition to legacy benchmarks, we have submitted outstanding results for the new Stable Diffusion (text-to-images) benchmark. Our results deliver near bare metal or better performance with the added virtualization benefits of data center management.
Hardware and software
We ran MLPerf Inference workloads on Dell XE9680 with 8x virtualized NVIDIA SXM H100 80GB GPUs (test scenario 1) and Dell R760 with 2x virtualized NVIDIA L40S 80GB GPUs (test scenario 2) with vSphere 8.02 and NVIDIA vGPUs. The virtual machines used in our tests were allocated with only 32 out of 120–224 available CPUs and 128GB out of 1TB–1.5TB available memory. This means we used just a fraction of the system’s capacity.
Tables 1 and 2 show the hardware configurations used to run the LLM workloads on the bare metal and virtualized systems. The benchmarks were optimized with NVIDIA TensorRT-LLM. TensorRT-LLM consists of the TensorRT deep learning compiler and includes optimized kernels, pre- and post-processing steps, and multi-GPU/multi-node communication primitives for groundbreaking performance on NVIDIA GPUs.
Table 1. Hardware and software for test scenario 1
| Bare metal | Virtual | |
| System | Dell PowerEdge XE9680 | Dell PowerEdge XE9680 |
| Processors | 2x Intel Xeon Platinum 8480 | 2x Intel Xeon Platinum 8480 |
| Logical processors | 228 | 32 (14%) allocated to the VM for inferencing (196 available for other VMs/workloads) |
| GPU | 8 x H100-SXM-80GB | 8 x NVIDIA GRID H100-SXM-80c vGPU (full profile) |
| Memory | 1TB | 128GB allocated for inferencing VM out of 1TB (12.8%) |
| Storage | 7.68TB NVMe SSD | 5.82TB NVMe SSD |
| OS | Ubuntu 22.04 | Ubuntu 22.04 VM in vSphere 8.0.2 |
| NVIDIA AI Enterprise VB for ESXi | NVIDIA Driver 535.54.03 | NVIDIA vGPU GRID Driver 550.53 |
| CUDA | 12.2 | 12.2 CUDA and Linux vGPU Driver 550.53 |
| TensorRT | TensorRT 9.3.0 | TensorRT 9.3.0 |
| Special VM settings | N/A | pciPassthru0.cfg.enable_uvm = “1” |
Table 2. Hardware and software for test scenario 2
| Bare Metal | Virtual | |
| System | Dell PowerEdge R760 | Dell PowerEdge R760 |
| Processors | 2x Intel Xeon Platinum 8580 | 2x Intel Xeon Platinum 8580 |
| Logical processors | 240 | 32 (13%) allocated to the VM for inferencing (208 available for other VMs/workloads) |
| GPU | 2x L40S 48GB | 2x NVIDIA GRID L40S 48c vGPU (full profile) |
| Memory | 1.5TB | 128GB allocated for inferencing VM of out 1.5TB (8.5%) |
| Storage | 6TB NVMe SSD | 5.82TB NVMe SSD |
| OS | Ubuntu 22.04 | Ubuntu 22.04 VM in vSphere 8.0.2 |
| NVIDIA AI Enterprise VB for ESXi | NVIDIA Driver 545.23.08 | NVIDIA vGPU GRID Driver 535.129.03 |
| CUDA | 12.3 | 12.2 CUDA and Linux vGPU Driver 535.129.03 |
| TensorRT | TensorRT 9.3.0 | TensorRT 9.3.0 |
| Special VM settings | N/A | pciPassthru0.cfg.enable_uvm = “1” |
Test scenario 1: Performance comparison of virtualized vs native ML/AI workloads, featuring a Dell PowerEdge XE9680 vSphere host/bare metal server with 8 NVIDIA H100 GPUs
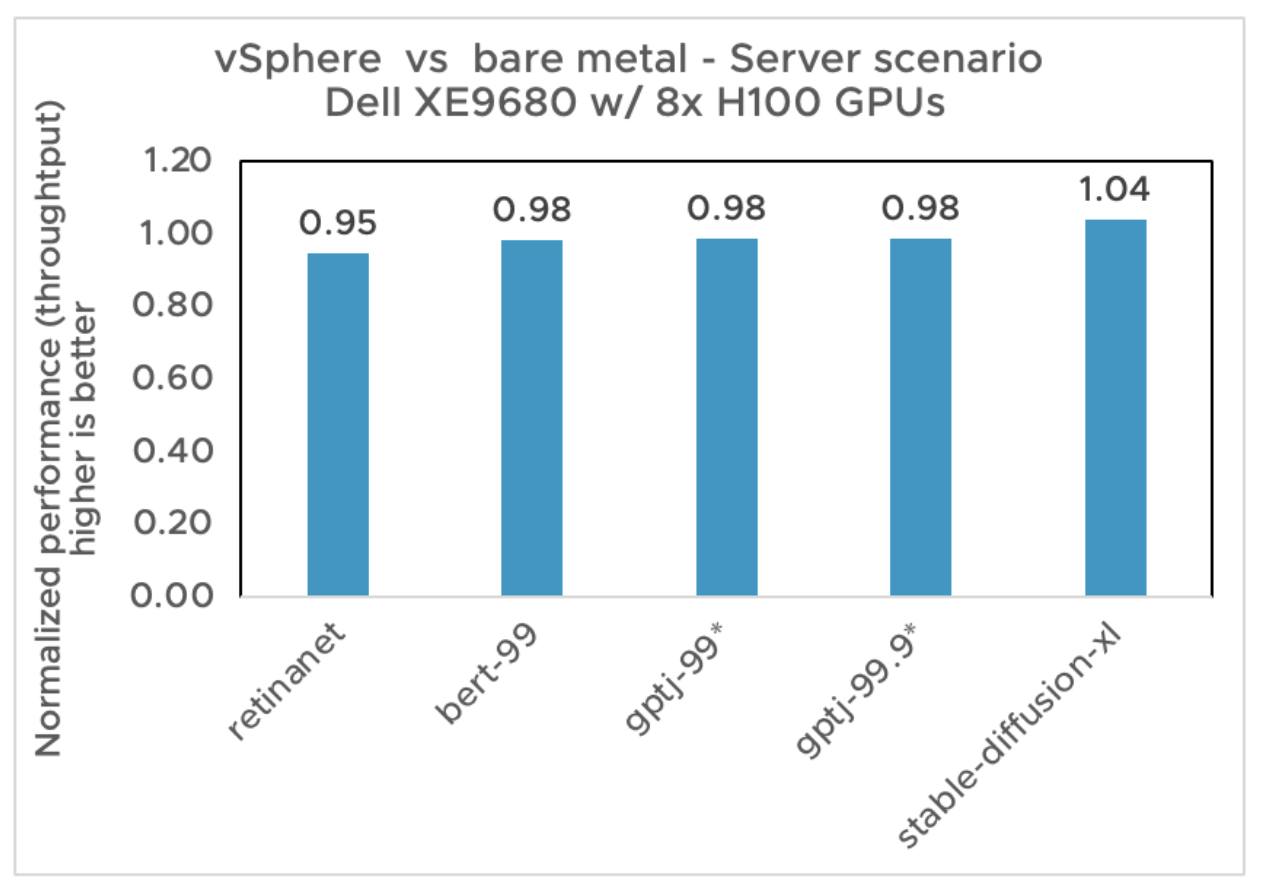
Figures 1 and 2 show the performance results of test scenario 1, which compares a bare metal configuration with vSphere on a Dell PowerEdge XE9680 with 8 H100 GPUs. The bare metal baseline is set to 1.0, and the virtualized result is presented as a relative percentage of the baseline. Compared to the bare metal results, vSphere with NVIDIA vGPUs delivers near bare metal performance, ranging from 95% to 104% for the Offline and Server scenarios of the MLPerf Inference 4.0 benchmark.
In an Offline scenario, the workload generator (LoadGen) sends all queries to the system under test at the start of the run. In a Server scenario, LoadGen sends new queries to the system under test according to a Poisson distribution. This is shown in table 3.
Table 3. Server vs Offline scenarios in the MLPerf Inference 4.0 benchmark
| Scenario | Query generation | Duration | Samples per query | Latency constraint | Tail latency | Performance metric |
| Server | LoadGen sends new queries to the SUT according to a Poisson distribution | 270,336 queries and 60 seconds | 1 | Benchmark-specific | 99% | Maximum Poisson throughput parameter supported |
| Offline | LoadGen sends all queries to the SUT at start | 1 query and 60 seconds | At least 24,576 | None | N/A | Measured throughput |
Source: MLPerf Inference: Datacenter Benchmark Suite Results, “Scenarios and Metrics”
We observed the following virtualized results for the MLPerf Inference 4.0 benchmarks:
- Language and image: 4% better than bare metal
- GPT-J 6 billion LLM summarization model (99% and 99.9%) with the CNN-DailyMail news text summarization dataset
- SDXL 1.0 (Stable Diffusion) image generation model with the COCO-2014 dataset
- Other benchmarks, as shown in the following figures and described at MLPerf Inference: Datacenter Benchmark Suite Results, “Benchmarks”: 0%–1% overhead compared to bare metal
Note: The MLCommons verified the results of Retinanet, BERT-large (99% and 99.9%), RNNT, 3D UNET (99% and 99.9%), and SDXL 1.0. The results are shown at MLPerf Inference: Datacenter Benchmark Suite Results, “Results.” We ran the GPT-J 6 billion (99% and 99.9%) benchmark with the same hardware and software systems mentioned above, but MLCommons did not verify these results, and we didn’t include them as part of our MLPerf Inference v4.0 submission.
Figure 1. vSphere vs bare metal for offline inference results on Dell XE9680 for Retinanet, 3D UNET (99% and 99.9%), BERT-large (99%), GPT-J 6B (99% and 99.9%), and SDXL 1.0 (Stable Diffusion)

Figure 2. vSphere vs bare metal for server inference results on Dell XE9680 for Retinanet, BERT-large (99%), GPT-J 6B (99% and 99.9%), and SDXL 1.0 (Stable Diffusion)
Test scenario 2: Performance comparison of virtualized vs native ML/AI workloads, featuring a Dell PowerEdge R760 vSphere host/bare metal server with 2 NVIDIA L40S GPUs
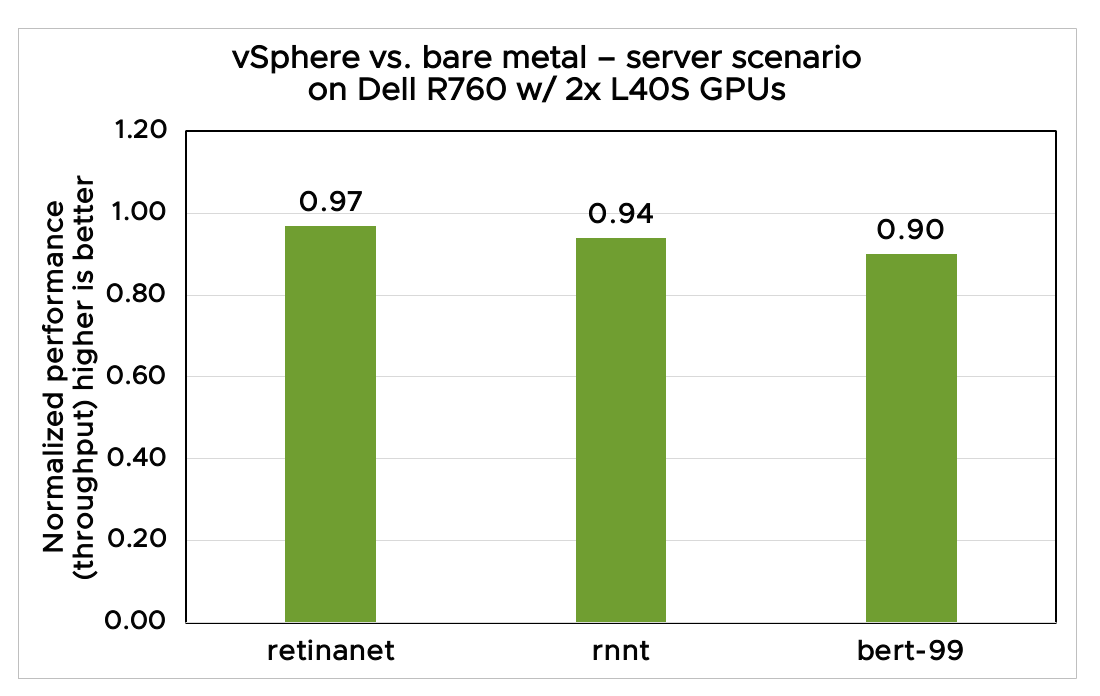
For test scenario 2, we observed the virtual results to have an overhead of 2%–10% compared to the bare metal results for the Offline and Server scenarios (as shown in figures 3 and 4).
Figure 3. vSphere vs bare metal for Offline inference results on Dell R760 for Retinanet, 3D UNET (99% and 99.9%), RNNT, and BERT-large (99%)

Figure 4. vSphere vs bare metal for Server inference results on Dell R760 for Retinanet, RNNT, and BERT-large (99%)
Conclusion
We used only 32 logical CPU cores and 128GB of memory for this inference benchmarking—that’s a key benefit of virtualization. This lets you use the remaining CPU and memory capacity on the same systems to run other workloads, save on the cost of ML/AI infrastructure, and leverage the virtualization benefits of vSphere for managing data centers.
The results of our benchmark testing show that vSphere 8.0.2 with NVIDIA virtualized GPUs is in the Goldilocks Zone for ML/AI workloads. vSphere also makes it easy to manage and process workloads quickly using NVIDIA vGPUs, flexible NVLinks to connect devices, and vSphere virtualization technologies to use AI/ML infrastructure for graphics, training, and inference. Virtualization lowers the total cost of ownership (TCO) of an ML/AI infrastructure by allowing you to share expensive hardware resources among multiple tenants.
Acknowledgments: We would especially like to thank Jia Dai, Manvendar Rawat (NVIDIA) , Frank Han, Vinay HN, Jay Engh, Nirmala Sundararajan (Dell), Juan Garcia-Rovetta, and Julie Brodeur (Broadcom) for their help and support in completing this work.
Discover more from VMware Cloud Foundation (VCF) Blog
Subscribe to get the latest posts sent to your email.





