
According to a NASA news release, the exoplanet K2-18b is in the Goldilocks Zone, which could support bodies of water—and life. It is 120 light-years away. Luckily, the Goldilocks Zone for running your large language models (LLMs) is not 120 light-years away.
Now you can run your LLMs in the Goldilocks Zone of NVIDIA AI Enterprise for VMware vSphere and get near bare metal performance for large language models with the benefits of virtualization.
Large language models (LLMs) are a type of artificial intelligence (AI) that can generate and understand text. They are trained on massive datasets of text and code, and can be used for a variety of tasks, including translation, writing, and coding.
LLMs can be computationally expensive to train and run. This is where virtualization can help. Virtualization with AI Enterprise for vSphere lets you share the processing power of multiple GPUs on a single physical server as one or more virtual GPUs. This can help you reduce costs and improve efficiency.
The paper Large Language Model Inference Performance with NVIDIA Enterprise in vSphere discusses the performance of a virtualized LLM workload (language processing, GPT-J 6B model, with the CNN-DailyMail News Text Summarization dataset) from the MLPerf Inference v3.1 suite. The results show that the virtualized performance is close to that of a bare metal setup. This means you can get virtualization benefits without incurring much overhead.
This paper presents performance results for the VMware vSphere virtualization platform with NVIDIA H100-80GB vGPUs using the large language model GPT-J with 6 billion parameters. We use the MLPerf Inference 3.1 benchmark for our performance testing. The results fall into the “Goldilocks Zone,” which is the area of outstanding performance and increased security and manageability that the power of virtualization makes possible.
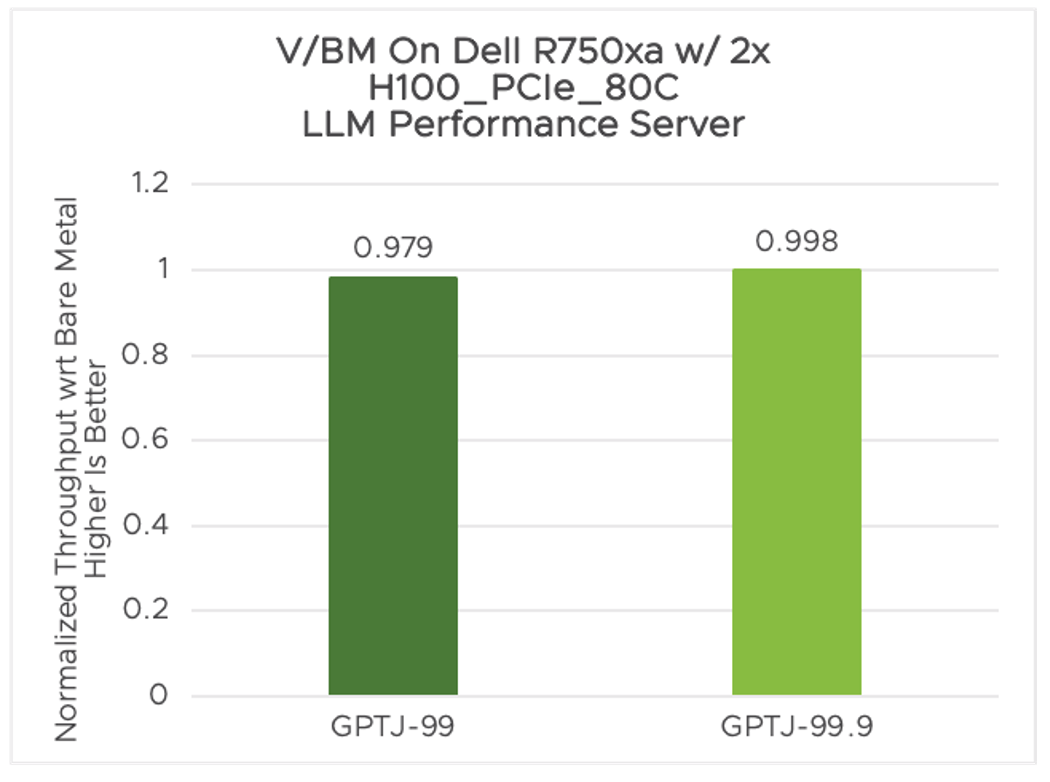
Our tests show that the GPT-J with 6 billion parameters inference performance tested with NVIDIA vGPUs in vSphere is 97.9% to 99.8% of the performance on the bare metal system, measured as queries served per second (qps) in the Server scenario
Figure 1. Normalized throughput for Server scenario (qps): vGPU 2x NVIDIA H100-80c vs bare metal 2x NVIDIA H100-80GB
The paper Large Language Model Inference Performance with NVIDIA Enterprise in vSphere shows that it is possible to get the performance of bare metal. This makes virtualization a good option for businesses that are looking to deploy LLMs at scale.
Discover more from VMware Cloud Foundation (VCF) Blog
Subscribe to get the latest posts sent to your email.




