
As a result of a joint testing effort between NVIDIA and VMware, a performance white paper is available that uses Redis as a workload to show the advantages of using NVIDIA DPU with VMware vSphere 8.
In 2022, VMware launched the capability to run vSphere on DPUs (previously known as “Project Monterey”), which in the first release specifically allowed vSphere 8 to offload networking and NSX security services to a DPU such as NVIDIA BlueField. This frees up CPU cycles on the host, which can now be used to scale out to larger workloads that are run in isolation from network processing tasks to achieve top application performance. Such workload consolidation enables datacenters to run with a smaller hardware footprint, reduced power consumption, and lower capital and operating costs.
Performance tests use Redis, a popular in-memory database, to show DPU benefits on the vSphere Distributed Services Engine. Figure 1 shows how DPU offload and acceleration can run up to 20 million transactions per second with much lower latency for 80 Redis instances on the same host hardware, compared to only 12.75 million with a similar regular NIC.
![]()
Figure 1. When scaling out the number of Redis instances, we see that the cases with DPU noticeably outperform the baseline case using a regular NIC. Note: Higher bars show better performance.
Figure 2 shows the average latency across Redis transactions. It also shows how isolating network processing to the DPU helps achieve lower latencies.
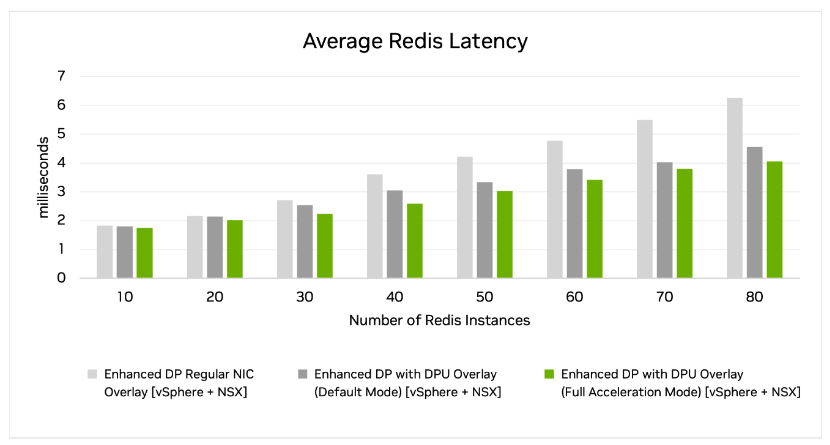
Figure 2. The vSphere + NSX solution with DPU in full acceleration mode performs best when measuring the amount of latency there is when scaling out the number of Redis instances. Note: Lower bars show better performance.
One of the most useful metrics used to understand the potential CPU savings from a DPU for a target use case is to measure the number of l-cores consumed for network processing on ESXi when using a regular NIC. This can be obtained by summing up the used metric reported for all the EnsNetWorld processes on ESXi using the following command:
|
1 |
net-stats -A -t WwQqihVcE -i 10 | grep "EnsNetWorld" |
For the case of 80 concurrent Redis streams (figure 3), we observe that network processing using a regular NIC consumes about 15.2 l-cores (light gray bar). In contrast, vSphere + NSX consumes almost zero l-cores (green bar) for the DPU case in full acceleration mode.
These saved host CPUs were used to process more application transactions, but by isolating the network processing to the DPU, the application logic on the host had better CPU cache locality, which improved performance.
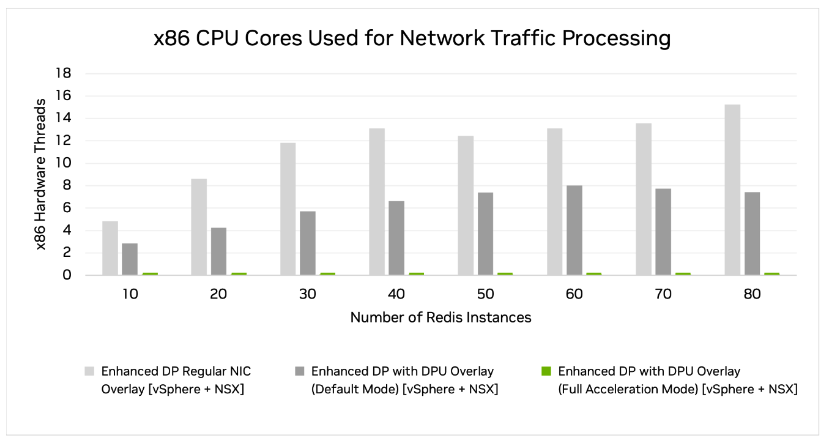
Figure 3. When scaling out the number of Redis instances, the vSphere + NSX solution with DPU in full acceleration mode uses almost no processor l-cores. This leaves many CPU l-cores for other tasks. Note: Lower bars show better performance.
It could be easier to do the same study using microbenchmarks like iperf or netperf; however, the network processing load on the host CPUs and cache locality–based improvements from a DPU when using these microbenchmarks might not represent real user applications.
For more details about the test results, read the paper.
About the authors
 |
Jose Castanos received his PhD in Computer Science at Brown University in 2000, joining IBM Research soon after. At IBM he lead teams in several areas. He designed and managed many of the system software innovations of the BlueGene supercomputers, which were largest machines at the time. He supervised a team focus on JIT compilation of dynamic scripting languages. He led the evaluation and deployment of a new data center architecture for the IBM Cloud built around SmartNICs. After 20+ years at IBM, he joined the network team at NVIDIA in 2021 to focus in usability and performance features of these new Data Processing Units (DPUs).
|
 |
Karthik Ganesan is a staff 2 performance engineer at VMware R&D with a focus on vSphere performance. Before joining VMware, he was a principal performance engineer at Oracle where he led many successful cross-stack performance projects. He has broad experience in cloud systems performance with special interests in resource management, operating systems, middleware, virtualization, and hardware acceleration. He obtained his PhD in computer engineering from the University of Texas at Austin. He holds multiple US patents, has given talks, and published book chapters and numerous papers at reputed computer science conferences. |
Discover more from VMware Cloud Foundation (VCF) Blog
Subscribe to get the latest posts sent to your email.





