
By Chris Gully, Yuankun Fu, and Rizwan Ali (Dell)
High Performance Computing (HPC) involves processing complex scientific and engineering problems at high speed across a cluster of compute nodes. Such workloads demand the highest performance of the systems they run on; these workloads have typically been run on bare metal servers with large amounts of memory and compute power, connected by high-speed networks. However, there has been a growing interest in running HPC applications in virtual environments. In addition to providing resiliency and redundancy for the virtual nodes, virtualization offers the flexibility to quickly instantiate a secure virtual HPC cluster.
In a prior blog, we demonstrated near bare-metal performance when running high throughput workloads on VMware vSphere®. In this blog, we show similar performance for HPC applications that are tightly coupled and leverage message passing to scale out to multiple servers and reduce time to results.
Most people tend to run their scale-out HPC workloads on dedicated hardware, which is often composed of server compute nodes that are interconnected by high-speed networks to maximize their performance. We compare the performance of running and scaling HPC workloads on dedicated bare metal nodes to a vSphere 7–based virtualized infrastructure. As part of this study, we also tuned the physical and virtual infrastructure to achieve optimal virtual performance, and we share these findings and recommendations.
Performance Test Details
We benchmarked tightly coupled HPC applications or message passing interface (MPI)–based workloads and observed promising results. These applications consist of parallel processes (MPI ranks) that leverage multiple cores and are architected to scale computation to multiple compute servers (or VMs) to solve the complex mathematical model or scientific simulation in a timely manner. Examples of tightly coupled HPC workloads include computational fluid dynamics (CFD) used to model airflow in automotive and airplane designs, weather research and forecasting models for predicting the weather, and reservoir simulation code for oil discovery.
To evaluate the performance of these tightly coupled HPC applications, we used a 16-node HPC cluster using Dell PowerEdge R640 vSAN ReadyNodes as the compute building block. The Dell PowerEdge R640 was a 1U dual-socket server with Intel® Xeon® Scalable processors.
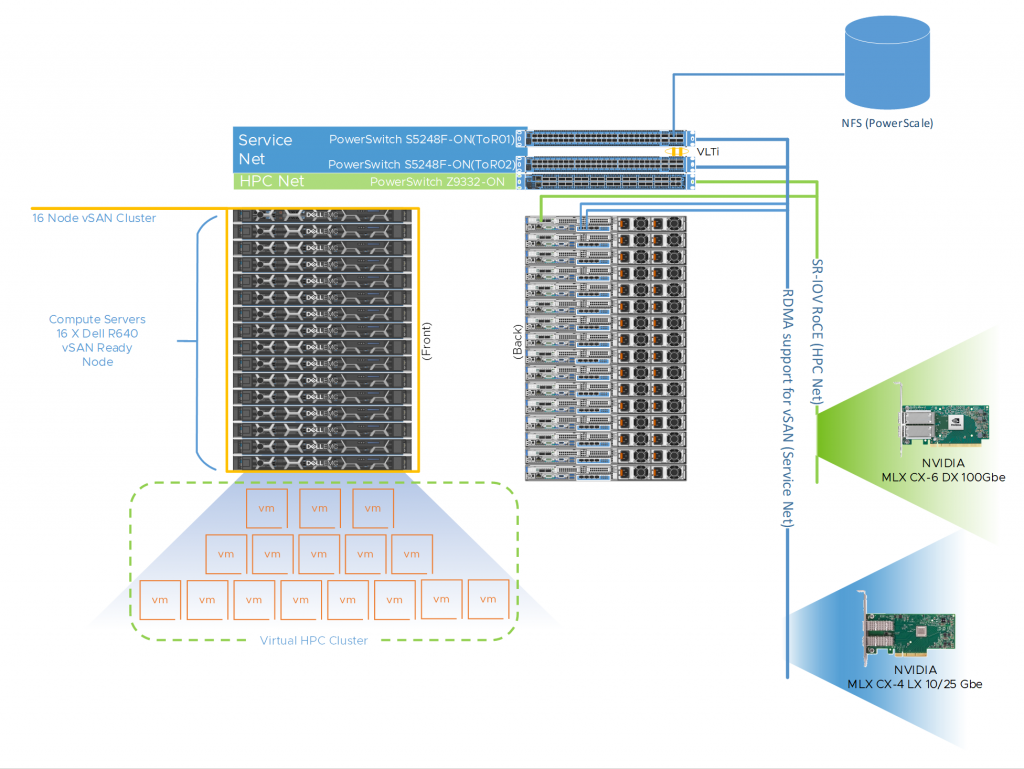
Figure 1 shows a representative network topology of this cluster. The cluster was connected to two separate physical networks. We used the following components for this cluster:
- Dell PowerSwitch Z9332 switch connecting NVIDIA® Connect®-X6 100 GbE adapters to provide a low latency, high bandwidth 100 GbE RDMA–based HPC network for the MPI-based HPC workload
- A separate pair of Dell PowerSwitch S5248F 25 GbE–based top of rack (ToR) switches for hypervisor management, VM access, and VMware vSAN networks for the virtual cluster
The VM switches provided redundancy and were connected by a virtual link trunking interconnect (VLTi). We created a VMware vSANTM cluster to host the VMDKs for the virtual machines. To maximize CPU utilization, we leveraged RDMA support for vSAN. This provides direct memory access between the nodes participating in the vSAN cluster without involving the operating system or the CPU. RDMA offers low latency, high throughput, and high IOPs that are more difficult to achieve with traditional TCP-based networks. It also enables the HPC workloads to consume more CPU for their work without impacting the vSAN performance.
⇑ Figure 1. A 16-node HPC cluster testbed
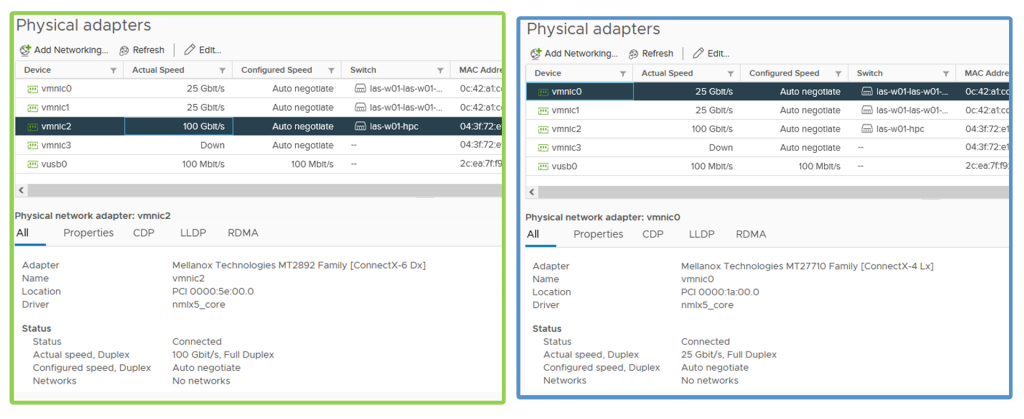
⇑ Figure 2. Physical adapter configuration for HPC network and service network
Table 1 describes the configuration details of the physical nodes and the network connectivity. For the virtual cluster, we provisioned a single VM per node for a total of 16 VMs or virtual compute nodes. We configured each VM with 44 vCPUs and 144 gigabytes of memory, enabled the virtual CPU and memory reservation, and set the VM latency sensitivity to high.
Figure 1 provides an example of how we cabled the hosts to each fabric. We connected one port from each host to the NVIDIA Mellanox ConnectX-6 adapter and to the Dell PowerSwitch Z9332 for the HPC network fabric. For the service network fabric, we connected two ports from the NVIDIA Mellanox ConnectX-4 adapter to the Dell PowerSwitch S5248 ToR switches.
| Bare Metal | Virtual | |
| Server | PowerEdge R640 vSAN ReadyNode | |
| Processor | 2 x Intel Xeon 2nd Generation 6240R | |
| Cores | All 48 cores used | 44 vCPU used |
| Memory | 12 x 16GB @3200 MT/s All 192 GB used |
144 GB reserved for the VM |
| Operating System | CentOS 8.3 | Host: VMware vSphere 7.0U2 Guest: CentOS 8.3 |
| HPC Network NIC | 100 GbE NVIDIA Mellanox Connect-X6 | |
| Service Network NIC | 10/25 GbE NVIDIA Mellanox Connect-X4 | |
| HPC Network Switch | Dell PowerSwitch Z9332F-ON | |
| Service Network Switch | Dell PowerSwitch S5248F-ON | |
⇑ Table 1. Configuration details for the bare-metal and virtual clusters
Table 2 shows a range of different HPC applications across multiple vertical domains along with the benchmark datasets that we used for the performance comparison.
| Application | Vertical Domain | Benchmark Dataset |
| OpenFOAM | Manufacturing – Computational Fluid Dynamics (CFD) | Motorbike 20M cell mesh |
| Weather Research and Forecasting (WRF) | Weather and Environment | Conus 2.5KM |
| Large-scale Atomic/Molecular Massively Parallel Simulator (LAMMPS) | Molecular Dynamics | EAM Metallic Solid Benchmark |
| GROMACS | Life Sciences – Molecular Dynamics | HECBioSim Benchmarks – 3M Atoms |
| Nanoscale Molecular Dynamics (NAMD) | Life Sciences – Molecular Dynamics | STMV – 1.06M Atoms |
⇑ Table 2. Application and benchmark details
Performance Results
Figures 3 through 7 show the performance and scalability for five representative HPC applications in the CFD, weather, and science domains. Each application was run to scale from 1 node through 16 nodes on the bare metal and virtual cluster. All five applications demonstrate efficient speedup when computation is scaled out to multiple systems. The relative speedup for the application is plotted to evaluate the performance overheads, if any, in a virtualized environment (the baseline is application performance on a bare-metal single node).
The results indicate that MPI application performance running in a virtualized infrastructure (with proper tuning and following best practices for latency-sensitive applications in a virtual environment) is close to the performance observed for bare-metal infrastructure.
- The single-node performance delta ranges from no difference for WRF to a maximum of 8 percent difference observed with LAMMPS.
- Similarly, as the nodes are scaled, the performance observed on the virtual nodes is comparable to that on the bare-metal infrastructure, with the largest delta being 10% when running LAMMPS on 16 nodes.
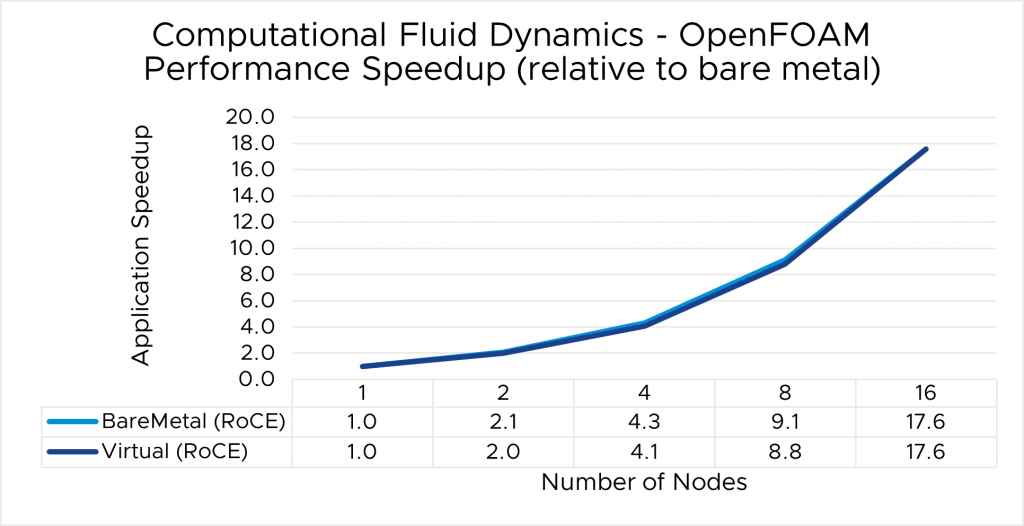
⇑ Figure 3. OpenFOAM performance comparison between virtual and bare-metal systems
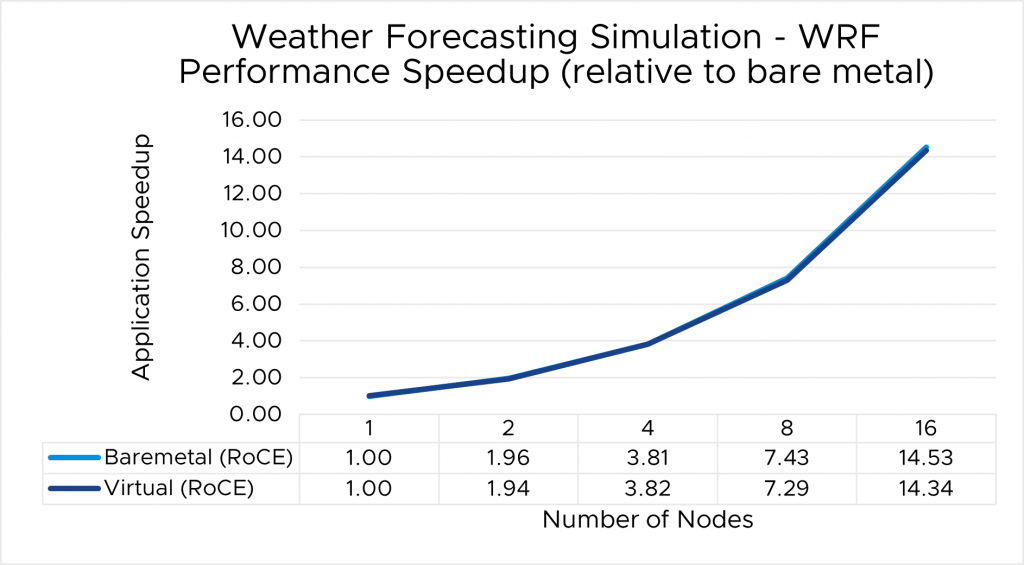
⇑ Figure 4. WRF performance comparison between virtual and bare-metal systems
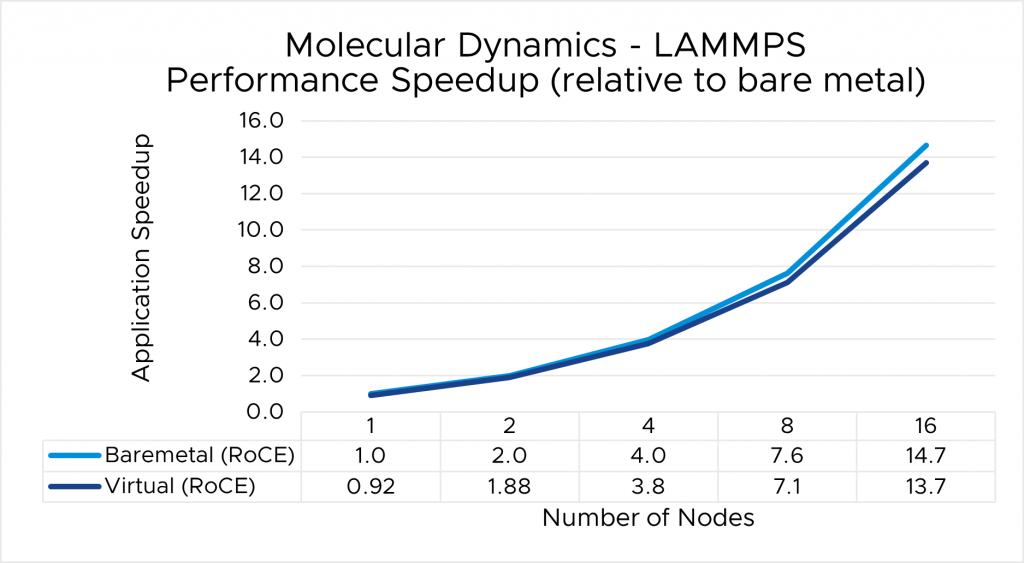
⇑ Figure 5. LAMMPS performance comparison between virtual and bare-metal systems
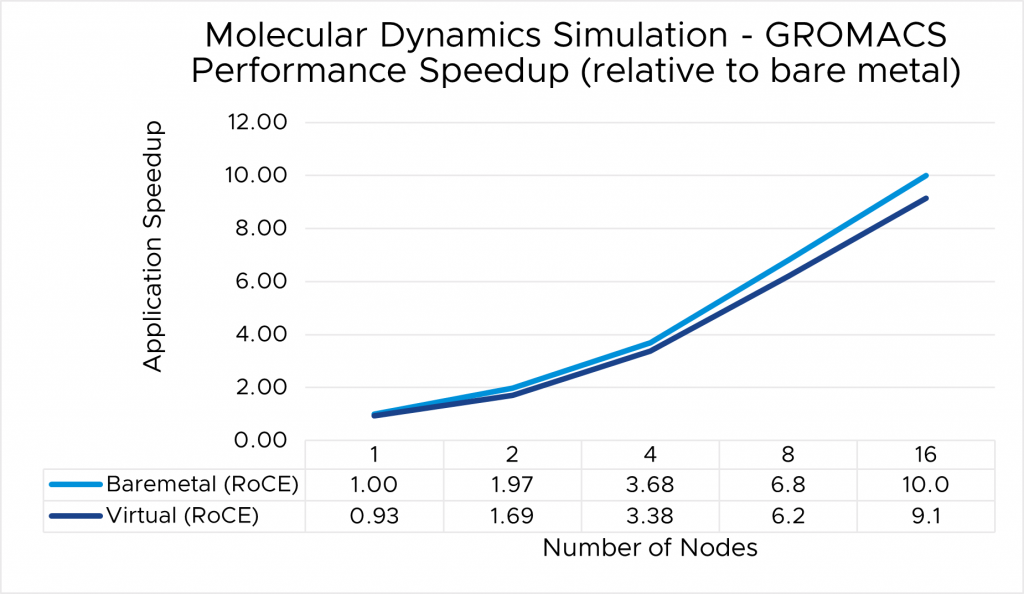
⇑ Figure 6. GROMACS performance comparison between virtual and bare-metal systems
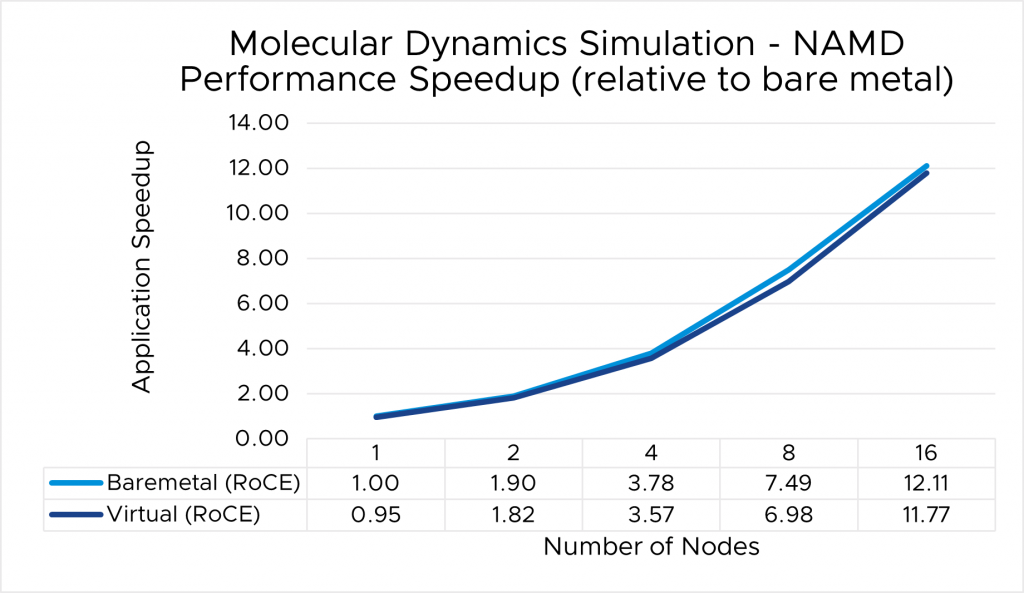
⇑ Figure 7. NAMD performance comparison between virtual and bare-metal systems
Tuning for Optimal Performance
One of the key elements of achieving a viable virtualized HPC solution is the tuning best practices that allow for optimal performance. We achieved a significant increase in performance after some minor tweaks we made from the out-of-box configuration. These improvements are a critical ingredient to ensuring you’ll see results that allow for the implementation of a virtual HPC environment and the adoption of a cloud-ready ecosystem that provides operational efficiencies and multi-workload support.
Table 3 outlines the parameters that we found to work best for MPI applications. Given the nature of MPI for parallel communication and its heavy reliance on a low-latency network, we suggest you set VM Latency Sensitivity in vSphere 7.0 to High Performance. This setting optimizes the scheduling delay for latency-sensitive applications by:
- Giving exclusive access to physical resources to reduce resource contention
- By-passing virtualization layers that are not providing value for these workloads
- Tuning the network virtualization stack to reduce any unnecessary overhead
We have also outlined the additional physical host and hypervisor tunings that complete these best practices below.
| Setting | Value |
| Host Server | |
| BIOS Power Profile | Performance per watt (OS) |
| BIOS Hyper-threading | On |
| BIOS Node Interleaving | Off |
| BIOS SR-IOV | On |
| Hypervisor | |
| ESXi Power Policy | High Performance |
| Virtual Machine | |
| VM Latency Sensitivity | High |
| VM CPU Reservation | Enabled |
| VM Memory Reservation | Enabled |
| VM Sizing | Maximum VM size with CPU/memory reservation |
⇑ Table 3. Recommended performance tunings for tightly coupled HPC workloads
Figure 8 shows a snapshot of the recommended tuning settings as applied to the virtual machine used as the virtual nodes on the HPC cluster.
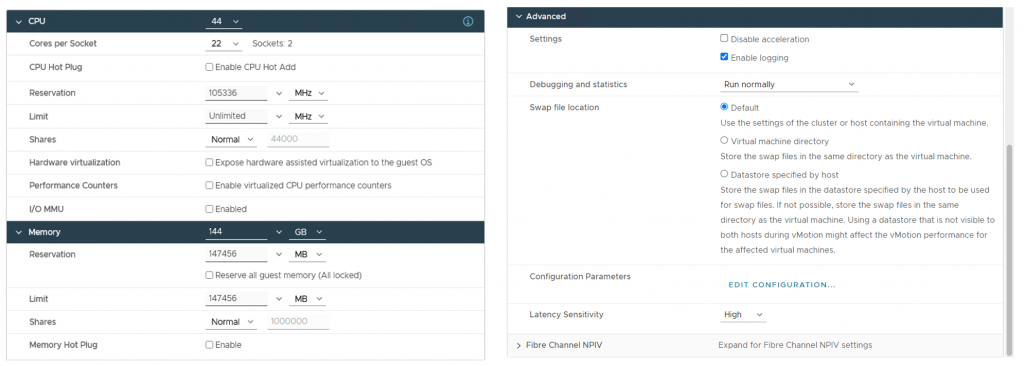
⇑ Figure 8. Virtual machine configuration with the recommended tuning settings
Conclusion
Achieving optimal performance is a key consideration for running an HPC application. While most HPC applications enjoy the performance benefits offered by dedicated bare-metal hardware, our results indicate that with appropriate tuning, the performance gap between virtual and bare-metal nodes has narrowed, making it feasible to run certain HPC applications in a virtualized environment. We also observed that these tested HPC applications demonstrate efficient speedups when computation is scaled out to multiple virtual nodes.
Additional Resources
If you’re interested in learning more about running HPC workloads on VMware products, please visit our blogs at https://blogs.vmware.com/apps/hpc and https://octo.vmware.com/tag/hpc to read more about our previous and ongoing work.
To learn more about o the Dell Technologies HPC & AI Innovation Lab, see the High Performance Computing overview and the Dell Technologies Info Hub blog page for HPC solutions.
Acknowledgments
The authors thank Martin Hilgeman from Dell Technologies, Ramesh Radhakrishnan and Michael Cui from VMware, and Martin Feyereisen for contributing to the study.
Discover more from VMware Cloud Foundation (VCF) Blog
Subscribe to get the latest posts sent to your email.





