
By Michael Cui and Ramesh Radhakrishnan
High Performance Computing (HPC) is an area in which massive computing power is used to solve complex scientific and engineering problems. It often involves running a cluster of compute nodes to execute complex simulation code and/or processing large quantities of data. HPC is widely applied in many industries, such as drug discovery in life sciences, risk modeling in finances, electronics design and automation in the chip industry, and image rendering in the movie industry. Many VMware customers have a significant amount of HPC workloads within their organizations. In fact, these workloads are often one way they differentiate and out-innovate their competition, as HPC has a direct impact on the design and implementation of the products and services they offer.
Performance is one of the most important characteristics of HPC. To obtain the maximum performance, people tend to run their HPC workloads on dedicated hardware, which is often composed of server-grade compute nodes interconnected by high-speed networks. Although virtualization is a rising trend to modernize HPC, some professionals are still concerned that the additional software layer introduced by virtualization may impact performance.
Our team within the Office of the CTO has been focusing on supporting HPC and machine learning workloads on the VMware platform. We believe that HPC can take advantage of the various benefits of virtualization and, in some cases, the SDDC platform (for example, heterogeneity, multi-tenancy, reproducibility, and automation to name just a few) and meet performance goals.
During the past years, we have successfully run many HPC workloads, ranging from molecular dynamics to weather forecasting, with excellent performance on our virtual platform. We collaborated with several customers to virtualize their HPC footprint. For example:
- The University of Groningen adopted vSphere to unify three data centers and provide a shared infrastructure for IT and HPC workloads
- Jackson National Life Insurance achieved free “cycle harvesting” for HPC workloads from their virtual desktop infrastructure
- The Johns Hopkins University Applied Physics Laboratory successfully implemented virtualization in the HPC cluster with vSphere to significantly boost flexibility and resource utilization
In this blog, we showcase our success with running HPC applications on the latest vSphere 7 platform, and we share data for both high-throughput and tightly coupled HPC workloads.
High-Throughput Workload Performance
BioPerf is a popular benchmark suite that includes several life sciences benchmarks. These benchmarks represent throughput-oriented HPC workloads that simultaneously run on multiple cores but do not require any message passing. This class of applications also represents workloads such as Monte Carlo simulations used in finance or physics which run on a single core, but the infrastructure must process thousands of jobs per simulation.
To objectively evaluate performance, we always compare apples-to-apples between bare-metal and virtual environments using the same hardware. That is, on the same testbed we configured two operating environments:
- One was an operating system installed on a bare-metal server
- The other was the same operating system running inside a VM on top of the VMware ESXi hypervisor
For this study, we used RHEL 8.1 as both the bare-metal operating system and guest operating system, and the testbed was a Dell R740XD server with dual Intel Xeon Gold 6248R CPUs and 384 GB of memory.
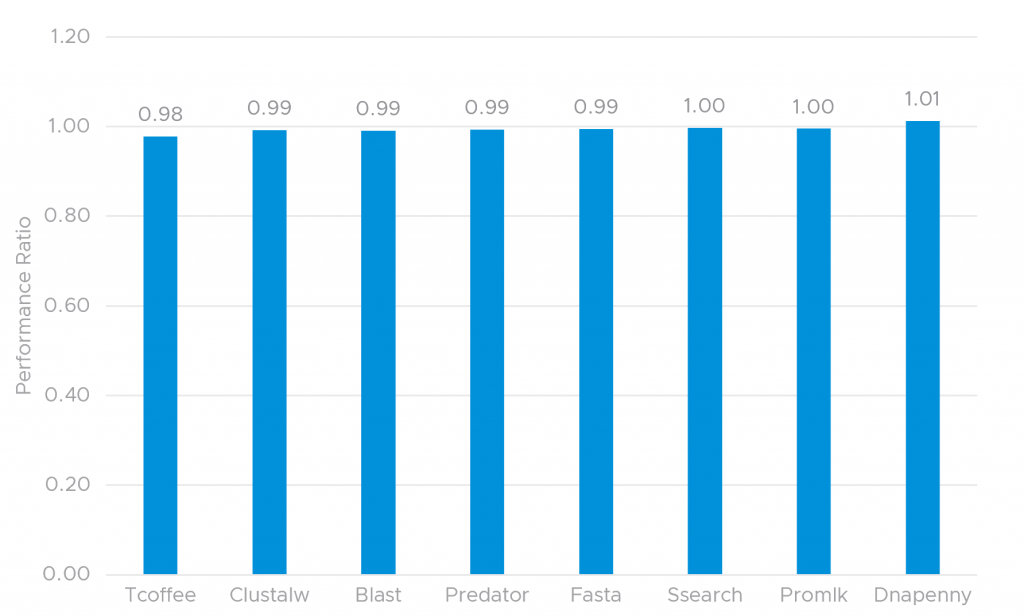
The results we obtained for BioPerf are illustrated in Figure 1. The X-axis shows the eight benchmarks from BioPerf, and the Y-axis shows the performance ratio between the virtual and bare-metal systems. We used wall clock time to measure throughput performance, and the performance ratio was calculated as the wall clock time in bare metal divided by the time in virtual for each individual benchmark. As you can see from the figure, the performance of the BioPerf benchmarks on virtual is very close to bare metal. With such minor performance differences, users can leverage the benefits brought by virtualization with essentially no performance overhead. Customers achieve increased operational simplicity and uniformity by bringing these important workloads onto their enterprise IT infrastructures.
As in traditional bare-metal HPC systems, optimal performance requires careful tuning. During these experiments, we have applied the recommended settings from BIOS to VM sizing following the Running HPC and Machine Learning Workloads on VMware vSphere – Best Practices Guide white paper. Specifically, the applied tunings are summarized in Table 1 below.
| Setting | Value |
| BIOS Power Profile | Performance per watt (OS) |
| BIOS Hyper-threading | On |
| BIOS Node Interleaving | Off |
| ESXi Power Policy | Balanced |
| VM sizing | Same as the physical host |
Tightly Coupled HPC Workload Performance
Our team also evaluated tightly coupled HPC applications or message passing interface (MPI)-based workloads and demonstrated promising results. These applications consist of parallel processes (MPI ranks) that leverage multiple cores, and applications are architected to scale computation to multiple compute servers (or VMs) to solve the complex mathematical model or scientific simulation in a reasonable amount of time. Examples of tightly coupled HPC workloads include computational fluid dynamics (CFD) used to model airflow in automotive and airplane designs, weather research and forecasting models for predicting the weather, and reservoir simulation code for oil discovery.
Stay tuned, as we plan to publish performance results showing the scaling efficiencies and compare performance to bare metal in an upcoming blog.
HPC on VMware
If you’re interested in learning more about running HPC workloads on VMware, please visit our blogs at https://blogs.vmware.com/apps/hpc and https://octo.vmware.com/tag/hpc/ to read more about our previous and ongoing work.
About the Authors
Michael Cui is a Member of Technical Staff in the VMware Office of the CTO, focusing on virtualizing High Performance Computing. His expertise spans broadly across distributed systems and parallel computing. His daily work ranges from integrating various SW and HW solutions, to conducting Proof-of-Concept studies, to performance testing and tuning, and to technical paper publishing. In addition, Michael serves on Hyperion’s HPC Advisory Panel and participates in paper reviewing in several international conferences and journals, such as IPCCC, TC, and TSC. Previously, he was a research assistant and part-time instructor at the University of Pittsburgh. He holds both PhD and Master’s degrees in Computer Science from the University of Pittsburgh.
Ramesh Radhakrishnan is a Technical Director in the HPC/ML team within the VMware Office of the CTO. He has presented at key industry events such as NVIDIA GTC, VMworld, Dell Technologies World, and ARM TechCon, and he has 15 published patents. He received his PhD in Computer Science and Engineering from the University of Texas at Austin. Connect with him on LinkedIn.
Discover more from VMware Cloud Foundation (VCF) Blog
Subscribe to get the latest posts sent to your email.