

Unplanned disruptions happen. Whether it’s a natural disaster, hardware failure, human error or cyberattack, you need to protect your business-critical apps and data so that when an event does happen you can recover and be back in business quickly. But how do you implement an effective cloud-based disaster recovery plan that meets your business requirements? Here is an interactive checklist to guide you through your DRaaS implementation.
Create a disaster recovery strategy
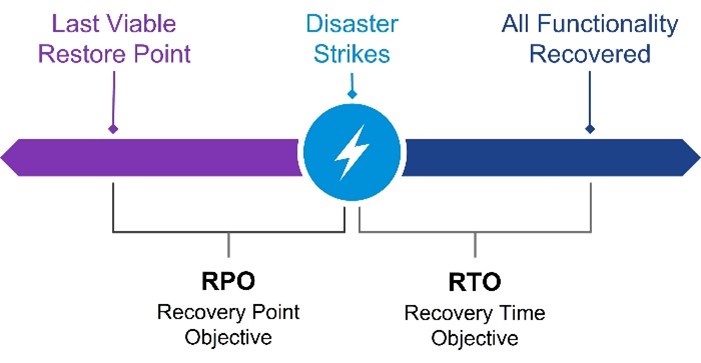
Identify your business goals. Determine your Recovery Time Objectives (RTOs) and Recovery Point Objectives (RPOs)
Identify any deadlines or time constraints, cost constraints, storage constraints and
application constraints.
Define a high-level DR plan with specific execution tasks that identifies who will do what and when.
Identify the disaster recovery team. Work with champions in critical areas including network and
security, operations, infrastructure and applications to drive your DR implementation.
Work with your team to incorporate your virtual DR solution into your organization’s broader
DR strategy.
Discover and analyze the environments to be protected
Gather information through interviews with stakeholders on virtual workloads, applications and
virtual infrastructure. Verify the information is up to date and identify any gaps.
Evaluate the packet flows between workloads in the current environment and map the
dependencies within each application and between applications.
Assess any compliance and security requirements needed for the target environment.
Define protection groups. Protection groups are collections of VMs (defining one or more related
apps) that fail over together with a specific sequence at the recovery site. They are the basis for
defining the scope of your DR plans. For example, you might have a web application that requires
three web servers, three application servers, and two SQL databases. All eight of these VMs would
be grouped into the same protection group. When you fail over to your recovery site, all eight
would fail over together following your restart priorities keeping the application consistent.
Configure the replication timing and snapshot frequency to match your identified RPO and RTO
requirements.
Create a detailed disaster recovery plan with a specific sequence of recovery steps
DR plans are automated runbooks that control all the steps in the recovery process. A DR plan can contain one or more protection groups, and a protection group can be included in more than one DR plan. This flexibility allows for the construction of robust, composite plans as well as very focused subsystem plans depending on your testing and failover objectives. For example, you may have a DR plan to recover a single web app, a DR plan to recover email systems, and a DR plan to recover an entire site.
Design the target DR site to match compute, networking, storage and memory requirements.
For example, determine if you want to change IP addresses during the failover or if you want to
keep them the same.
Deploy the target DR site and map the source site resources to it. For example, map network
segments on the source site to network segments on the target DR site.
Define the scope of each DR plan, recovery steps and sequence. For example, first restart the
database VMs, then the application VMs and later the web apps.
Define any custom scripts that are needed, for example a script to notify the network teams to
reconfigure north-south routing to the DR site
Integrate your DR plan into your organization’s broader DR plan. This can be done via APIs or
simply communicating your insertion point.
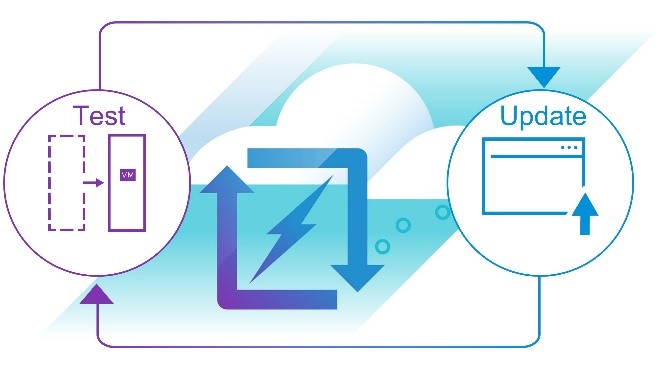
Execute the DR plans to validate failover
When running a DR test, select a specific set of snapshots that match your RPO.Your production replication will continue during the testing without interruption.
Determine if everything goes as expected. If any changes are needed, update the DR plans
accordingly.
Perform the test and update cycle until the DR plans are reliable and consistent.
Get started operating your disaster recovery solution
Leverage best practices and standard operating procedures for IT processes, such as service
request management, capacity management, VM management, monitoring, patching and
upgrades.
Integrate any new or modified procedures with your existing procedures and train your IT staff.
Continuously discover and analyze configuration changes and update and test your DR plans to
maintain ongoing parity between your current environment and your DR plans.
Be prepared to weather any storm
Use this interactive checklist as a visual reminder to prioritize tasks and schedule everything you need for a successful DRaaS implementation.




