


JAMES WIRTH
Technical Solutions Architect
Digital Transformations Begets Software Oriented Operations
Because digital transformation requires new and more expeditious ways of delivering software solutions, both internally and externally, companies should become more software oriented within core infrastructure and operations (I&O) teams.
Site Reliability Engineering Enables Rapid Innovation and Stable Delivery
Companies seeking to increase velocity and reliability of solutions within the digital business should shift their software development efforts ‘further to the right’ into I&O teams by adopting tenants of Site Reliability Engineering (SRE)1.
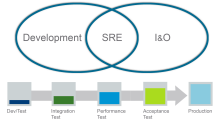
Shift to the right
The SRE paradigm was originally conceived at Google to help them run the google.com site smoothly, efficiently and reliably at scale. SRE is defined as “Fundamentally, what happens when you ask a software engineer to design an operations function2.” An SRE team will analyze business services to determine their actual required reliability (hint it is seldom ever 100%) and specify the operational strategy including deployment frequency from there. This often introduces a fine balancing act between maintaining the desired reliability and increasing software deployment velocity to get new features to users faster.
SRE Has Broad Adoption by Many Top Digital Businesses Like VMware
Google has been quite open and sharing with both the success and implementation of its SRE model. The knowledge gained and spread thereby has enabled other large-scale web companies, such as VMware, Facebook, Twitter, Amazon and so on, to adopt Google’s SRE model and adapt it to their needs. Running a global scale website may not appear relevant to all VMware customers, however we believe that what can be learned from successful, large scale Internet companies can be applied to almost all services in the datacenter.
In broad terms, we define a service as comprised of one or more applications that provide business value. An example of a service could be a company payroll, CRM system or an intranet site. Accordingly, SRE relates to running a service with a reliability mindset.
When applying site reliability engineering we focus on the eight tenets of operating a service.
- Availability
- Latency
- Performance
- Efficiency
- Change Management
- Monitoring
- Emergency Response
- Capacity Planning
You will note that in designing our VMware infrastructure we have taken into consideration these tenets, as we look at items from the perspective of the particular service.
Multi-tier application stack
A basic multi-tier application stack will consist of the following components: an operating system, a web component like Apache, and a database backend like MYSQL and might be used for hosting some kind of web-based application. Some common example stack combinations are LAMP and MEAN. In theory, we could manually install all components on a single virtual machine save it as a template and use it as the basis for deploying our software. If, however, we were to consider the requirements of the service that will run on the stack from an SRE perspective we may choose to do things a little differently.
Operational Analysis
We would make a business decision relating to the required reliability of the service. For example, if the service must be working and available 99.99% of the time, it could be unavailable 0.01% of the time. The 0.01% allowance for downtime would then form the error budget for the service.
We would perform an analysis of the stability of the service to determine that it has a base line of reliability. If the service is not operating within the prescribed error budget, then it would need to go back to development for improvements. Once the service is reliable, we can then spend the available error budget on introducing new features. Once the error budget is used then no new features are allowed to be introduced. This method of management incentivizes developers to create reliable code since the more reliable their service is the more quickly they will be able to bring new features to market.
 Technical Analysis
Technical Analysis
We might consider using a configuration management tool, to automate the provisioning of the server and software components. We might add multiple nodes and a load balancer, not only to provide higher reliability, scale and performance, but to also allow for blue/green deployments of changes. Developing such a complex stack from scratch might be untenable. SRE team might want to look at existing platforms such as Kubernetes when making application platforming decisions, as it is designed with these capabilities from the ground up. It may come as no surprise that Kubernetes also has its origins at Google.
Building on a Solid Foundation
People familiar with VMware’s infrastructure designs and specifically the VMware Certified Design Expert (VCDX) design methodology would be familiar with the design qualities that we consider when designing an infrastructure.
- Availability
- Manageability
- Performance
- Recoverability
- Security
These design qualities are focused primarily on the infrastructure itself and when applied correctly, the result is a robust scalable reliable infrastructure on which to host services. In SRE terms, we are focusing in on a specific service and applying the tenets of SRE to the service rather than the infrastructure. Indeed, the underlying infrastructure is a critical part of the overall reliability of a particular service, so when we are hosting it on well-designed VMware infrastructure we are already in very good standing.
Conclusion
The digital transformation requires new and more expeditious ways for delivering software solutions and SRE is a model adaptable to any company’s requirements. Therefore, because the SRE mindset and processes can be applied to IT operations at any scale, companies should become SRE oriented within core I&O teams.
Notes:
- Site Reliability Engineering, Betsy Beyer, Chris Jones, Jennifer Petoff, Niall Richard Murphy, https://landing.google.com/sre/ (“SRE”) practices.
- Site Reliability Engineering, How Google Runs Production Systems, Ben Treynor Sloss, Vice President, Google Engineering, founder of Google SRE, https://landing.google.com/sre/
James Wirth is a member of the emerging technologies team within VMware Professional Services and focuses on Site Reliability Engineering, Multi-Cloud architectures and new and emerging technologies. He is a proven cloud computing and virtualization industry veteran with over 10 years’ experience leading customers through their cloud computing journey.



