
Maintaining availability of data and the applications that produce or consume that data might be the most important responsibility of data center administrators. Capabilities like high performance or special data services mean very little if the applications and the data they produce or consume is not readily available. Ensuring availability is a complex topic, as application availability and data availability use different techniques to achieve the desired result. Sometimes availability requirements are achieved using infrastructure-level mechanisms, while others may use application-centric solutions. What is best for your environment depends heavily on the requirements and capabilities of your infrastructure.
While VMware Cloud Foundation (VCF) can deliver high levels of data and application availability in a simple way, this post will look at the differences in providing high availability of applications and data using application-level technologies versus inherent infrastructure-level technologies in VCF. We will also look at how VMware Data Services Manager (DSM) can play a part in simplifying some of these decisions.
Accommodating for Failure
Protecting applications and data require an understanding of what typical failures look like, and what a system can do to accommodate for failure. For example, failures in a physical infrastructure may include:
- Centralized storage solutions like storage arrays
- Discrete storage devices in distributed solutions
- Hosts
- Network interface cards (NICs)
- Network switching fabrics, causing partitions
- Site/zone-level failures
Failures like these noted above could impact the data, the applications, or both. Failures come in a variety of ways, with some explicitly identified, while others only through absence. Some failures are temporary, while others permanent. Solutions must be sophisticated enough to automatically handle these failure and recovery scenarios.
Availability and Recovery of Applications and Data
The availability of applications and their data sets are seemingly intuitive, but warrant a brief explanation.
- Application availability. This refers to the state of the application, such as a database application or a web application. Whether it be an application installed in a VM, or running as a container, this application is preconfigured to run and interact with the data in a specific way. Some applications have the ability to work with more than one application instance to improve availability in the event of an outage, and use its own synchronous replication techniques to ensure the data is stored in more than one location. Technologies like vSphere HA can make an application and its data highly available by restarting the VM on another host in a vSphere cluster in the event of a failure.
- Data availability. This refers to availability of data – accessed by an application or users – at any time needed, even in the event of a failure. Highly available data uses sophisticated techniques to ensure the data is stored in a resilient way – across multiple locations – whatever the boundary of failure might be, such as a device, a host, a storage array, or a site.
- Data reliability. Storing data in more than one location is not enough. It must be synchronously written to more than one location, and stored consistently across those locations to ensure that in the event of a failure, the data retrieved from one location is the same as the data retrieved from another location. Enterprise storage systems use a common set of principles — atomicity, consistency, isolation, durability (ACID), and implement protocols to achieve data reliability.
The concepts described above introduce two other terms that help quantify the recovery capabilities in the event of a failure. These terms when used in conversation may reflect the requirements of a customer, or the capability of a system.
- Recovery Point Objective (RPO). This is an expression of the frequency that data is protected in a resilient way. An RPO of 0 (RPO=0) means that the system always commits writes in a synchronized, consistent state. As noted later in this post, some solutions are better than others at delivering a true RPO=0.
- Recovery Time Objective (RTO). This is an expression of the maximum amount of time it takes to recover the systems and/or data into an operational state. An RTO of 10 minutes (RTO=10m) means that the failed systems will be back online in no longer than 10 minutes. RTO times may refer to regaining data availability or the combination of data and application availability.
The Evolution of Options in High Availability
How data and application availability is achieved has evolved over the years as technology advanced and requirements have increased. Some applications like Microsoft SQL Server, MySQL, PostgreSQL, and other applications have their own replication capabilities built into their applications that help provide redundancy of the data and the application state. Virtualization, when paired with some form of shared storage offers simple ways of providing high availability to applications and the data they host.
Depending on your requirements, either one, or a combination of the two can be viable options in your private cloud. Let’s clarify how each approach provides levels of high availability.
- Application-Level High Availability for Apps and Data. This approach relies on more than one application instance running in two different locations. Synchronous, resilient storage and failover capabilities are provided by the application itself to ensure high availability of the application, and the data that it houses.
- Infrastructure-Level High Availability for Apps and Data. This approach relies on vSphere HA to restart a single application instance to somewhere else in the cluster. Synchronous, resilient storage is provided by VMware vSAN (in the context of this comparison). This combination provides high availability of the application instance, and the data that it houses.
While both approaches achieve a similar objective, there can be some tradeoffs to keep in mind. Let’s look at two simple examples to understand the differences a bit further.
In the examples below, we assume the data needs to persist in multiple locations, such as a site or a zone. This will provide the level of data availability required in the event of a site or zone failure. We will also assume that the application has the ability to run in the same respective locations. Both achieve automatic failover of the application, and a recovery point objective (RPO=0) since they use technologies to synchronously write the data to more than one location.
Application-Level High Availability for Apps and Data
Application-level high availability like MS SQL always on availability groups (AGs) uses two or more database applications in a running state, with one additional location to help determine quorum under various potential failure conditions.
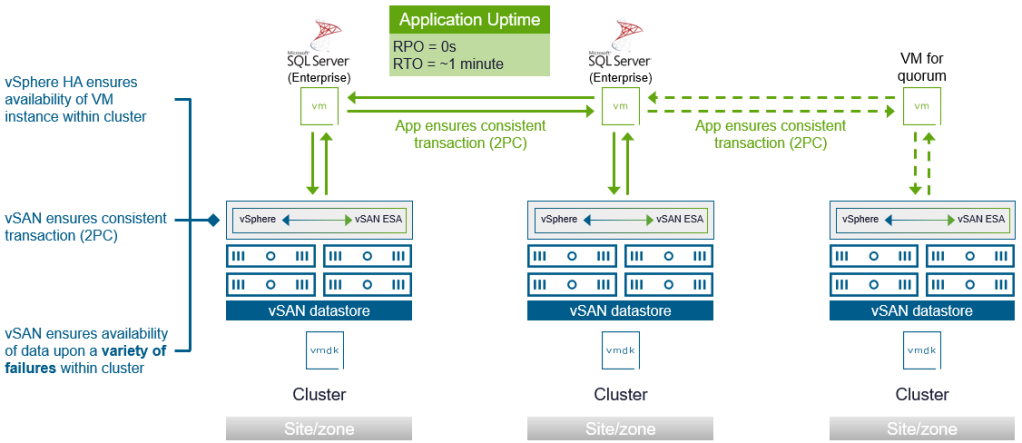
Figure 1. Using application-level resilience with SQL Server across multiple sites/zones
This approach relies entirely on technology within the application to synchronously replicate the data to another location, and to provide the failover mechanism for its application state.
Infrastructure-Level High Availability for Apps and Data
Infrastructure-level high availability would use a database application running on a single VM. vSphere HA provides the automated recovery of the application accessing the data, while vSAN ensures data reliability and availability against a range of infrastructure failure conditions. vSAN can tolerate failures of discrete storage devices, network interface cards (NICs), network switches, hosts, and even geographic sites or zones, which is defined as a “fault domain.” In the example below, a vSAN cluster is stretched across two sites to ensure the data is stored across the sites resiliently. vSAN stretched clusters also use a third location running a small virtual witness host appliance to help determine quorum under various potential failure conditions.
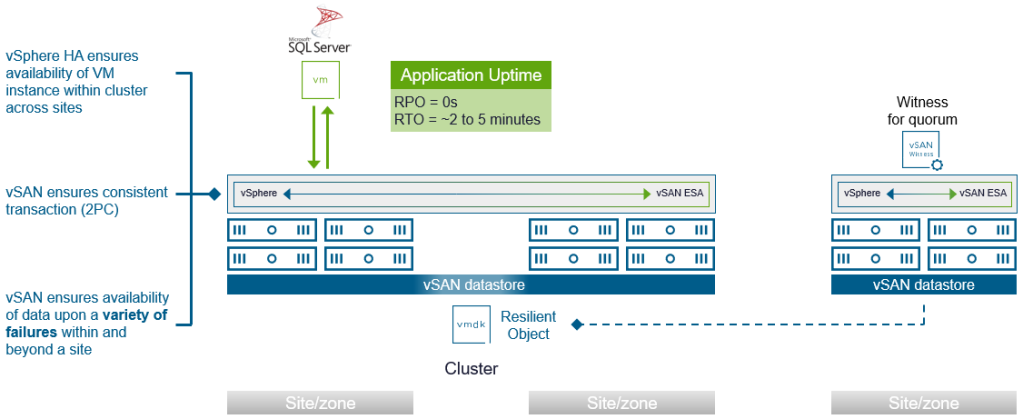
Figure 2. Using infrastructure-level resilience with SQL Server across multiple sites/zones
One of the most compelling aspects of infrastructure-level availability is that with VCF it is native to the platform. vSAN is built right into the hypervisor, and delivers data resilience to meet your requirements all by setting a simple storage policy. Application instances are made highly available courtesy of the venerable vSphere HA, allowing VMs to restart anywhere within the vSphere cluster. This approach also works well when database applications are provisioned and managed in your VCF instance using DSM.
Different Approaches to Achieve Data Consistency
While both approaches can provide a recovery point objective (RPO) of zero (RPO=0) through synchronous replication capabilities, how they achieve it is a little different. Both approaches use special protocols to help achieve consistency of data written to multiple locations — which is not as easy as it sounds. With MS SQL Server AGs, it occurs through the application, while vSAN can deliver synchronous writes inherently as a part of its distributed architecture that was designed for high levels of resilience.

Figure 3. Comparing how SQL and vSAN preserve correctness of synchronous transactions
With application-level data replication, this high-level of availability is limited to that specific application and its data. But these capabilities at the application level are not created equally. For example, while MS SQL Server AGs may offer an RPO=0 under a variety of failure scenarios, MYSQL InnoDB clusters use an approach that can only provide RPO=0 under a single node failure. While the data will remain consistent, it may lose the most recently committed transactions during some failure scenarios, such as a total cluster failure or unplanned restart. This means that under specific circumstances, it cannot deliver an RPO=0.
With vSAN in VCF, high-availability is a ubiquitous characteristic that applies to all workloads that are writing data to a vSAN datastore.
Differences in Recovery Time Objectives (RTO)
One of the primary reasons behind the different RTO capabilities of application-level availability versus infrastructure-level availability is how the application regains its operational state after a failure.
For example, some applications like SQL server AGs use licensed “standby” VMs on your infrastructure to allow another application state to be used in the event of a failover. While this may result in a low RTO, it does result in higher costs from additional licensing and resources consumed. Application-level availability is a unique point solution that requires expertise with that application to achieve the desired result. Although, DSM can remove much of the complexity from these types of features, since it automates this and relieves much of the burden from this type of administration.
Infrastructure-level availability is different. Using virtualization constructs like vSphere High Availability (HA), it ensures that a single application can be restarted in another location in the event of an outage of the VM. The restart of the VM and its application, and the log recovery process tends to take longer than the standby VM approach used with application-level availability.
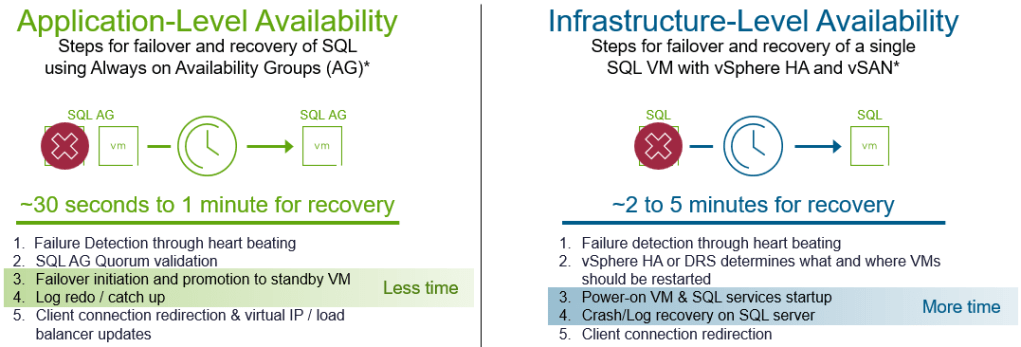
Figure 4. Understanding the differences in RTO between the two approaches to availability
The times shown above are estimates. Actual recovery times will vary greatly depending the conditions of the environment, the size and activity of the MS SQL environment.
Which One is Right for You?
The best choice for you depends on your requirements, constraints, and how the option fits into your organization. For example:
- Availability Requirements. Perhaps your requirements dictate that the application and its data must be available beyond a given boundary of failure, such as a site or a zone. This will help you determine if site or zone level availability is even needed.
- RTO Requirements. If you have an RTO requirement that allows for a 2 to 5 minute recovery, then infrastructure-level availability is a terrific option, because it is built into the platform, and works across all of your workloads. If you have a requirement for a few discrete applications that need a lower RTO, and you do not mind the extra costs and complexity associated with the feature, then perhaps it is a good option for you.
- Technical constraints. Your organization may have initiatives to simplify toolsets and workflows, which may inhibit your ability or desire to use another technology such as application-level availability. Typically, common tools that apply to all systems are preferred over point solutions. Other technical constraints such as latency between sites or zones may be prohibitive for either type of approach.
- Financial constraints. You may be under financial pressure to minimize ongoing software costs that would incur through more licensing, or higher licensing levels to achieve application-level availability. This may bode in favor of using solutions that you already have.
It is possible to use a combination of both technologies. For example, Figure 1 at the beginning of this post shows how application-level availability is used across sites or zones using MS SQL AGs, but infrastructure-level availability is provided within each site or zone courtesy of vSAN and vSphere HA. This particular example could also be a good use case for DSM. Instead of running and managing discrete VMs, you would rely on DSM-deployed databases for application-level availability across sites or zones. It would deliver low RTOs while removing administrative complexity of application-level replication, while letting vSAN handle data availability within sites or zones.
Summary
High levels of data and application availability can be achieved in a variety of ways. If you are running VMware Cloud Foundation, you can achieve this using software you already own. For more information on data resilience capabilities of vSAN, see the vSAN Availability Technologies paper on the VMware Resource Center.
Special thanks to Christos Karamanolis and Christian Dickmann for their contributions to this post.
Discover more from VMware Cloud Foundation (VCF) Blog
Subscribe to get the latest posts sent to your email.





