

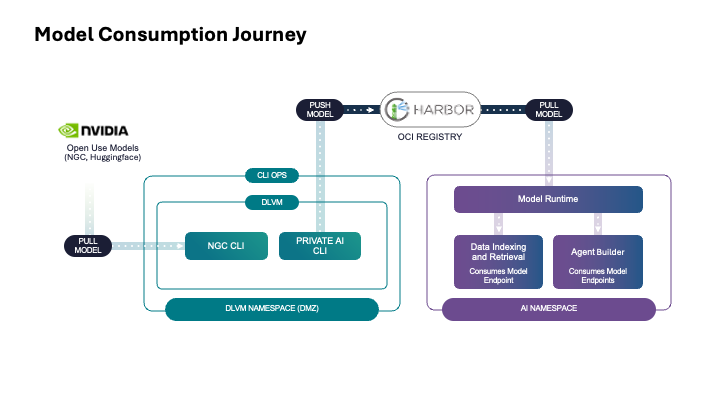
Model Onboarding
A data scientist or LLM Ops engineer, supported with suitable infrastructure by the Operations people, chooses a model from the expanding set of models that are available in the public domain (e.g. the Llama 3 set of models from Meta, or an optimized model from the NVIDIA GPU Cloud). With this choice comes a need to test the model in a safe environment with specific company data, for its accuracy of answers, bias handling, vulnerabilities and performance characteristics among other considerations. This model choice and testing is needed for both for “completion” models like Llama 70B and for “embedding” models like BAAI BGE-M3. This testing is best done in an AI Workstation configured in the VMware Private AI Foundation tooling. A devops person or a data scientist provisions the “AI Workstation” tile seen below in VCF Automation and this results in a deep learning VM (DLVM) being created. All the technical details of doing that DLVM provisioning are handled by VCF Automation. The “AI Workstation” catalog item is seen on the far right in the VCF Automation – Catalog below. This is one example of the set of items that can be made available for deployment in VCF Automation.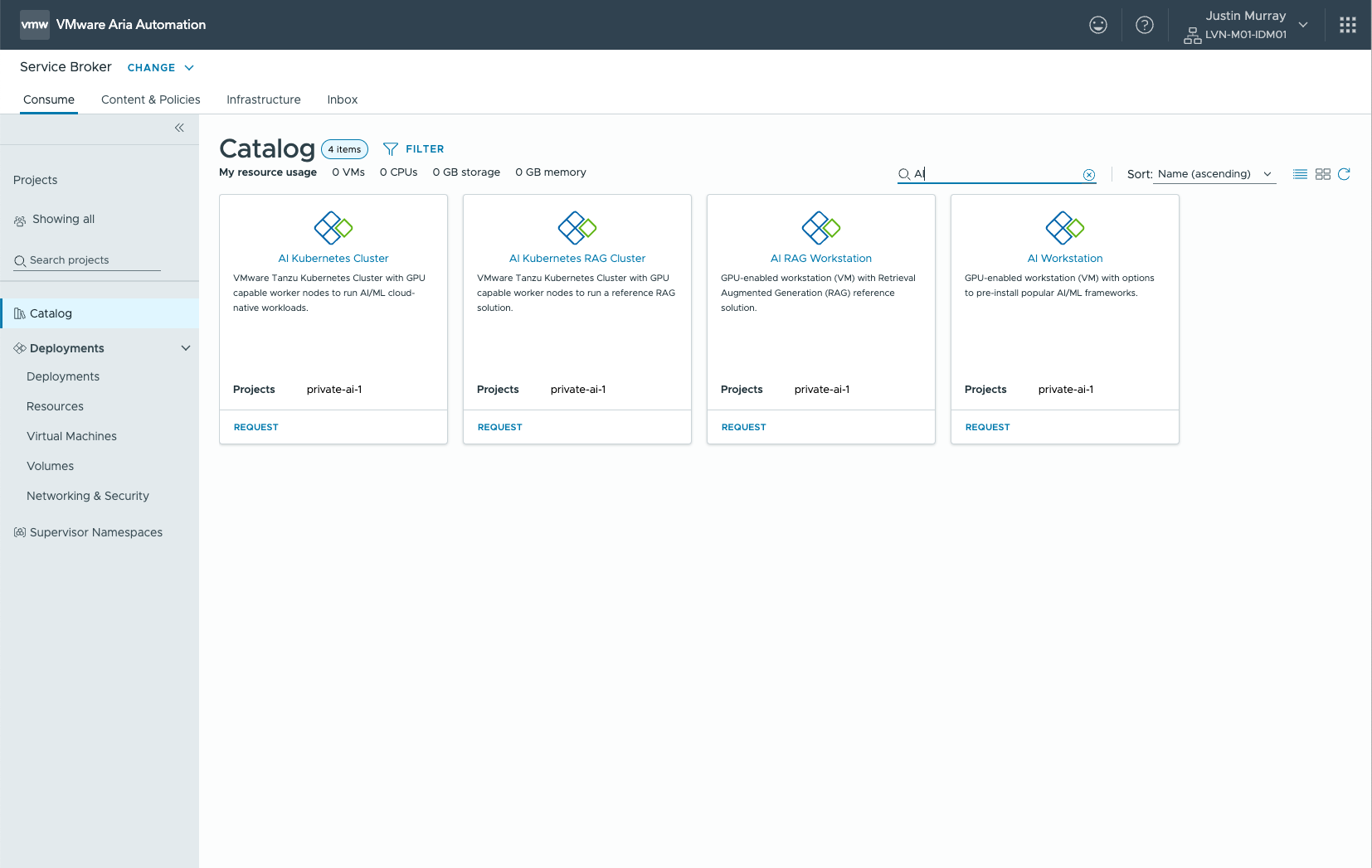
Model Store
The data scientist decides to retain and store the tested model for further application use in their enterprise. This is done using a model store/repository that is implemented on an OCI repository called Harbor. The LLM Ops person provisions this model store and provides write access to the data scientist or other users for certain named projects and repositories within the model gallery. The newly tested model is pushed up from the DLVM to the Harbor-based Model Gallery using a VMware Private AI-specific command line interface called “pais”. That “pais” CLI comes as part of the deep learning VM.Model Endpoints via the Model Runtime Service
The data scientist, application developer or LLM testing engineer requires access to one or more models to serve their application. A completions model and an embedding model are shown as two examples here. Often, the requirement is for a model setup that provides answers to users’ questions delivered in a chatbot style. For building and testing this application, they need an access point to the model (simply put, an access point to the model) and a means of sending the model some input data and receiving responses. For this the user creates an end-point that is supported by the model runtime service, that then allows them to use the model. Below you see a model endpoint being created using a reference to the model itself in the Harbor model gallery. This reference is seen in the Model URL field given below.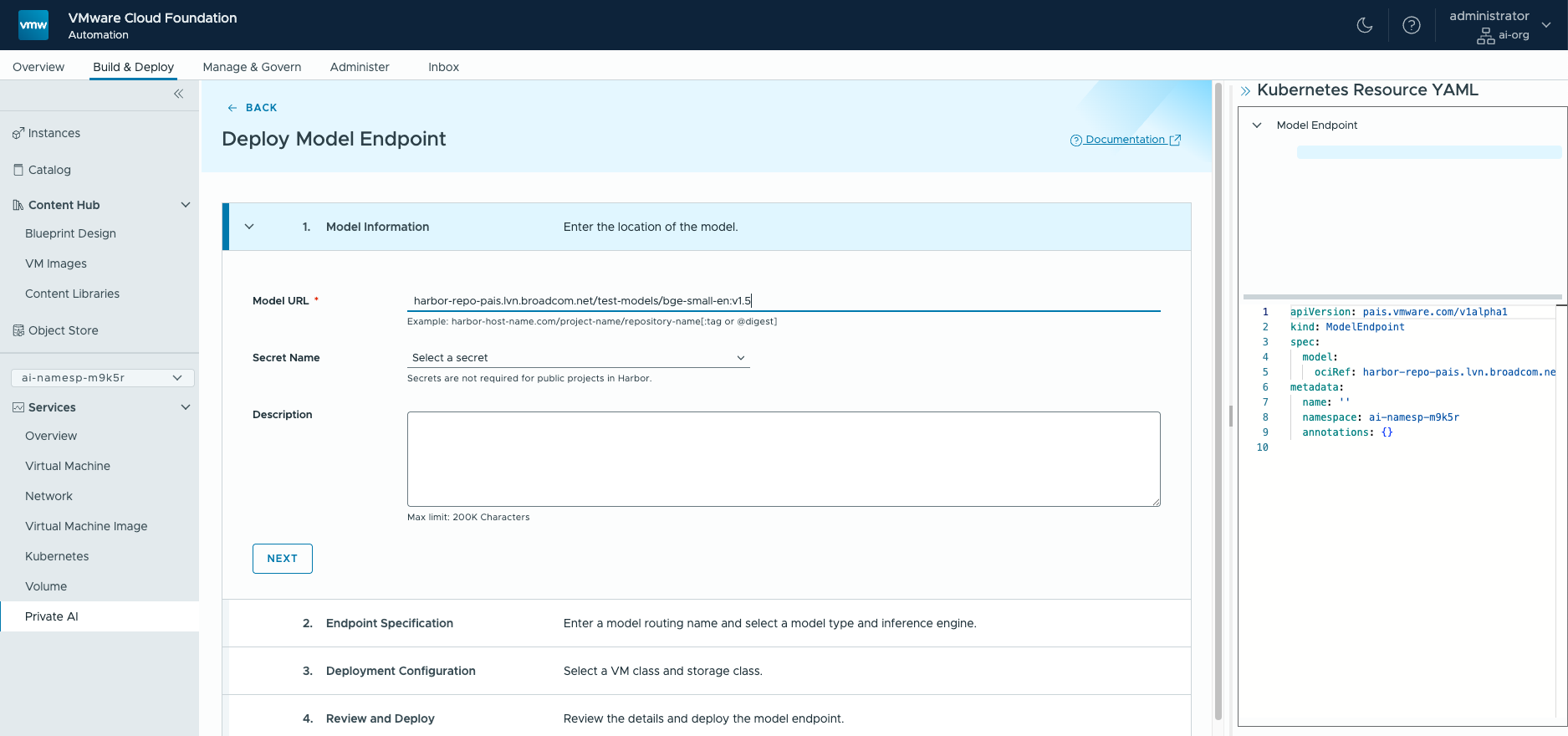 We deploy a model endpoint for each model to be used in our AI applications. Multiple model end-points are supported concurrently by the VMware Private AI Model Runtime service. Each model is loaded into the chosen inference engine such that it provides a long-running service to the applications that need it. The user chooses the appropriate inference engine for their model from a supplied set. This inference engine is typically vLLM for a completions model or Infinity for an embeddings model. Here is a view of that choice of “Model Type” and “Engine”.
We deploy a model endpoint for each model to be used in our AI applications. Multiple model end-points are supported concurrently by the VMware Private AI Model Runtime service. Each model is loaded into the chosen inference engine such that it provides a long-running service to the applications that need it. The user chooses the appropriate inference engine for their model from a supplied set. This inference engine is typically vLLM for a completions model or Infinity for an embeddings model. Here is a view of that choice of “Model Type” and “Engine”.
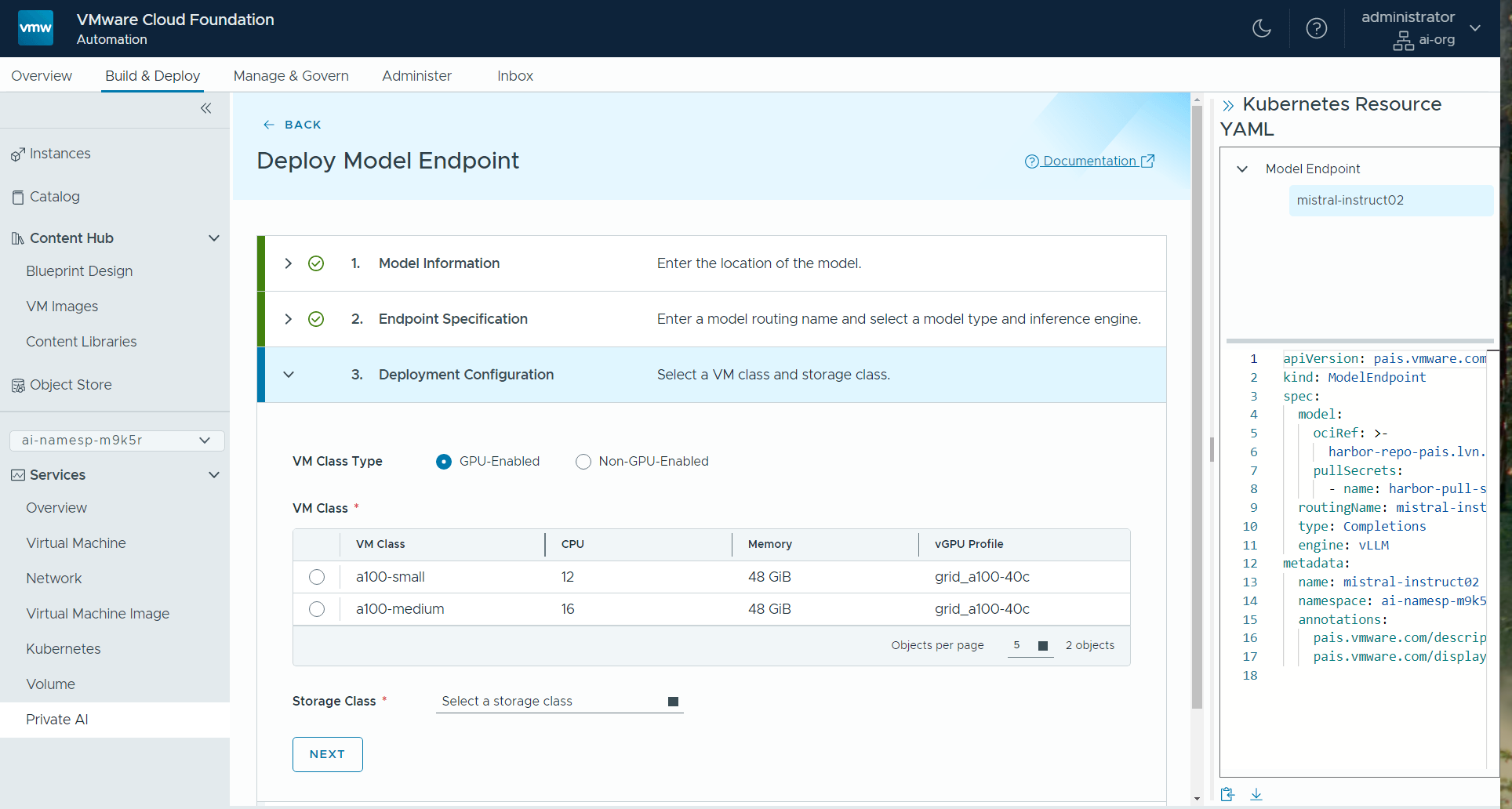
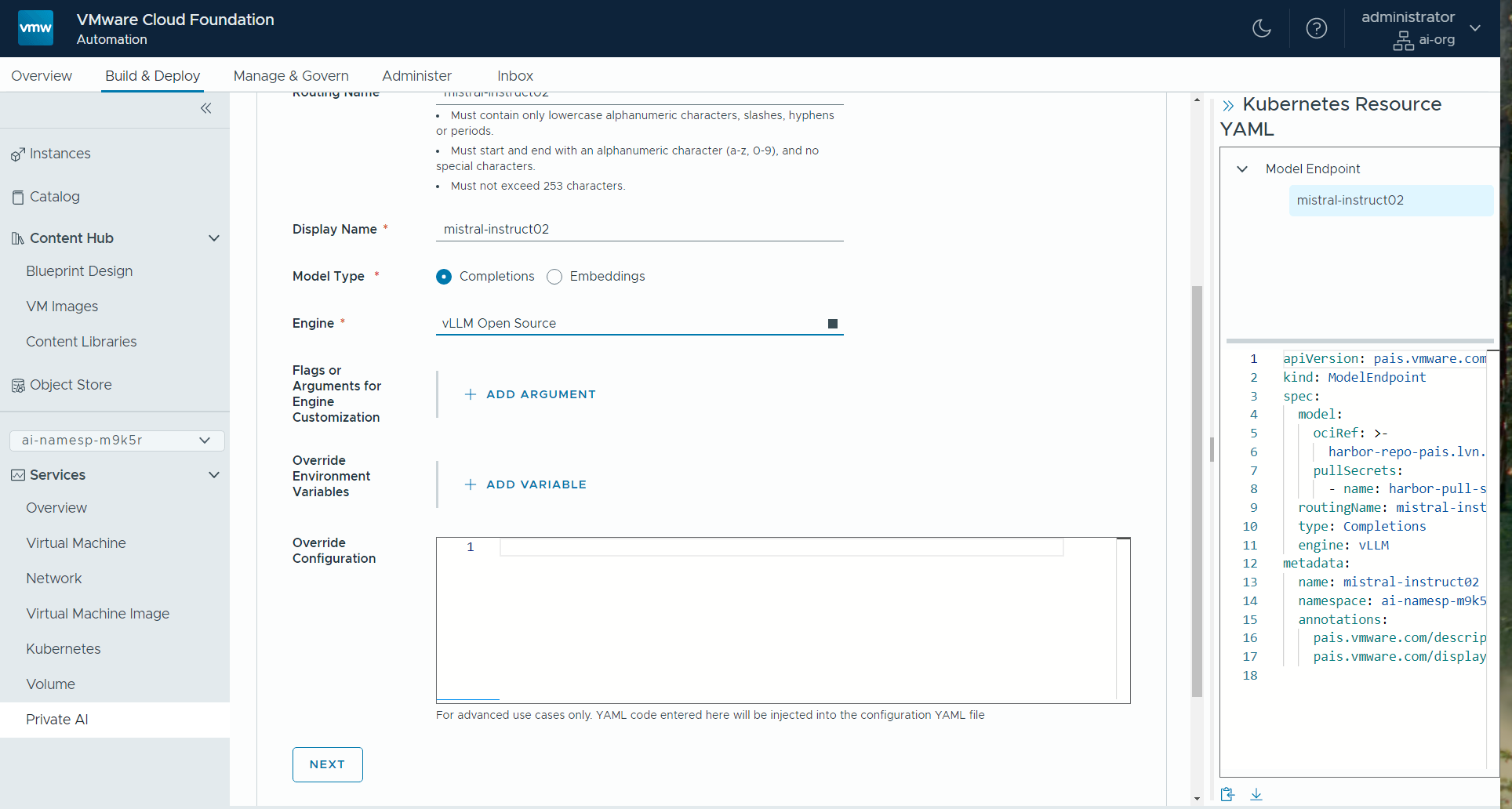 The deployer also chooses the appropriate GPU allocation, if access to a GPU is required for the model, using the concept of a VM class as seen below. These VM classes will be pre-built by the system administrator to allow certain GPU uses. Some VM class examples apply for GPU situations and others apply in non-GPU cases (the latter applies to smaller models, mainly).
The deployer also chooses the appropriate GPU allocation, if access to a GPU is required for the model, using the concept of a VM class as seen below. These VM classes will be pre-built by the system administrator to allow certain GPU uses. Some VM class examples apply for GPU situations and others apply in non-GPU cases (the latter applies to smaller models, mainly).
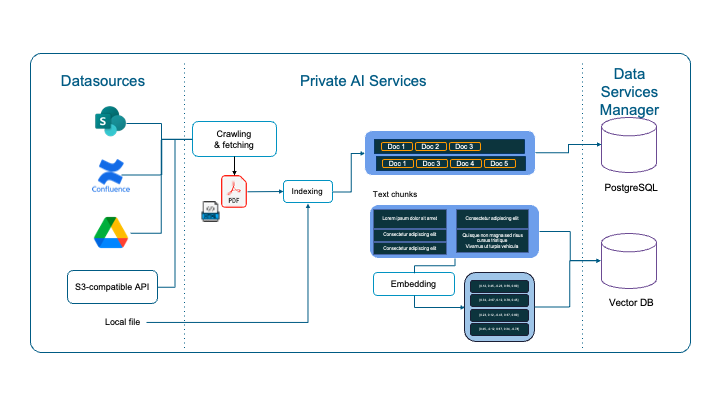
 The model endpoint is supported initially by a node in a pre-built VMware Kubernetes Service cluster. There can be multiple nodes in a nodepool dedicated to that endpoint to give scale-out ability to the model. Within the Kubernetes node, a pod containing an inference engine such as vLLM or Infinity is running with the appropriate set of GPU resources for use by the model. This means that a Kubernetes nodepool supports the end-point, giving resiliency. Importantly, the models can be accessed through an API gateway component of the Model Runtime.
The API Gateway provides authentication and authorization of user requests incoming to a model and helps with load balancing of requests across sets of models.
The model endpoint is supported initially by a node in a pre-built VMware Kubernetes Service cluster. There can be multiple nodes in a nodepool dedicated to that endpoint to give scale-out ability to the model. Within the Kubernetes node, a pod containing an inference engine such as vLLM or Infinity is running with the appropriate set of GPU resources for use by the model. This means that a Kubernetes nodepool supports the end-point, giving resiliency. Importantly, the models can be accessed through an API gateway component of the Model Runtime.
The API Gateway provides authentication and authorization of user requests incoming to a model and helps with load balancing of requests across sets of models.
Data Indexing and Retrieval Service
Private company data will be used by the completions model we deployed above to augment its behavior when answering an end-user’s question. There is a separate workstream, therefore, to organize that private data for use. The LLM Ops engineer or data scientist provides access to the data sources that are needed to be supplied to the model in a RAG design. This means they create data source objects, using the Data Indexing and Retrieval service in PAIS, to refer to the various data repositories for the private data.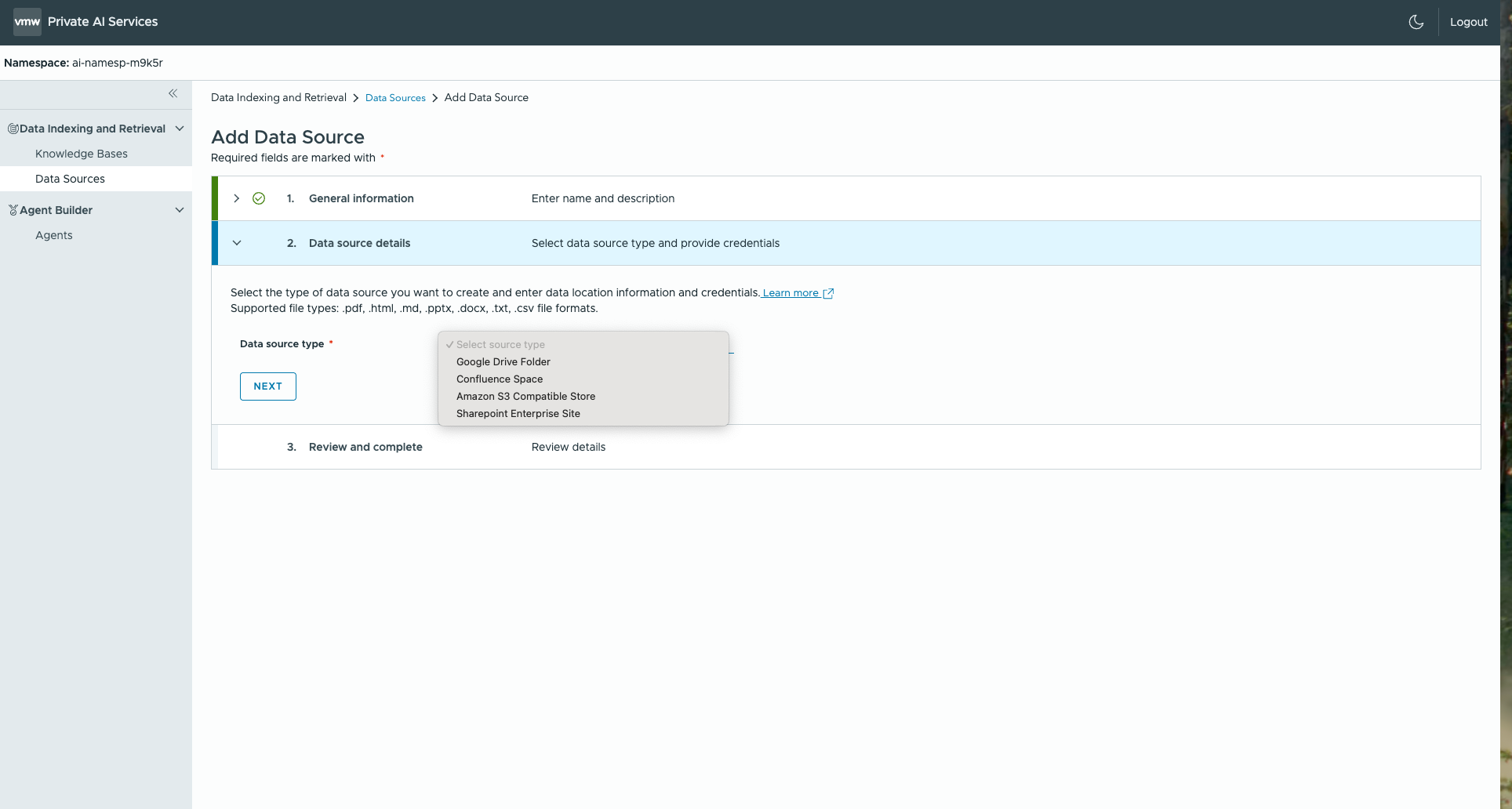 Those data sources may be references to Google Drive directories, Confluence pages, Sharepoint directories or S3 sources. These data sources are collected together in a Knowledge Base for indexing to take place. The documents within a Knowledge Base are divided up (chunked) during the indexing process into smaller parts. They are then converted to embeddings (numeric representations) and indexed before they are loaded into a vector database for later retrieval. The data used in indexing a knowledge base may come from many sources, including local files.
Those data sources may be references to Google Drive directories, Confluence pages, Sharepoint directories or S3 sources. These data sources are collected together in a Knowledge Base for indexing to take place. The documents within a Knowledge Base are divided up (chunked) during the indexing process into smaller parts. They are then converted to embeddings (numeric representations) and indexed before they are loaded into a vector database for later retrieval. The data used in indexing a knowledge base may come from many sources, including local files.
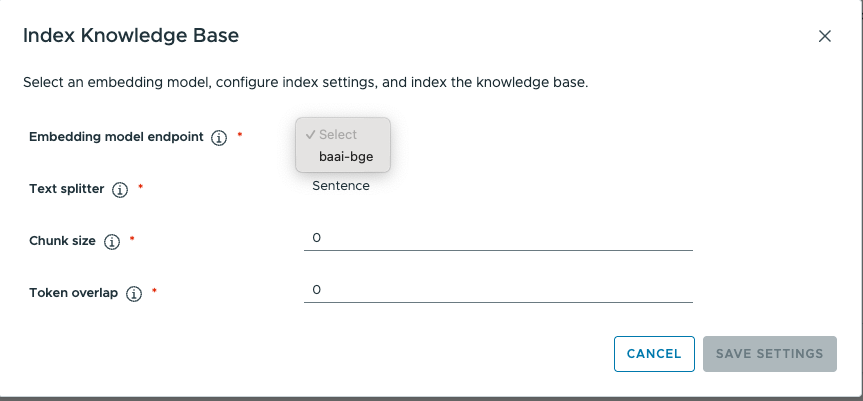
 The data scientist or LLM Ops engineer decides how to create embeddings and how indexing is done for the data sources that are in a Knowledge Base. This indexing process involves choosing an Embedding Model from a previously validated set. That embeddings model is also accessed via its entry in the Model Store and runs under control of the Model Runtime. Here is one example of choosing an embedding model endpoint. This embedding model endpoint was constructed earlier from a model store entry.
The data scientist or LLM Ops engineer decides how to create embeddings and how indexing is done for the data sources that are in a Knowledge Base. This indexing process involves choosing an Embedding Model from a previously validated set. That embeddings model is also accessed via its entry in the Model Store and runs under control of the Model Runtime. Here is one example of choosing an embedding model endpoint. This embedding model endpoint was constructed earlier from a model store entry.
 File: Shared Drives/Private AI TMM Material/__Slides Latest/__VCF9.0 PAIS/2 Data Indexing and Retrieval/Add-Data-Source-Choice
This work involves some understanding of the data structures present in the input data and the needs of the application, such that the most appropriate chunk size and indexing is used. For example, a text corpus may be chunked into paragraphs or sentences, and separate chunking and indexing is done for the tables, charts and diagrams within the document.
As part of the indexing work on the knowledge base, with its collection of data sources, the resulting text embeddings and indices are stored in the vector database. When a query comes in from an end user, an Agent decides where that query should go first, which we will see next in the Agent Builder steps.
File: Shared Drives/Private AI TMM Material/__Slides Latest/__VCF9.0 PAIS/2 Data Indexing and Retrieval/Add-Data-Source-Choice
This work involves some understanding of the data structures present in the input data and the needs of the application, such that the most appropriate chunk size and indexing is used. For example, a text corpus may be chunked into paragraphs or sentences, and separate chunking and indexing is done for the tables, charts and diagrams within the document.
As part of the indexing work on the knowledge base, with its collection of data sources, the resulting text embeddings and indices are stored in the vector database. When a query comes in from an end user, an Agent decides where that query should go first, which we will see next in the Agent Builder steps.
Agent Builder – Create a Component of a RAG Application
One of the most popular design pattems for AI applications is the Retrieval Augmented Generation (RAG) approach. In a RAG design, the user’s question, entered in a Chatbot UI, is itself first converted to embeddings form by the same embeddings model thatwe used earlier for storing the data. That converted question is sent as a query to the vector database to find similar entries or semantically meaningful entries in the vector database that match the query contents. The application developer makes use of the Private AI Agent Builder to combine the knowledge base with the completion model endpoint to design their (RAG) application. The embedding model is used to first convert the user’s question to embeddings form. Then that query is sent as a request to the vector database to find similar entries or semantically meaningful entries that match the query. An example interaction supported by the Agent Builder is shown below, with “Model endpoint” field showing the completions model and the knowledge base being used to access the private data from the vector database. This is test environment for the model and data indexing functionality, so that developers can now use this setup to create a customer service application.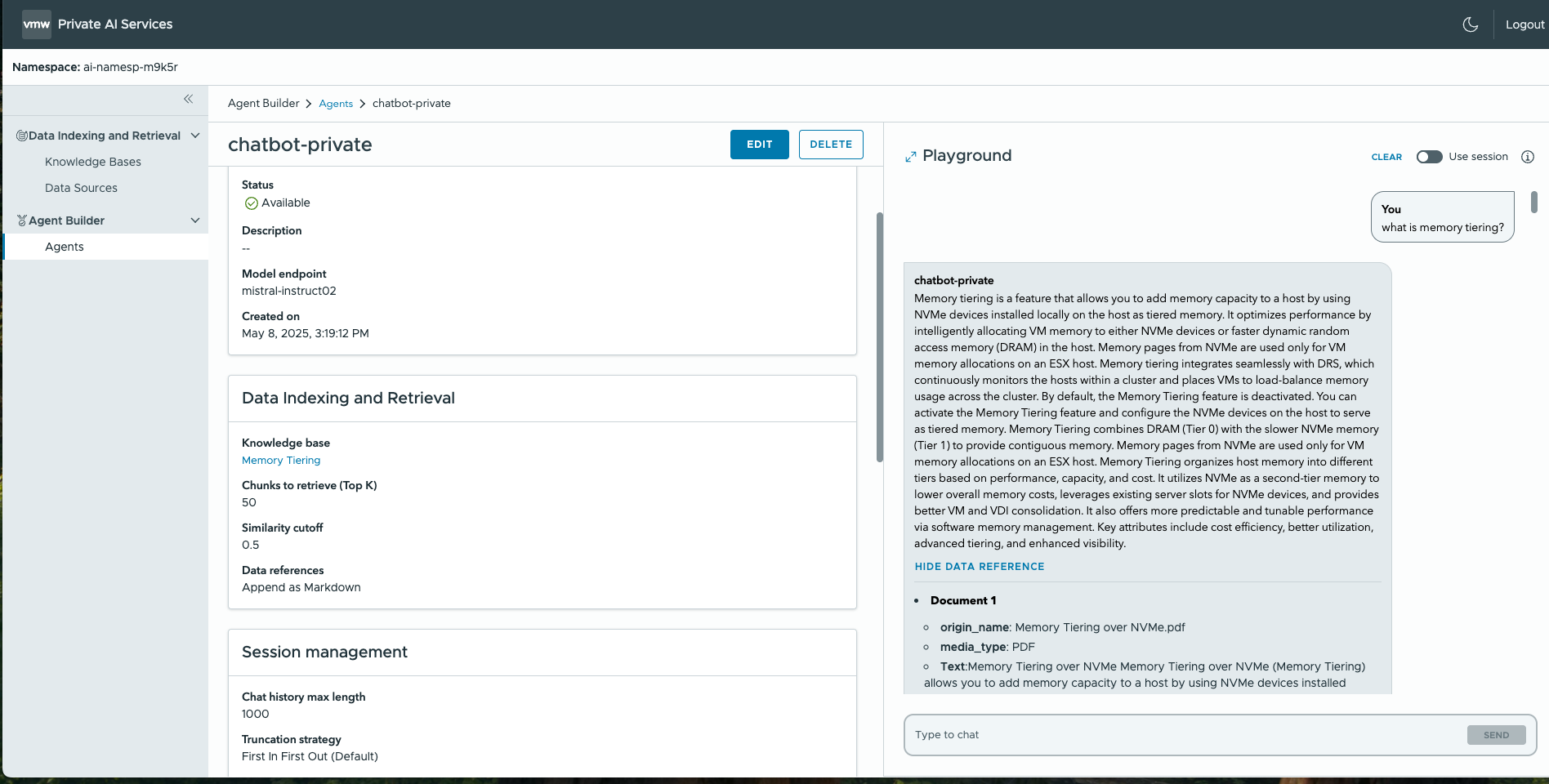 The end user can test this new agent-based application by issuing various questions to it. That allows them to judge the quality, accuracy and speed of the responses – all key things for the data scientist to concern themselves with. This testing process can be automated to ensure high quality of the model and data, using a CI/CD process. The user can further refine the activity in the agent by giving it explicit instructions on how it should behave.
When the time comes to upgrade the model in production with a newer version, a staged roll-out of the new model is achieved without taking the consuming applications out of service. Updates to the data in the vector database can be done through the Knowledge Base re-indexing process on a regular basis also.
The end user can test this new agent-based application by issuing various questions to it. That allows them to judge the quality, accuracy and speed of the responses – all key things for the data scientist to concern themselves with. This testing process can be automated to ensure high quality of the model and data, using a CI/CD process. The user can further refine the activity in the agent by giving it explicit instructions on how it should behave.
When the time comes to upgrade the model in production with a newer version, a staged roll-out of the new model is achieved without taking the consuming applications out of service. Updates to the data in the vector database can be done through the Knowledge Base re-indexing process on a regular basis also.
Summary of the Private AI Services in VCF 9.0
In this article, we provide an outline of the new Private AI Services functionality in VCF 9.0. This set of tools is designed to make AI applications based on models and data sources much simpler for the user. The new Private AI Services (within VMware Private AI Foundation with NVIDIA) include -Model Store – for maintaining control over models and their versions – a step towards the goal of model governance; -Model Endpoints – based on a choice of model inference servers, such as vLLM, Infinity, etc. A model endpoint provides a URL and an API for accessing a model from a client program. -Data Indexing and Retrieval – a process and tools for organizing data (chunking/creating embeddings, indexing) that is based on using an embedding model. The embedding model is run on a model runtime with an endpoint of its own. Within this area, we define a Knowledge Base as an object that encapsulates a set of data stores that can be indexed for access in queries -Agent Builder – a tool that makes use of indexed Knowledge Bases and Model Endpoints to build an application Taken together, these services provide both the operations and data science staff who want to deploy private AI, on-premises, with a highly productive experience in organizing models and data for new AI applications. The set of services described here is integrated with VMware Cloud Foundation and VMware Private AI Foundation with NVIDIA to provide a full-featured platform for the next generation of AI applications. *** Ready to get hands-on with VMware Cloud Foundation 9.0? Dive into the newest features in a live environment with Hands-on Labs that cover platform fundamentals, automation workflows, operational best practices, and the latest vSphere functionality for VCF 9.0.Discover more from VMware Cloud Foundation (VCF) Blog
Subscribe to get the latest posts sent to your email.



