


The release of Kubernetes 1.36 includes dozens of enhancements, updates, and deprecations. But for most enterprise teams, the details of each individual feature aren’t the most important part. What matters more is the direction these changes point to and what that means for Kubernetes’s evolution as a platform.
Kubernetes Is Becoming the Control Plane for AI Infrastructure
One of the clearest signals in 1.36 is the continued investment in how Kubernetes handles specialized hardware, particularly GPUs.
Work like Dynamic Resource Allocation (DRA) is about more than improving scheduling; it reflects a broader shift toward standardizing how Kubernetes interacts with high-value, constrained resources.
A key advancement in 1.36 is the introduction of Structured Parameters for DRA. Previously, requesting complex resources often required opaque, vendor-specific blobs that were difficult for the scheduler to optimize. By moving toward a more structured approach, Kubernetes is making it easier for the scheduler to “understand” the specific requirements of a GPU or AI accelerator—drastically reducing the complexity of multi-node AI deployments.
This shift matters because AI workloads behave very differently from traditional applications. Unlike standard web services that follow predictable, request-response patterns, AI workloads are often probabilistic and computationally “bursty.” They involve different sets of inputs and outputs that require massive, parallel infrastructure demands; failing to place a pod correctly doesn’t just cause a slow response; it can stall an entire multi-node training job.
Furthermore, AI introduces a much higher dependency on data gravity. These workloads require high-speed access to massive datasets and constant updates to those sources, making data locality and network throughput just as critical as raw CPU. Finally, while a traditional app might stay “static” once deployed, AI models require constant monitoring for drift and frequent retraining loops. This means the platform must treat the workload not as a one-time deployment, but as a continuous, resource-heavy lifecycle that demands far tighter control over performance and isolation.
This transition is meaningful because it introduces new complexity. Questions around GPU sharing, workload placement, and consistency across environments don’t have simple answers. They extend beyond Kubernetes itself and into the design of the platform that sits around it.
This is where we’re seeing increased focus on how platforms integrate infrastructure-level controls with Kubernetes-native scheduling. In environments like VMware Cloud Foundation (VCF) with VMware vSphere Kubernetes Service (VKS), that means aligning upstream capabilities like DRA with underlying placement, isolation, and lifecycle controls so that these workloads can be managed consistently, not just scheduled successfully.
And as Kubernetes takes on a more central role in how complex workloads are run, it also raises the stakes for how those environments are configured and secured.
Security Is No Longer a Choice
Kubernetes continues tightening security expectations, reinforcing that flexibility without guardrails is no longer acceptable for production environments. The defaults are becoming safer, the tolerances for misconfiguration are shrinking, and the expectation is that clusters are secure by design and not by afterthought.
We see this clearly in 1.36 with the final removal of the legacy AppArmor annotations in favor of the formal appArmorProfile field. It’s a move away from “hacky” metadata toward first-class API support. Similarly, the graduation of User Namespaces to a more stable state provides a critical layer of isolation, ensuring that even if a container is compromised, the “root” inside the container doesn’t translate to “root” on the host.
For enterprise teams, this creates a familiar tension. Kubernetes is still incredibly flexible, but the cost of that flexibility is increasing. The more configurable a system is, the easier it is to drift into insecure states unless those configurations are actively managed.
This is why security is increasingly shifting out of “cluster setup” and into “platform responsibility.”
We have found that implementing these upstream security standards within a platform such as VKS reduces variability. Rather than relying on teams to configure security correctly each time, platforms like VKS focus on embedding those expectations into how clusters are provisioned and operated from the start to reduce variability and improve overall posture.
And as these expectations become more embedded into Kubernetes itself, they also increase the operational burden of keeping environments aligned with upstream changes.
Release Velocity Is Becoming an Operational Problem
Kubernetes continues to move quickly and that’s part of what makes the ecosystem so powerful. But it also introduces challenges for enterprise teams.
Each release brings new capabilities, evolving APIs, and the deprecation of older behaviors. None of this is surprising in isolation, but together, it creates pressure for teams trying to maintain stability over time.
At this point, keeping up with Kubernetes is no longer just about upgrading clusters. It’s about managing lifecycle complexity, deciding when to adopt new versions, understanding how changes impact existing workloads, and avoiding disruption as the platform evolves.
For many organizations, this means finding ways to separate upstream innovation from production stability, rather than trying to keep them perfectly in sync.
This is where more flexible lifecycle models become critical. With VKS, for example, asynchronous releases and extended support options are designed to give teams control over how and when they adopt change. This allows them to stay aligned with upstream Kubernetes without being forced into constant upgrades.
This approach ultimately reinforces a broader shift: Kubernetes is no longer something you simply deploy, but it’s something that needs to be continuously managed as a platform.
Kubernetes Is Becoming a Platform
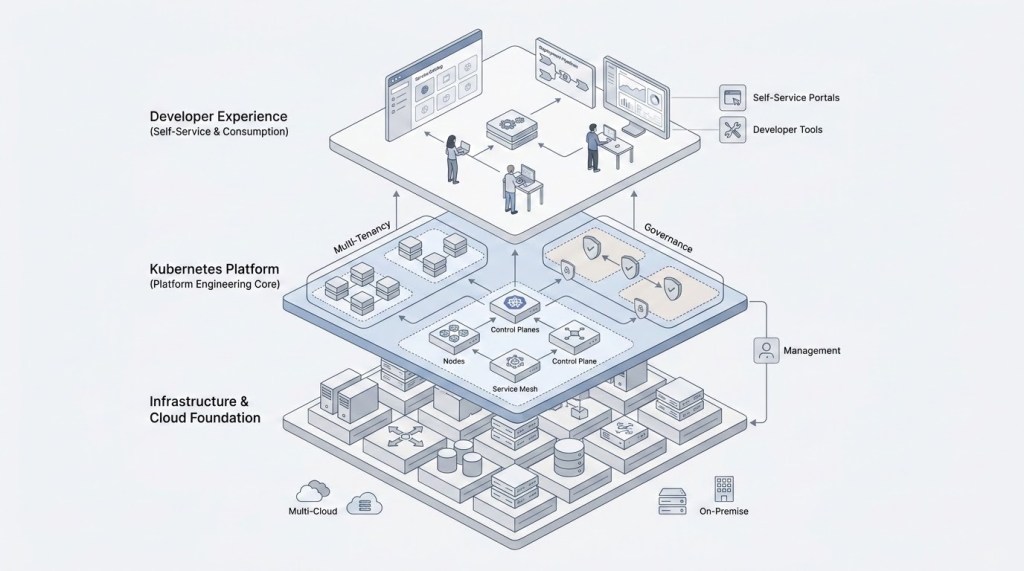
As shown in the platform architecture above, the shift isn’t just about the core, it’s about the integration of governance and developer self-service.
If you step back from the individual changes in 1.36, a broader pattern starts to emerge.
- Kubernetes is moving from a flexible framework toward more opinionated defaults for security and resource standards.
- Workloads are becoming more complex.
- Operational expectations are increasing.
- Margin for error is shrinking.
Taken together, this represents a shift from Kubernetes as flexible infrastructure to Kubernetes as a platform that needs to be designed, governed, and operated with intent.
This is where platform engineering comes into focus. In reality, running Kubernetes at scale requires more than just deploying clusters. It requires consistency, guardrails, and a clear model for how teams consume and operate the platform.
This is also the direction we’ve been focused on with VKS: treating Kubernetes not just as something to deploy, but as a service that can be consistently delivered, governed, and consumed across teams and environments.
The question then becomes how to structure it in a way that consistently meets these growing expectations.
What This Means in Practice
For enterprise teams, the implications are becoming clearer. The challenges highlighted in Kubernetes 1.36, whether around AI workloads, security expectations, or lifecycle management aren’t things that can be solved by Kubernetes alone. They require a broader platform approach that brings structure to how Kubernetes is deployed and operated.
That’s why so much focus has shifted toward building platforms that stay aligned upstream while also providing the stability, governance, and flexibility enterprises need in practice. The goal is to make Kubernetes usable in environments where consistency and control matter just as much as innovation.
Looking Ahead
The continued evolution of device management, the tightening of security expectations, and the sustained release velocity all point toward a future where Kubernetes is more powerful, but also more demanding to operate.
Teams building platforms today need to design systems that can keep up with where Kubernetes is headed, and do so in a way that balances innovation with the realities of enterprise operations.
References
Discover more from VMware Cloud Foundation (VCF) Blog
Subscribe to get the latest posts sent to your email.




